
Abstract
We study a low-rationality learning dynamics called probe and adjust. Our emphasis is on its properties in games of information transfer such as the Lewis signaling game or the Bala-Goyal network game. These games fall into the class of weakly better reply games, in which, starting from any action profile, there is a weakly better reply path to a strict Nash equilibrium. We prove that probe and adjust will be close to strict Nash equilibria in this class of games with arbitrarily high probability. In addition, we compare these asymptotic properties to short-run behavior.






Similar content being viewed by others

Notes
The learning part of fictitious play is equivalent to Carnap’s basic system of inductive logic.
The fictitious play process referred to here uses so-called smoothed best responses that result from perturbations of the payoffs.
This is meant to be informal but intuitively plausible. As one of the reviewers pointed out, this claim could be made more precise by studying the informational and computational requirements of probe and adjust and compare it to other learning rules such as reinforcement learning. This could be done, for instance, by considering finite state automata as in Binmore and Samuelson (1992).
We use actions instead of strategies since, strictly speaking, we consider infinitely repeated games where a strategy specifies a choice at each play of the stage game. Because we only study payoff-based methods that players use as they play a game repeatedly, what is adjusted are the strategies of the stage game, a.k.a., the actions.
We want to exclude cases where one player probes with probability \(\varepsilon\) and another with probability \(\varepsilon^2\). The proof of Theorem 4 would not apply in this case.
See Young (2009) for an interesting modification of this learning rule.
In their original presentation of the game, Bala and Goyal allow for arbitrarily high costs which creates essentially three different games with different properties. One where c ≤ 1, another where n − 1 ≥ c > 1, and finally one where c > n − 1. The case where c > n − 1 is not terribly interesting as the cost of obtaining information is so high that it is not worth obtaining it (each player has a dominant strategy). While the case where n − 1 ≥ c > 1 is very interesting, it has rather different properties from the game where c ≤ 1 and space prevents its discussion here. We also ignore the case of c = 1 since it implies that a player is indifferent between linking and not linking to some other player.
See Bala and Goyal (2000) for proofs.
A directed graph is strongly connected if there is a directed path between each two vertices. Henceforth we will use the term “connected” to mean strongly connected.
A strategy profile is Pareto efficient if no player can be made better off by manipulating the choices of any number of players without making some other agent worse off.
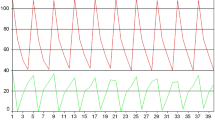
These graphs are for simulations with c = 0.5, but the results are characteristic for other costs as well.
The difference between these two measures is obscured by in-the-limit analysis since the limit average payoff will approach the optimal payoff as the probability of optimal play approaches one. In finite time, however, these two measures of performance need not necessarily coincide.
Proposition 2 does not depend on the probability distribution over the states of nature.
References
Argiento, R., Pemantle, R., Skyrms, B., & Volkov, S. (2009). Learning to signal: Analysis of a micro-level reinforcement model. Stochastic Processes and their Applications, 119, 373–390.
Bala, V., & Goyal, S. (2000). A noncooperative model of network formation. Econometrica, 68, 1129–1181.
Barrett, J., & Zollman, K. J. S. (2007). The role of forgetting in the evolution and learning of language. Journal of Experimental and Theoretical Artificial Intelligence, 21, 293–309.
Beggs, A. W. (2005). On the convergence of reinforcement learning. Journal of Economic Theory, 122, 1–36.
Binmore, K., & Samuelson, L. (1992). Evolutionary stability in repeated games played by finite automata. Journal of Economic Theory, 57, 278–305.
Brown, G. W. (1951). Iterative solutions of games by fictitious play. In Activity analysis of production and allocation (pp. 374–376). New York: Wiley.
Fudenberg, D., & Levine, D. K. (1998). The theory of learning in games. Cambridge, MA: MIT Press.
Hopkins, E. (2002). Two competing models of how people learn in games. Econometrica, 70, 2141–2166.
Hopkins, E., & Posch, M. (2005). Attainability of boundary points under reinforcement learning. Games and Economic Behavior, 53, 110–125.
Hu, Y., Skyrms, B., & Tarrés, P. (2012). Reinforcement learning in signaling games. Working paper, arXiv:1103.5818.
Huttegger, S.M. (2007). Evolution and the explanation of meaning. Philosophy of Science, 74, 1–27.
Huttegger, S. M. (2012). Probe and adjust. Biological Theory (forthcoming).
Huttegger, S.M., Skyrms, B. (2008). Emergence of information transfer by inductive learning. Studia Logica, 89, 237–256.
Huttegger, S. M., & Skyrms, B. (2012). Emergence of a signaling network with “probe and adjust. In B. Calcott, R. Joyce, K. Sterelny (Eds.), Signaling, commitment, and emotion. Cambridge, MA: MIT Press.
Kimbrough, S.O., & Murphy, F. H. (2009). Learning to collude tacitly on production levels by oligopolistic agents. Computational Economics, 33, 47–78.
Lewis, D. (1969). Convention: A philosophical study. Harvard, MA: Harvard University Press.
Marden, J. R., Young, H. P., Arslan, G., & Shamma, J. S. (2009). Payoff-based dynamics for multiplayer weakly acyclic games. Siam Journal of Control and Optimization, 48, 373–396.
Pawlowitsch, C. (2008). Why evolution does not always lead to an optimal signaling system. Games and Economic Behavior, 63, 203–226.
Skyrms, B. (1996). Evolution of the social contract. Cambridge: Cambridge University Press.
Skyrms, B. (2010). Signals: Evolution, learning, and information. Oxford: Oxford University Press.
Skyrms, B. (2012). Learning to signal with ‘probe and adjust’. Episteme, 9, 139–150.
Wärneryd, K. (1993). Cheap talk, coordination and evolutionary stability. Games and Economic Behavior, 5, 532–546.
Young, H. P. (1993). The evolution of conventions. Econometrica, 61, 57–83.
Young, H. P. (1998). Individual strategy and social structure. An evolutionary theory of institutions. Princeton, NJ: Princeton University Press.
Young, H. P. (2004). Strategic learning and its limits. Oxford: Oxford University Press.
Young, H. P. (2009). Learning by trial and error. Games and Economic Behavior, 65, 626–643.
Acknowledgments
We would like to thank two anonymous referees for helpful comments. This material is based upon work supported by the National Science Foundation under Grant No. EF 1038456 and SES 1026586. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation. Huttegger was supported by National Science Foundation grant EF 1038456. Zollman was supported by NSF grants EF 1038456 and SES 1026586.
Author information
Authors and Affiliations
Corresponding author
Appendix: Sketch of Proof for Theorem 4
Appendix: Sketch of Proof for Theorem 4
The argument follows the same steps as the proof of Theorem 3.2 in Marden et al. (2009); more details for the case of weakly better reply games are given in Huttegger (2012).
We start with a specification of a state space of the process. Let \(a = (a_1, \ldots, a_N)\) be an action profile. Let \(a^p=(a_1^p, \ldots, a_N^p)\) be such that a p i = 0 if player i does not probe and a p i = a i ′ if player i probes and a i ′ was player i’s choice of action in the previous period. Let A denote the set of all action profiles a and A p the set of all action profiles a p. Then probe and adjust is a Markov chain on A × A p. (a, 0) denotes the state where action profile a is chosen and no one probes. In the unperturbed Markov process where \(\varepsilon = 0, (a, {\bf 0})\) is a recurrence class for each a; each state where at least one player probes is transient.
The proof now proceeds by applying the resistance tree method for analyzing stochastic stability as developed in Young (1993). Our goal is to show that, in weakly better reply games, only states (a, 0) where a is a strict Nash equilibrium are stochastically stable. This means that only these states have positive probability of being observed in the long run as the parameter \(\varepsilon\) tends to 0. Notice that this yields the assertion of Theorem 4. By a famous result in Young (1993), stochastically stable states of a process are the ones that have minimum stochastic potential. This quantity can be specified by determining the resistances of going from one state to another. Suppose that (a, 0) and (b, 0) are two states with \(a \not = b\). (By a result in Young (1993) it is enough to consider the resistances between recurrent states of the unperturbed process.) Look at all the ways of getting from (a, 0) to (b, 0) by having agents probe and adjust. Note, for any intermediate step, how many agents probe. Add the number of all these agents. This is the resistance of the specific path from (a, 0) to (b, 0). Let r ab be the minimum resistance over all possible paths from a to b.
For any state (a, 0), we then construct a tree rooted at (a, 0). This is a graph with vertices consisting of all states (b, 0) such that for any such state there is a unique directed path to (a, 0). If there is a directed edge from (b, 0) to (c, 0) in this graph, we associate the weight r bc with it. The resistance of the tree rooted at (a, 0) is the sum of all the weights of the edges. The stochastic potential of (a, 0) is the minimum resistance of all trees rooted at (a, 0). Since these states coincide with the stochastically stable states of the probe and adjust process, we have to show that (a, 0) has minimum stochastic potential only if a is a strict Nash equilibrium.
There are three basic lemmata. The first is obvious since leaving a state where no player probes requires at least one player to probe.
Lemma 5
For any state (a, 0), the resistance of leaving a is at least 1.
The proof of the second lemma is based on the defining property of weakly better reply games.
Lemma 6
For any state (a, 0 ) there is a finite sequence of transitions to a state (a*, 0 ) such that a* is a strict Nash equilibrium and the resistance of each step in the transition is 1.
The third lemma states that leaving a strict Nash equilibrium state has resistance at least 2. This should be clear from the definition of strict Nash equilibrium; either at least two players have to probe simultaneously or one immediately following the other so that each of them gets at least the same payoff as at the strict Nash equilibrium state.
Lemma 7
For any state (a, 0 ) with a a strict Nash equilibrium, any path from (a, 0 ) to some other state (b, 0) has resistance at least 2.
The proof can now be completed by showing that whenever a tree T is rooted at a state (b, 0) where b is not a strict Nash equilibrium, it can be transformed into a tree T′ rooted at a strict Nash equilibrium state such that the stochastic potential of T′ is strictly less than the stochastic potential of T. By Lemma 6 there exists a path from (b, 0) to (a, 0) such that a is a strict Nash equilibrium and the resistance at each step on the path is equal to 1. Add the edges corresponding to the path to T and delete the old edges from T on the path. This results in a tree rooted at (a, 0). On the path, each old outgoing edge had resistance at least 1 by Lemma 5, except (a, 0) which had resistance at least 2 by Lemma 7. Thus the new tree has strictly less stochastic potential.
Rights and permissions
About this article
Cite this article
Huttegger, S.M., Skyrms, B. & Zollman, K.J.S. Probe and Adjust in Information Transfer Games. Erkenn 79 (Suppl 4), 835–853 (2014). https://doi.org/10.1007/s10670-013-9467-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10670-013-9467-y