 Natalia Cherepovskaia1
Natalia Cherepovskaia1 Natalia Slioussar
Natalia Slioussar- 1Department of Translation and Language Sciences, Universitat Pompeu Fabra, Barcelona, Spain
- 2Department of Liberal Arts and Sciences, Saint Petersburg State University, Saint Petersburg, Russia
- 3School of Linguistics, Higher School of Economics, Moscow, Russia
One of the central questions in second language processing studies is whether native (L1) and second language (L2) readers process sentences relying on the same mechanisms or there are qualitative differences. As their proficiency grows, L2 readers become more efficient, but it is difficult to determine whether they develop native-like mechanisms or rely on different strategies. Our study contributes to this debate by focusing on constructions that were demonstrated to cause characteristic problems in L1 processing: a particular type of case errors in Russian was taken as an example. We investigated how beginner and intermediate learners of Russian process such errors, measuring reading times and grammaticality judgment accuracy. At the beginner level, we found non-native-like patterns both in online and in offline measures. But at the intermediate level, native-like problems emerged in offline measures. In our view, this is a strong indication that these readers are using the same underlying mechanisms as in L1 processing. In online measures, L2 readers at both levels were, in general, much slower than native participants and exhibited characteristic non-native-like patterns, which we explained by delayed morphosyntactic processing. We conclude that our results are compatible with approaches, assuming that the mechanisms for L1 and advanced L2 processing are the same, but L2 processing is more cognitively demanding and therefore slower.
Introduction
In studies of second language (L2) processing, the central question is whether the mechanisms and strategies it relies on are essentially the same as in the native language (L1) or there are qualitative differences. The answer to this question remains elusive: the obvious problems at the early stages of L2 acquisition might have different sources, and when performance subsequently improves and becomes more native-like, non-native-like strategies might underlie this achievement. In the present paper, we argue that focusing on constructions that were shown to cause characteristic processing problems for native speakers may help to shed new light on this question. Similar problems observed in L2 processing may be taken as an argument in favor of common underlying mechanisms – characteristic errors are definitely not one of the language learner’s goals, but a by-product of using a particular means to achieve a communicative goal.
Therefore, our aim was to select a processing problem characteristic of L1 readers and to investigate whether it can also be observed in L2 readers at different proficiency levels in online and offline measures. One type of processing problem that is extensively discussed in the experimental literature is grammaticality illusions. This term is used to describe the situation when a certain type of grammatical error is particularly difficult to detect. This is manifested in both online and offline measures: in reduced error-related reading time (RT) delays and in the higher proportions of incorrect answers in the speeded grammaticality judgment (GJ) task. In the present study, we selected a variety of case errors in Russian that were shown to give rise to grammaticality illusions (Slioussar and Cherepovskaia, 2014, 2021).
We conducted an experiment with three groups of L2 learners of Russian: an intermediate English-speaking group and two beginner groups (the speakers of English and the speakers of Spanish and Catalan). Participants read grammatical and ungrammatical sentences, including examples with different types of case errors, while RTs were measured and made GJs. Summarizing the results, we demonstrated that at the beginner level, both online and offline measures were influenced by factors that are not relevant to native speakers, but at the intermediate level, a native-like pattern emerged in offline measures. We argue that this happened when inflectional paradigms were acquired well enough – then L2 processing can rely on them in the same way as L1 processing does. However, intermediate L2 learners were still much less efficient than native speakers, which were reflected in the remaining differences in online measures. Finally, our study sheds new light on the underinvestigated topic of case processing by L2 readers.
The paper has the following structure. We start with a short overview of theoretical approaches to the differences in L1 and L2 processing. Then, we briefly present the relevant information on Russian grammar, on experimental studies of the Russian case system and grammaticality illusions in processing, before turning to our study.
L1 and L2 Processing
Many authors assume that L1 and L2 processing mechanisms are qualitatively different but have divergent views on the source of these differences. According to the Shallow Structure Hypothesis (SSH; Clahsen and Felser, 2006a,b,c; Clahsen et al., 2010), L2 speakers are less sensitive to syntactic information in sentence processing and rely on semantic and pragmatic cues to a greater extent than L1 speakers. The Interface Hypothesis (IH; Sorace, 2011) suggests that near-native L2 speakers have difficulties with the integration of syntactic information and information from other cognitive domains.
The Bottleneck Hypothesis (Slabakova, 2009) claims that while L2 acquisition of semantics, syntax, and even pragmatics flow relatively smoothly, inflectional morphology is the major source of problems. These problems have a dramatic effect on processing because inflectional morphology encodes grammatical features and is the locus of crosslinguistic differences. Prévost and White (2000) proposed another morphology-based theory, the Missing Surface Inflection Hypothesis (MSIH), according to which the mapping of morphological forms to abstract grammatical categories is the weak link.
Another group of theories assumes that L1 and L2 might be different due to maturational changes in memory-processing mechanisms. For example, the Ullman’s declarative/procedural (DP) model (Ullman et al., 1997; Ullman, 2015, 2018) claims that learning abilities in the procedural memory peak during early childhood, while learning abilities in the declarative memory improve during childhood and early adulthood. Hence, L1 and L2 acquisition and processing rely on these two long-term memory systems to a different extent. In particular, procedural memory is responsible for generalized grammatical rules, which makes L1 processing faster and more automatic. Cunnings (2017) suggests that a primary source of L1/L2 processing differences lies in the ability to retrieve information from memory, and that L2 speakers are more susceptible to retrieval interference.
Now let us turn to the models assuming that L1 and L2 processing rely on the same mechanisms, and that the observed differences are due to independent factors. Firstly, L2 processing is cognitively more demanding (e.g., Hopp, 2006, 2010; McDonald, 2006), which might be due to lower automaticity and speed (Segalowitz, 2003; Segalowitz and Hulstijn, 2005; Jegerski, 2012; Kaan et al., 2015), limitations in lexical access (McDonald and Roussel, 2010), and syntactic integration (Hopp, 2014). Secondly, L2 processing may be less efficient due to interference from L1 (Sabourin and Haverkort, 2003; Hopp, 2006, 2010; McDonald, 2006; Basnight-Brown et al., 2007; Portin et al., 2007, 2008; Feldman et al., 2010; Jackson, 2010). Thirdly, L2 proficiency level plays a major role (Hopp, 2006; Gor and Jackson, 2013; Coughlin and Tremblay, 2015). For instance, Hopp (2006) showed that depending on their level, L2 readers process subject-object ambiguities more or less similarly to native speakers.
Cognitive resource limitations may also be responsible for the fact that L2 speakers perform better in offline experiments than in online ones (e.g., Hopp, 2010; López Prego and Gabriele, 2014). Interestingly, if the processing load increases in the online task, native speakers may demonstrate patterns similar to L2 learners. Based on this observation, Kaan et al. (2015) claims that L1 and L2 processing mechanisms are not different in nature, and the differences can be explained by the same factors that drive individual differences in L1 processing.
In the present paper, we aim to find out whether L2 readers gradually develop not only “good,” but also “bad” native-like processing patterns. The former may simply reflect their growing processing efficiency, while the latter is indicative of relying on the same processing mechanisms as those of the native speakers and may be used to tease apart the different theoretical approaches presented above.
The Russian Case System
The Russian case system is complex, which makes it very difficult for L2 learners. Russian nouns are inflected for two numbers and six cases: nominative, genitive, dative, accusative, instrumental, and locative (also called as prepositional). The choice of case may be influenced by the syntactic role of the noun (subject, direct or indirect object, etc.), its semantic role (agent, patient, experiencer, etc.), and by the particular verb or preposition of this noun depends on. Moreover, the choice of inflection for a given case depends on the inflectional class and subclass the noun belongs to, which is determined based on several heterogeneous factors: the grammatical gender of the noun (masculine, feminine, or neuter), its animacy, and the phonological properties of the stem.
Adjectives and participles that modify nouns agree with them in number, case, and gender (only in the singular). They have separate sets of inflections. Table 1 provides two examples: the paradigms of the noun phrases novyj stol “new tableM” and novaja škola “new schoolF.” Both nouns are inanimate and have the same non-palatalized consonant at the end of the stem, and the same adjective with a non-palatalized stem-final consonant is used in both phrases, so Table 1 does not illustrate the variation determined by these factors.

Table 1. Paradigms of the noun phrases novyj stol “new tableM” and novaja škola “new schoolF.”
As Table 1 shows, the Russian case system involves complex patterns of syncretism. For example, adjective and noun inflections may coincide in nominative and accusative – this is true for all inanimate nouns in plural and for most inanimate and some animate nouns in singular. The genitive singular form of the noun škola “schoolF” is also syncretic with nominative and accusative plural, although the corresponding adjective forms are different; dative and locative singular have the same ending. As for adjectives, genitive, dative, instrumental, and locative forms coincide in feminine singular paradigms, and genitive and locative forms coincide in plural paradigms, although most corresponding noun forms are not syncretic. As we show below, syncretic adjective forms are crucial for the present study: they trigger the grammaticality illusions explored in our experiment.
Before we turn to grammaticality illusions, let us briefly review the previous studies of L2 processing of a case in Russian. While there is a substantial body of literature on L1 acquisition of the case system and several studies on L2 acquisition (e.g., Babyonyshev, 1993; Rubinstein, 1995a,b; Voeikova and Gagarina, 2002; Voeikova, 2011; Cherepovskaia et al., 2021), only a couple of papers are dedicated to L2 processing. They do not focus on case error processing, but their general conclusions are nevertheless relevant for our study.
Kempe and Mac Whinney (1998) compared English speakers learning Russian and German. In their experiment, participants were asked to perform a speeded picture choice task after hearing simple noun-verb-noun sentences. The influence of different factors was tested: word order (the canonical subject-first vs. the inverted object-first word order), animacy of the nouns, and case marking (only the nominative and accusative cases were investigated). The results demonstrated that the learners of Russian used case marking much more effectively than the learners of German. Kempe and MacWhinney concluded that this was because cases are a stronger cue in Russian, in spite of the complexity of the paradigm. Similar results were obtained in those authors’ following study (Kempe and Mac Whinney, 1999).
Gor et al. (2017) conducted two auditory lexical decision experiments that comparing native and non-native processing of different case forms. They used nominative and genitive forms with overt and zero inflections (as Table 1 shows, some Russian nouns have a zero inflection in the nominative singular and an overt inflection in the genitive plural, while for some other nouns, the opposite is true). Native speakers always processed nominative forms significantly faster than other forms, irrespective of the inflections (individual form frequency was taken into account). The performance of L2 learners who were native speakers of English depended on the task and on the proficiency level. In the first experiment, neither case nor inflection type significantly influenced reaction times. In the second experiment, more complex nonce stimuli were used: real stems combined with real inflections from a wrong paradigm, which made participants pay more attention to the morphological properties of the stimuli. As a result, a native-like pattern emerged in the more advanced L2 group. Gor et al. conclude that the main problem for non-native speakers is not the morphological decomposition, as some authors have suggested (e.g., Clahsen and Felser, 2006a), but recombining the information encoded in the stem and the affix.
In another auditory lexical decision study with cross-modal morphosyntactic priming, Gor et al. (2019) compared three cases: nominative, genitive, and instrumental. Adjectives agreeing with nouns served as primes. Native speakers demonstrated significant differences among all three cases, with nominative being the fastest and instrumental the slowest (as before, individual form frequencies were taken into account). This reflects the hierarchical structure of the nominal paradigm, where cases have different functional load and type frequency. Non-native participants (English speakers) were early (heritage) and late learners of Russian with different proficiency levels. For all of them, a significant difference between nominative and oblique cases was found, but highly proficient late learners showed a native-like difference between genitive and instrumental. This demonstrates the maturation of the case system, which we are also going to explore in the present study.
Grammaticality Illusions
Grammaticality illusions are processing problems that have been studied in numerous experiments, predominantly with native speaker participants. Most studies have focused on grammaticality illusions in subject-verb agreement (also known as agreement attraction). In particular, they show that number agreement errors are more difficult to detect in sentences like (1a) than in sentences like (1b) (e.g., Clifton et al., 1999; Pearlmutter et al., 1999; Wagers et al., 2009; Dillon et al., 2013; Tanner et al., 2014). In other words, (1a) is likely to be erroneously perceived as grammatical – hence the term grammaticality illusion. This is manifested both in online and offline measures: in diminished error-related RT delays (e.g., Clifton et al., 1999; Pearlmutter et al., 1999; Wagers et al., 2009; Dillon et al., 2013), smaller P600 amplitudes in electroencephalographic studies (e.g., Tanner et al., 2014), and higher proportions of incorrect answers in GJ tasks (e.g., Wagers et al., 2009).
1.
a. *The key to the cabinets were rusty.
b. *The key to the cabinet were rusty.
There is general agreement that the grammaticality illusion in (1a) is triggered by the dependent noun: its plural feature disrupts the agreement between the subject noun and the verb, but different authors disagree about how exactly this happens. In their argumentation, they rely not only on processing, but also on production data: attraction errors are produced significantly more often than other agreement errors (e.g., Jespersen, 1924; Quirk et al., 1972; Bock and Miller, 1991; Vigliocco et al., 1995, 1996; Franck et al., 2002, 2006; Hartsuiker et al., 2003; Solomon and Pearlmutter, 2004; Eberhard et al., 2005; Staub, 2009, 2010). Existing approaches can be divided into two groups: some assume that the number representation on the noun phrase is faulty or ambiguous, while others argue that attraction takes place when we try to retrieve the agreement controller.
Agreement attraction has been studied not only in English, but also in many other languages. In Russian, it has been observed in number, gender, and person agreement (Nicol and Wilson, 1999; Yanovich and Fedorova, 2006; Lorimor et al., 2008; Laurinavichyute and Vasishth, 2016; Slioussar and Malko, 2016; Slioussar, 2018). A number of studies investigated subject-verb agreement violations and attraction in L2 (e.g., Nicol and Greth, 2003; Hoshino et al., 2010; Lim and Christianson, 2015; Jegerski, 2016; Lago and Felser, 2018). While non-native speakers may be less sensitive to some factors like animacy or the conceptual number of the noun (as opposed to the grammatical number), they show native-like agreement attraction patterns. This can be explained by the fact that the phenomenon relies on very general mechanisms in production and comprehension and is found across languages. Therefore, for our study, we selected a different type of grammaticality illusion that relies on particular features of Russian grammar.
Consider the examples in (2a–c; 2a) is grammatical, while in (2b) and (2c), the noun gorod “town” is in the wrong case. The form of the adjective modifying this noun is syncretic, and this was demonstrated to trigger grammaticality illusions in sentences like (2b) (Slioussar and Cherepovskaia, 2014, 2021). These errors cause shorter RT delays and higher proportions of incorrect answers in the speeded GJ task than other case errors, like the one in (2c). This happens despite the fact that the preposition o “about” can be used only with locative, which should resolve the ambiguity of the adjective form and predetermine the case of the noun. Syncretic adjective forms not only disrupt error detection in comprehension, but also increase error rates in production: Rusakova (2013) demonstrated this for naturally occurring errors, and Slioussar et al. (2017) for errors occurring in experimental conditions.
2.
a. Knigi o russkix gorodax byli interesnymi.
bookNOM.PL about RussianLOC.PL(=GEN.PL) townLOC.PL were interesting
‘The books about Russian towns were interesting.’
b. *Knigi o russkix gorodov byli interesnymi.
bookNOM.PL about RussianLOC.PL(=GEN.PL) townGEN.PL were interesting
c. *Knigi o russkix gorodam byli interesnymi.
bookNOM.PL about RussianLOC.PL(=GEN.PL) townDAT.PL were interesting
Slioussar and Cherepovskaia (2014, 2021) showed that grammaticality illusions can be observed with prepositions requiring different cases and with different syncretic adjective forms. There are different approaches to syncretism in theoretical morphology (e.g., Zwicky, 1991; Blevins, 1995; Stump, 2001; Bobaljik, 2002; Baerman et al., 2005; Müller, 2011), relying on the underspecification of inflectional morphemes, referral rules, etc. Grammaticality illusions discussed in this paper do not allow teasing them apart (although see some speculations in Slioussar and Cherepovskaia, 2021) – they only prove that syncretism is somehow represented in the mental lexicon.
As for the particular mechanisms underlying these illusions, Slioussar and Cherepovskaia (2014, 2021) suggested the following explanation, relying on their data and on other processing studies dealing with syncretism as well as on the retrieval approach to subject-verb agreement attraction (e.g., Solomon and Pearlmutter, 2004; Lewis and Vasishth, 2005; Badecker and Kuminiak, 2007; Wagers et al., 2009; Dillon et al., 2013): native speakers can predict the case of a noun based on the preposition, so the system detects a mismatch in sentences like (2b) and (2c). The violation of expectations always triggers rechecking: in particular, in (2b) and (2c) the parser tries to find out where the unexpected genitive or dative case came from. Syncretic forms activate not only the relevant set of features, but also – to a lesser extent – all sets for which they are ambiguous; so in examples like (2b), the system may retrieve the genitive plural feature set from the syncretic adjective form, which may lead to the wrong conclusion that the sentence is grammatical, i.e., to a grammaticality illusion.
The Present Study
The goal of the present study was to find out whether grammaticality illusions described in the previous section for L1 processing can also be found in L2 processing. As we noted above, for these illusions to be possible, syncretism should be somehow represented in the mental grammar (existing studies do not favor a particular theoretical approach to syncretism). We hypothesize that if L2 learners develop the relevant representations at all, this happens only when the system matures, i.e., not at the beginner level, but at more advanced proficiency levels. If this causes L2 learners to develop a processing pattern that is analogous to that of native speakers’ – i.e., specific problems with detecting particular case errors – this may be used as an argument in favor of similar L1 and L2 processing mechanisms.
For our study, we recruited three groups of L2 learners of Russian: two beginner groups with different native languages (English and Catalan and Spanish) and one upper-intermediate group of English native speakers. A control group of native speakers also participated in the study. We collected online and offline data using self-paced reading to measure word-by-word RTs and GJ.
Foreshadowing the results, we can say that RT patterns were similar in the three L2 groups and different from those of native speakers: for all L2 readers, genitive plural forms were especially difficult, while for L1 readers, no case form was more difficult than the others. The distribution of errors in GJs in the upper-intermediate group resembled those of native speakers, while the two beginner groups showed a different pattern. These results support the approaches arguing for similar processing mechanisms in L1 and L2, but indicate that for these mechanisms to start working, the representation of L2 grammar should reach a certain level. A non-native-like pattern in online measures points to the role of morphological complexity in L2 processing that plays no role in L1 processing (genitive plural has the largest variety of inflectional affixes in the plural subparadigm).
Experiment
Participants
Three groups of learners of Russian volunteered to participate in the experiment. Group 1 (English-speaking upper-intermediates) included 29 native speakers of American English (15 females), aged 20–26 (mean age 23.7). They were students at different American universities; at the time of the experiment, they were participating in an exchange program with Saint Petersburg State University in Russia. To enter the program, an upper-intermediate proficiency level (B2) in Russian was required. The students took part in the experiment after spending approximately 2 months in Russia.
Group 2 (Spanish-Catalan-speaking beginners) included 33 Spanish-Catalan bilinguals (19 females), aged 20–38 (mean age 25.6). They were studying Russian at the University of Barcelona and at the A. Pushkin Institute of Russian Language in Barcelona. They had passed their A1 level exams approximately 8 months before participating in the experiment and had approximately 1 month to study before their A2 level exam. At the time of the experiment, they had never been to Russia either to study the language or as tourists.
Group 3 (English-speaking beginners) included 51 native speakers of American English (34 females), aged 20–28 (mean age 24.3). They were studying Russian at different universities in the USA. They had passed their A1 level exams approximately 6–8 months before participating in the experiment and had approximately 1–3 months to study before their A2 level exam. Like the participants from Group 2, they had never been to Russia.
Finally, a control group of native Russian speakers was recruited in Saint Petersburg. This group included 36 participants (20 females), aged 20–25 (mean age 22.5).
The experiment was carried out in accordance with the Declaration of Helsinki and existing Russian and international regulations concerning ethics in research. All participants provided informed consent.
Upper-intermediate English-speaking participants and Spanish-Catalan-speaking beginners were recruited from two particular language-learning programs and tested one by one in a quiet room. English-speaking beginners were recruited from Russian learning programs at several American universities and tested online. Thus, this group was potentially less homogeneous, but the fact that the results were very similar in the two beginner groups shows that the observed pattern was not accidental, and the differences between these groups and the upper-intermediate group cannot be associated either with different native languages or with different experimental settings.
Materials
We constructed 27 sets of target sentences. Every set consisted of a grammatically correct sentence and two versions with case errors. All sentences contained six words and had the same syntactic structure: a subject noun in nominative plural modified by a prepositional phrase (a preposition, an adjective, and a target noun) and a predicate (the verb byli “were” and an adjective or a participle). We selected prepositions that require locative, genitive, or dative case. An example of a genitive preposition set is given in (3a–c); an example of a locative preposition set is presented in (2a–c) above. Target nouns could appear in genitive, locative, and dative plural – depending on the preposition, one case form was correct and two others were ungrammatical.
3.
a. Fil’my bez izvestnyx akterov byli skučnymi.
movieNOM.PL without famousGEN.PL(=LOC.PL) actorGEN.PL were boring
‘The movies without famous actors were boring.’
b. *Fil’my bez izvestnyx akterax byli skučnymi.
movieNOM.PL without famousGEN.PL(=LOC.PL) actorLOC.PL were boring
c. *Fil’my bez izvestnyx akteram byli skučnymi.
movieNOM.PL without famousGEN.PL(=LOC.PL) actorDAT.PL were boring
As we discussed in the introduction, the syncretism of adjective forms in the genitive and locative plural triggers grammaticality illusions in native speakers: errors like (3b) are less noticeable than other case errors, as in (3c; Slioussar and Cherepovskaia, 2014, 2021). We will call them target and control errors. The resulting experimental conditions are listed in Table 2.
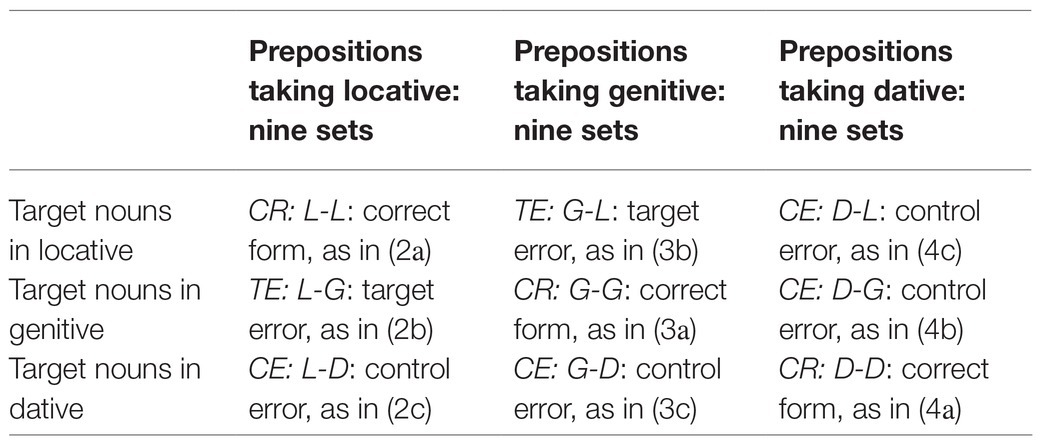
Table 2. Nine experimental conditions.
Thus, we had locative and genitive preposition sets with target and control errors. We used the following abbreviations for the experimental conditions: for example, CR: L-L (a grammatically correct sentence: a preposition taking the locative case with a target noun in locative), TE: L-G (a sentence with a target error: a preposition taking the locative case with a target noun in genitive), CE: L-D (a sentence with a control error: a preposition taking the locative case with a target noun in the dative). Following Slioussar and Cherepovskaia (2014, 2021), we used dative forms as control errors1 and added dative preposition sets, as in (4a–c), to our materials.
4.
a. Učitelja po inostrannym jazykam byli xorošimi.
teacherNOM.PL on foreignDAT.PL languageDAT.PL were good
‘The teachers of foreign languages were good.’
b. *Učitelja po inostrannymjazykax byli xorošimi.
teacherNOM.PL on foreignDAT.PL languageLOC.PL were good
c. *Učitelja po inostrannym jazykov byli xorošimi.
teacherNOM.PL on foreignDAT.PL languageGEN.PL were good
Dative plural adjective forms are not morphologically ambiguous, so these sets contain no target errors. They were used to balance the stimuli (so that genitive, locative, and dative target nouns were equally frequent as correct forms and as errors) and to compare different case errors in a situation, where no grammaticality illusions are expected. For native speakers, Slioussar and Cherepovskaia (2014, 2021) found no difference between the CE: D-L and CE: D-G conditions, either in RTs or in GJ results. This confirmed their conclusion that the differences observed in the locative and genitive preposition sets were indeed due to grammaticality illusions, and other factors did not play a significant role.
Otherwise, our materials were different from those of Slioussar and Cherepovskaia (2014, 2021). We simplified the syntactic structure of target sentences and tried to select only the high frequent words that would be familiar to learners of Russian from very early on. To do so, we relied on several textbooks of Russian as a foreign language that were used at the universities our participants attended (e.g., Nummikoski, 1996; Lubensky et al., 2001; Kagan et al., 2005; Lekić et al., 2008). All target word forms were 6–9 letters long.
In total, 62 sentences were included: 27 target sentences (nine grammatical and 18 ungrammatical) and 35 fillers (22 grammatical and 13 ungrammatical, with subject-predicate agreement errors to make the task more diverse). We distributed target sentences among three experimental lists using the Latin square principle. As a result, each list contained one sentence from every target set. Fillers were the same in every list. During the experiment, participants were assigned to one of the three lists and presented with target and filler sentences from their list in a random order.
Procedure
For Groups 1 and 2 and for native speakers, the experiment was run on a PC using Presentation software.2 For Group 3, it was run on a web-based platform using Ibex Farm (Drummond, 2013). This method was found to be reliable in several previous psycholinguistic studies including those dedicated to L2 processing (e.g., Lago et al., 2019).
We used the word-by-word self-paced reading methodology (Just et al., 1982). Each trial began with a screen presenting a sentence, in which the words were masked by dashes, while spaces and punctuation remained intact. Each time the participant pressed the space bar, a word was revealed, the previous word was re-masked, and RTs were measured.
At the end of each sentence, participants were asked whether the sentence they had read was grammatically correct and gave a yes/no response by button press. Participants were instructed to read at a natural pace and to give their responses as quickly as possible. Four practice items were presented before the beginning of the experiment.
Thus, we combined self-paced reading and GJ tasks in one experiment, while Slioussar and Cherepovskaia (2014, 2021) used them separately, as is customary in L1 studies. In Slioussar and Cherepovskaia’s self-paced reading experiments, no more than one-sixth of stimulus and filler sentences contained errors, and comprehension questions rather than grammaticality questions were used so as not to attract readers’ attention to errors and not to disrupt their natural reading patterns. In another experiment, Slioussar and Cherepovskaia used the speeded GJ method, because a non-speeded task would be too simple for native speakers.
With L2 readers, the situation is different. Even our upper-intermediate group made a lot of errors in the non-speeded GJ task. As for RT patterns, we ran an additional pilot experiment with a group of 10 upper-intermediate English-speaking students who did not take part in the main study. We used the same stimulus sentences and added grammatically correct filler sentences with the same syntactic structure (with prepositions requiring genitive, locative, or dative case, as in the main study), so that only one-quarter of the sentences contained errors. Instead of GJ questions, we asked comprehension questions with a choice of two answers. This pilot experiment revealed the same tendency that we found in the main study: genitive plural forms were more difficult to process than locative and dative ones. This confirmed the validity of our decision to collect online and offline data from L2 participants in one study.3
We recruited a control group of native speakers using the same experimental design, but, as could be expected, the task was too easy for them. They made virtually no GJ errors. Unlike the L2 participants, their RT patterns changed compared to the self-paced reading experiments of Slioussar and Cherepovskaia (2014, 2021), which did not focus the readers’ attention on errors. Therefore, below we will compare our L2 groups both to the control native speaker group and to the results reported by Slioussar and Cherepovskaia, since the complexity of their tasks is more appropriate for L1 readers.
Analysis
We analyzed participants’ RTs and GJ accuracy. Only items for which the grammaticality question was answered correctly were included in the RT analysis. Every target sentence contained six words, or regions, for which RTs were measured. RTs that exceeded a threshold of 2.5 standard deviations, by region and by condition, were excluded (Ratcliff, 1993). In total, 2.4% of the data was excluded in the NS Group, 3.2% of the data in Group 1, 4.7% of the data in Group 2, and 9.5% of the data in Group 3.
The statistical analysis was done in the R programming environment.4 We modeled RT data with a mixed-effects regression using the lmer function from the lme4 package, and GJ data with a mixed-effects logistic regression using the glmer function from the lme4 package (Bates et al., 2015). To obtain the values of p from the t values given by the model, we used the lmerTest package (Kuznetsova et al., 2015). For post hoc analyses, Tukey’s tests were conducted using the glht function from the multcomp package (Bretz et al., 2010). Random intercepts and random slopes by a participant and by an item were included in the models.
We started by analyzing sentences from the locative, genitive, and dative preposition sets separately in every group. As we showed in Table 2, in every set the target noun could be used in three different cases (one grammatically correct condition and two conditions with errors). We used mixed-effects regressions to estimate the differences between conditions in every region, treating the case of the target noun as a factor of interest. The correct case was taken as the reference level. Then, when two conditions with errors were compared, dative was taken as the reference level in the locative and genitive sets, and genitive in the dative sets.
We noticed that L2 readers processed genitive plural target nouns slower than dative and locative ones, independently of any other factors. To estimate this statistically, we used mixed-effects regressions on all data from the region containing the target noun in every group. We treated the case of the target noun as a factor of interest. First, the dative case was taken as the reference level and then genitive to compare the two remaining cases.
As for GJs, we analyzed sentences from the locative, genitive, and dative preposition sets using a mixed-effects logistic regression. The case on the target noun was the factor of interest. As with RTs, the correct case was taken as the reference level. Then, when two conditions with errors were compared, dative was taken as the reference level in the locative and genitive sets, and genitive in the dative set. After looking at every group separately, we analyzed the three L2 groups together.
Results and Discussion
Control Group: Native Speakers of Russian
Reaction Times
Average RTs per region in different experimental conditions are presented in Figure 1. Let us first discuss the results obtained for the locative, genitive, and dative preposition sets separately. The results with p < 0.05 are reported as statistically significant (for all such results, model outputs are presented in Table 3). In all sets, there were no significant differences in regions 1–3 before the target noun, as expected: these regions contain the same words in different conditions.
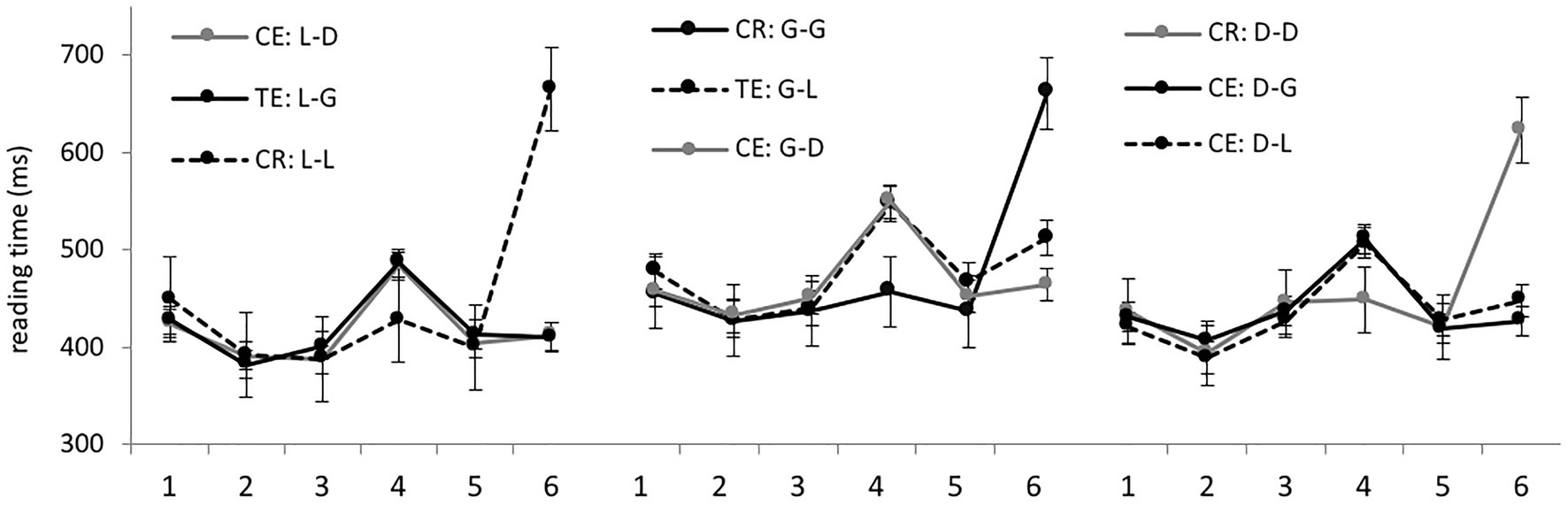
Figure 1. Native speaker group: average RTs per region (in ms) in the nine experimental conditions.
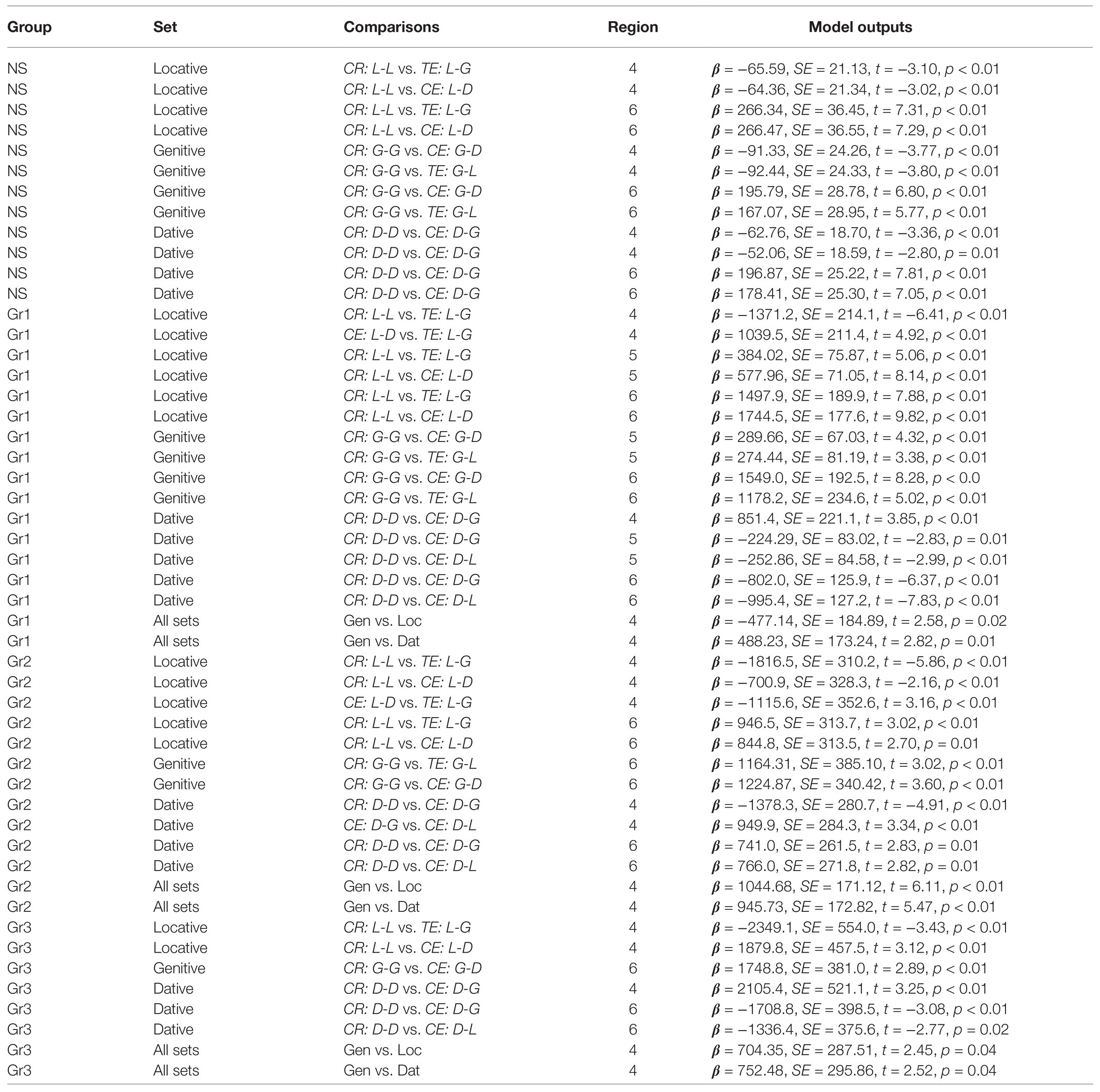
Table 3. Model outputs for RT analyzes in different conditions.
In region 4 (the target noun), correct case forms were processed significantly faster than incorrect forms in all sets. There were no differences between various errors. Thus, when L1 readers focus on error detection, grammaticality illusions disappear. No differences reached significance in region 5, while in the final region, region 6, grammatically correct sentences were processed significantly slower than incorrect ones in all sets. Presumably, in the latter case, the readers already knew the answer to the grammaticality question after detecting an error, while in the former, they spent some time rechecking that there were no errors.
We also looked at the processing times of target nouns depending on their case, taking data from all sets together. However, average RTs hardly differed: 484 ms for genitive plural and 493 ms for locative and dative plural. Accordingly, the analysis yielded no significant results.
Grammaticality Judgments
L1 readers made only three GJ errors, which constituted less than 0.01% of answers and were clearly accidental.
Group 1: English-Speaking Upper-Intermediates
Reaction Times
The average RTs per region in different experimental conditions are presented in Figure 2. Analyzing data from the locative, genitive, and dative preposition sets separately, we found significant differences only in regions 4–6 (model outputs are presented in Table 3). In regions 5 and 6 after the target noun, RTs in the correct conditions were significantly longer than in the ungrammatical ones. This result is similar to the L1 group: if a case error was detected in region 4, the remaining words could be read faster because participants already knew the answer to the grammaticality question.
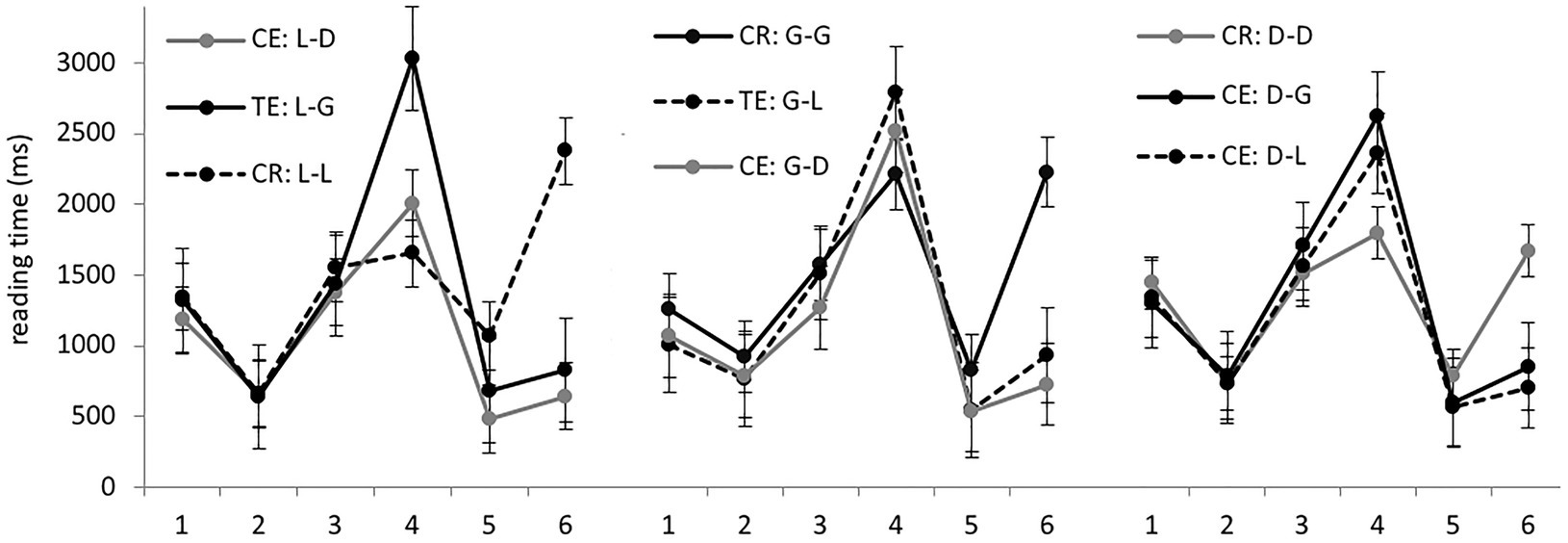
Figure 2. Group 1: average RTs per region (in ms) in the nine experimental conditions.
Now let us focus on region 4, containing the target noun. In the locative sets, genitive forms were read significantly slower than other forms, grammatical or ungrammatical. So the pattern was different both from the L1 control group and from the results obtained by Slioussar and Cherepovskaia (2014, 2021): in the former case, different case errors were processed equally slowly, while in the latter, genitive errors were processed faster than dative ones due to a grammaticality illusion. In the genitive sets, there were no significant differences in region 4. Thus, we found no evidence of grammaticality illusions; moreover, correct case forms were not processed significantly faster than incorrect ones. In the dative sets, genitive errors took significantly longer than correct forms, while the difference between the latter and locative errors did not reach significance.
Then we analyzed all the data from region 4 together. Genitive forms were processed significantly slower (2,626 ms on average) than both locative (2,269 ms) and dative (2,110 ms). No significant differences between locative and dative forms were found.
Let us summarize the results in region 4. In the native speaker group and in the experiments of Slioussar and Cherepovskaia (2014, 2021), the difference between grammatical and ungrammatical case forms was significant in all sets, while case marking per se was not a significant factor. Slioussar and Cherepovskaia (2014, 2021) also observed grammaticality illusion effects. In Group 1, as well as in the two other L2 groups to be discussed below, the grammaticality factor did not always reach significance, and there was no evidence of grammaticality illusions. But case marking affected RTs.
This result cannot be explained by case frequency or the order of acquisition. Genitive is much more frequent in the Russian language than locative and dative.5 L2 learners acquire genitive later than locative, but earlier than dative (see Rubinstein, 1995a,b; Cherepovskaia et al., 2021). However, this result can be explained by morphological complexity. Many inflectional classes and subclasses that have different case affixes in singular, use the same affixes in the plural, but genitive plural is an exception (this is partly illustrated in Table 1). Four affixes with different orthographic variants are used in genitive plural; the choice between them is regulated by relatively complex rules and depends on the inflectional class, the last consonant of the stem, and some other factors. We will come back to this question in more detail in the General Discussion section.
Grammaticality Judgments
The numbers and percentages of incorrect responses in different experimental conditions are presented in Table 4. The resulting picture is very similar to that observed in native speakers: conditions with target errors (where grammaticality illusions are expected) triggered more incorrect answers than conditions with control errors. In the sentences with prepositions requiring locative case, genitive errors were significantly more difficult to detect than dative errors (β = 1.61, SE = 0.48, z = 3.37, p < 0.01).6 In the genitive sets, there was an even more pronounced difference between locative and dative errors (β = 2.26, SE = 0.41, z = 5.51, p < 0.01). Furthermore, the grammaticality illusion condition (with locative errors) was significantly different from the correct condition (β = 1.82, SE = 0.38, z = 4.74, p < 0.01), while the condition with control dative errors was not. In the dative sets, where no grammaticality illusions were expected because adjective forms are morphologically unambiguous, there were no significant differences.
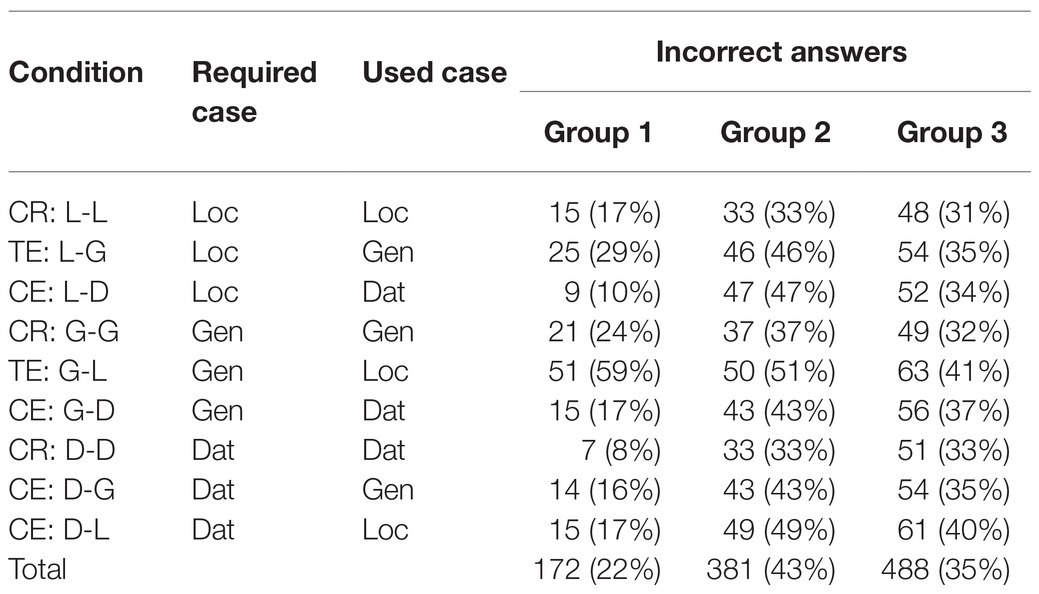
Table 4. Incorrect answers in different conditions.
Group 2: Spanish-Catalan-Speaking Beginners
Reaction Times
Average RTs per region in different experimental conditions are presented in Figure 3. We started by analyzing sentences from the locative, genitive, and dative preposition sets separately. Significant differences were found only in region 4, containing the target noun, and in the sentence-final region, region 6 (model outputs are presented in Table 3). In region 6, correct conditions were processed significantly slower than conditions with errors in all three sets.
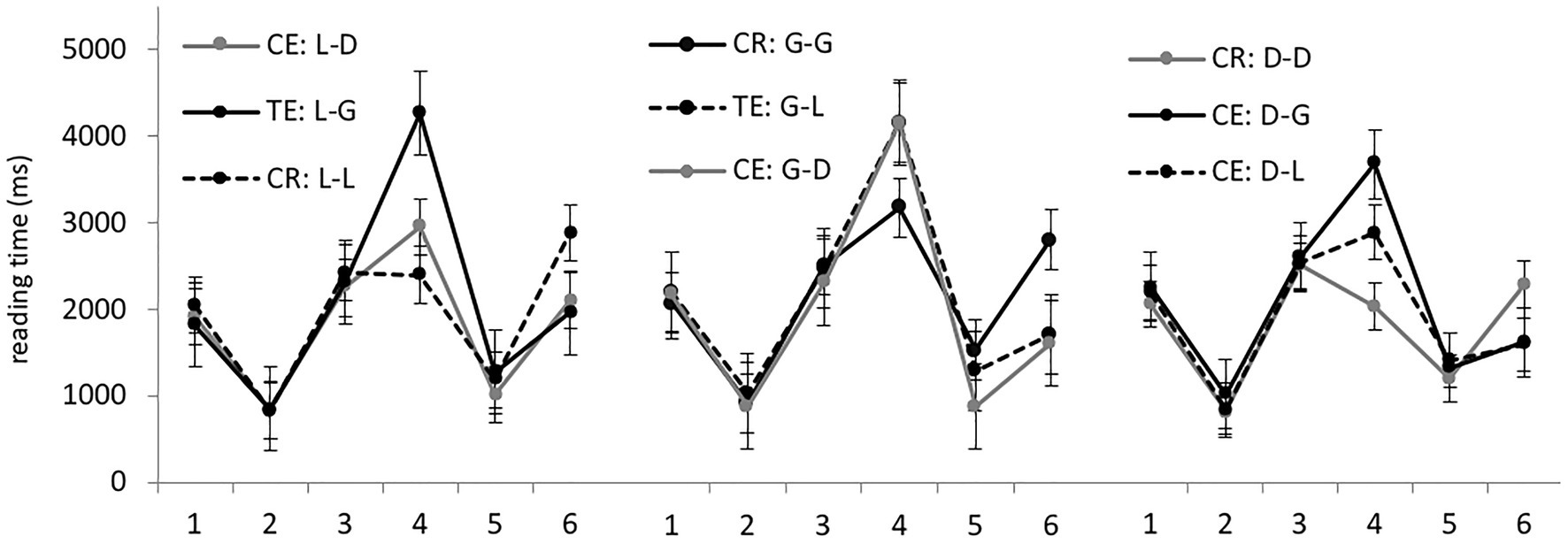
Figure 3. Group 2: average RTs per region (in ms) in the nine experimental conditions.
As in Group 1, region 4 showed no evidence of grammaticality illusions. In the locative sets, all three conditions differed significantly, with the correct locative forms being processed the fastest and genitive forms the slowest. In the genitive sets, there were no significant differences in this region. In the dative sets, correct noun forms differed significantly from genitive forms, but not from locative forms; genitive forms also took significantly longer than locative forms.
Analyzing all the data from region 4, containing the target noun, we found the same pattern as in Group 1. Genitive forms were read significantly slower (3,796 ms on average) than locative (3,231 ms) and dative ones (3,114 ms). The difference between genitive and the two other cases was significant.
Grammaticality Judgments
The numbers and percentages of incorrect responses in different experimental conditions are presented in Table 4. First of all, it is evident that the experimental task was difficult for beginner learners: on average, 43% of answers were incorrect, while the upper-intermediate Group 1 gave only 22% incorrect answers. Secondly, Group 1 demonstrated a native-like pattern, while Group 2 was non-native-like both in online and in offline measures. Target errors did not differ significantly from control errors, and, in fact, no differences between experimental conditions reached significance: apparently, all target sentences, both grammatical and ungrammatical, were difficult to judge for the beginner L2 readers.
Group 3: English-Speaking Beginners
Reaction Times
Average RTs per region in different experimental conditions are presented in Figure 4. We started by analyzing sentences from the locative, genitive, and dative preposition sets separately. Significant differences were found only in region 4, containing the target noun, and in the sentence-final region, region 6 (model outputs are presented in Table 3). As before, there was no evidence of grammaticality illusions. In region 6, grammatical sentences took significantly longer than ungrammatical ones with dative forms in the locative and genitive sets. In the dative sets, grammatical sentences were significantly different from both ungrammatical conditions.
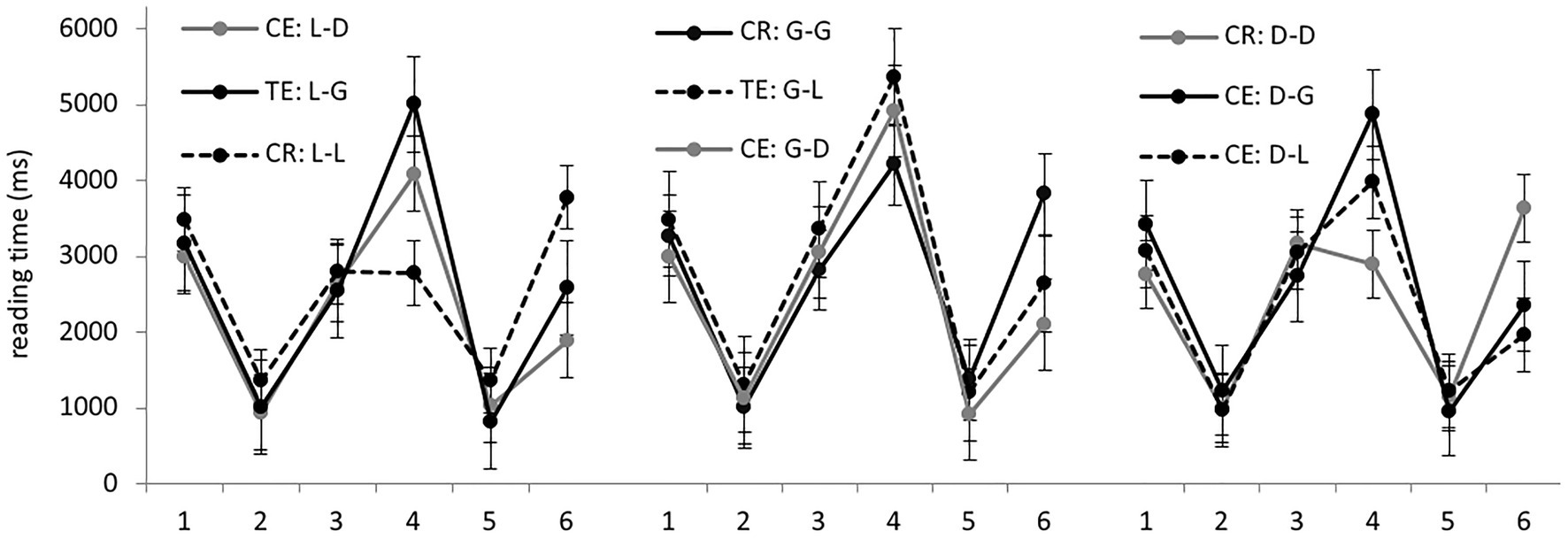
Figure 4. Group 3: average RTs per region (in ms) in the nine experimental conditions.
Now let us look at target nouns in region 4. In the locative sets, correct noun forms were significantly different from genitive forms, but not from dative forms. In the genitive sets, there were no significant differences. In the dative sets, only the difference between the grammatical dative and ungrammatical genitive forms was significant.
Analyzing the data from the all sets together, we found the same picture as in Groups 1 and 2. Genitive forms were processed significantly slower (4,714 ms on average) than both locative (4,054 ms) and dative ones (3,973 ms). The latter two were not significantly different.
Grammaticality Judgments
The numbers and percentages of incorrect responses in different experimental conditions are presented in Table 4. We do not observe a native-like pattern in the upper-intermediate Group 1; as in the Spanish–Catalan-speaking beginner group, no differences between experimental conditions reached significance. This confirms the conclusion we reached earlier: all target sentences were difficult by those judge at the beginner level.
All L2 Groups
Reaction Times
Analyzing the three groups separately, we could preliminarily conclude that in online measures, they showed the same non-native-like pattern. In region 4, containing the target noun, no grammaticality illusions were found; the differences between grammatical and ungrammatical forms did not always reach significance, but genitive forms were processed slower than locative and dative ones. Therefore, analyzing data from all L2 groups together, we ran a mixed-effects regression on RTs from region 4, treating the group and the case of the target noun as factors of interest. Dative case and Group 3 (as the most numerous group) were taken as reference levels. For all statistically significant results, model outputs are given in Table 5.
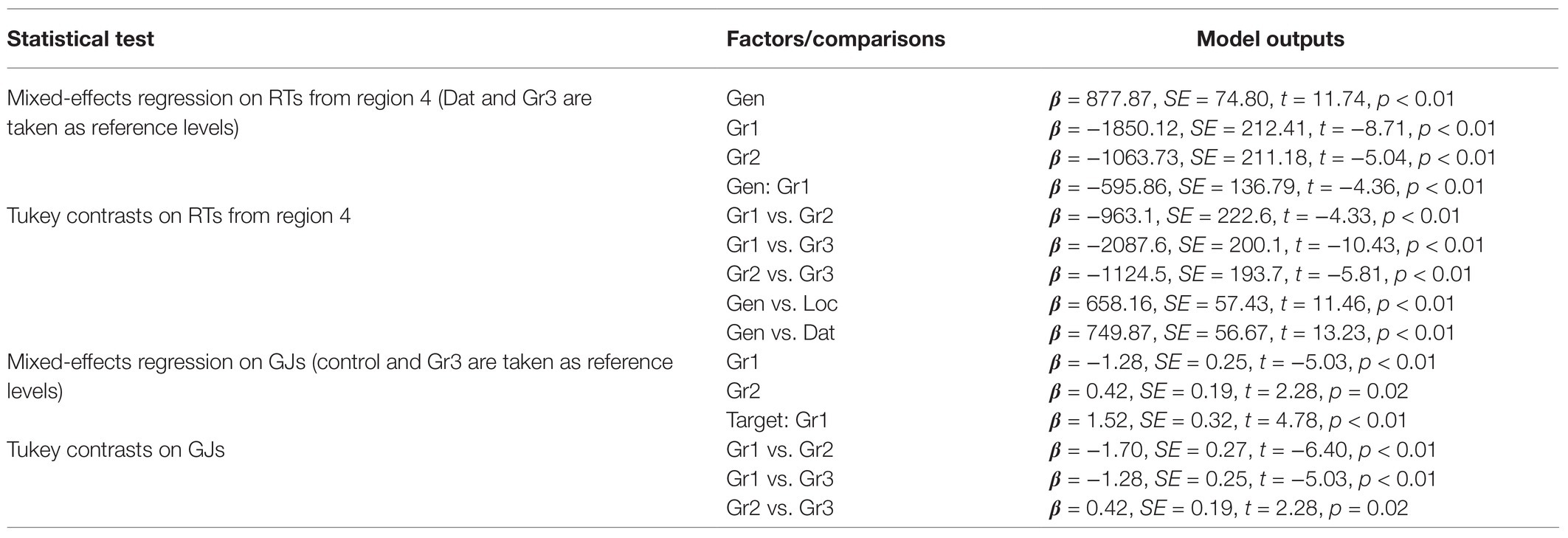
Table 5. All L2 groups: model outputs for RT and GJ analyzes.
Both Group 1 and Group 2 read significantly faster than Group 3. Genitive case was significantly different from dative, while locative was not. Out of four interactions (Group 1 by genitive, Group 2 by genitive, Group 1 by locative, and Group 2 by locative), only the first was significant. We also used multiple comparisons (Tukey’s contrasts) to estimate pairwise differences among the three groups and three cases.7 Group 1 was significantly faster than the two other groups, and Group 3 was significantly slower than Group 2. Genitive forms took significantly longer to process than both locative and dative, while the difference between the latter two was not significant.
The differences among the three groups were presumably partly due to their proficiency level (Group 1 was the fastest). As for the two beginner groups, Group 2 read faster than Group 3, but made more GJ errors, as we will show below. The differences between case forms let us conclude that despite different proficiency levels, native languages, and experimental settings, all groups exhibited the same non-native-like pattern of online results. As for the significant ‘Group 1 by genitive case’ interaction, it reflects the fact that this non-native-like difference between genitive forms vs. locative and dative forms was less pronounced in the more proficient Group 1 than in the two beginner groups.
Grammaticality Judgments
Analyzing the three groups separately, we found that Group 1 demonstrated a native-like difference between target and control errors, while the two beginner groups did not. To estimate this difference statistically, we took all judgment data for ungrammatical sentences from the locative and genitive sets (containing target and control errors) and ran a mixed-effects logistic regression. The factors of interest were the error type (target vs. control) and the group. Control errors and Group 3 were taken as reference levels. For all statistically significant results, model outputs are given in Table 5.
Both Group 1 and Group 2 were significantly different from Group 3. The error type factor was not significant. The ‘Group 1 by target error’ interaction reached significance, while the ‘Group 2 by target error’ interaction did not. In addition, multiple comparisons (Tukey’s contrasts) showed significant differences among all three groups.
The upper-intermediate Group 1 made the fewest errors, and, as we already noted above, the beginner Group 3 made fewer errors than the beginner Group 2, but read more slowly. The interactions show that Group 1 treated target errors differently than Group 3 (namely, they were more difficult to judge than control errors, as they are for native speakers), while Group 2 did not differ from Group 3. We can conclude that the upper-intermediate Group 1 developed a native-like sensitivity to grammaticality illusions that is absent in the beginner groups. However, this sensitivity is evident only in offline, but not in online measures.
General Discussion
The central question in the field of L2 processing is whether mechanisms and strategies are the same for L1 and L2. In the introduction, we presented different approaches arguing for opposite answers to this question. We suggested that this question may be addressed by focusing on processing problems characteristic of native speakers. If L2 learners attain native-like processing efficiency at a certain proficiency level, they may do so by relying on non-native-like mechanisms and strategies. Developing native-like problems is definitely not the goal of the acquisition process – they are likely to be a by-product of using the same mechanisms as those of the native speakers.
We turned to grammaticality illusions as a well-studied type of processing problem. Slioussar and Cherepovskaia (2014, 2021) demonstrated that the native speakers of Russian were likely to miss particular case errors in the context of a morphologically ambiguous adjective. This was evident in word-by-word RTs and in GJs, both in online and offline measures. The experiment we conducted demonstrated that at the beginner level, L2 readers differed from native speakers in online and offline measures. The online pattern will be discussed below, while offline, there were no significant differences across conditions; this is exactly what we expect in the absence of grammaticality illusions. At the upper-intermediate level, the online pattern remained the same, but a native-like pattern emerged in GJs. We interpret this as evidence in favor of similar processing mechanisms that L2 learners can rely on once the mental representation of nominal inflection develops to a certain extent.
As for the differences between online and offline measures, all models postulating the same processing mechanisms for L1 and L2 recognize that L2 processing is cognitively more demanding, due to lower automaticity and speed, the limitations in lexical access, etc. Several previous studies demonstrated that L2 learners perform better in offline tasks than in online ones (e.g., Hopp, 2010; López Prego and Gabriele, 2014). In these studies, “better” meant “more native-like.” In the present study, we show that L2 learners are more native-like offline even when this does not mean better performance – i.e., when being more native-like means being susceptible to grammaticality illusions.
Now let us turn to online measures, starting with a general picture. Many studies have found differences between different case forms presented in isolation in a variety of languages, including Russian (e.g., Lukatela et al., 1978; Niemi et al., 1991; Gor et al., 2017, 2019; Vasilyeva, 2018). These differences could be explained by the type frequency (even when the token frequency was controlled for) and by syncretism. Gor et al. (2017, 2019), who compared L1 and L2 speakers of Russian, discovered that some distinctions found for native speakers are not (always) observed for L2 learners. In particular, all participants processed nominative forms faster than oblique case forms, and native speakers also processed genitive forms faster than instrumental ones (genitive is the most frequent of the oblique cases). L2 learners showed similar differences only at a certain proficiency level and in a certain experimental design specifically drawing attention to inflectional morphology.
Hyönä et al. (2002), working with Finnish, compared form processing in isolation and in a sentential context and found that many distinctions found in the former situation disappear in the latter. Experiments on Russian (Slioussar and Cherepovskaia, 2014, 2021; Chernova et al., 2020) confirm this generalization. In a sentential context, only sentence-level factors played a role: grammaticality and factors like grammaticality illusions. In particular, in the absence of grammaticality illusions, different ungrammatical forms were processed equally slowly, independently of their case frequency and other properties.
Non-native speakers demonstrate the opposite pattern. While the previous studies showed that they are less sensitive to different characteristics of case forms in isolation than L1 speakers are, our study demonstrates that they are more sensitive to these characteristics in a sentential context. We hypothesize that native speakers retrieve some form characteristics automatically (hence the effects in isolation), but, when parsing a sentence, they can predict a particular case, which makes these characteristics irrelevant. Non-native speakers are less effective at both tasks, which produce the mirror picture.
In our study, we compared genitive, dative, and locative plural forms and found that both beginner and upper-intermediate L2 learners processed genitive forms significantly slower than locative and dative ones. In a study comparing different oblique case forms in isolation (Vasilyeva, 2018), genitive and accusative forms produced the shortest reaction times, because these cases are much more frequent than other oblique cases.3 This factor did not play a role for our L2 participants. As for the order of acquisition, L2 learners of Russian acquire genitive after locative, but before dative (e.g., Rubinstein, 1995a,b; Cherepovskaia et al., 2021).
As far as we can judge, the only factor that can explain this pattern is morphological complexity: how many affixes are associated with a particular form and how complex the rules are that regulate the choice among them. Locative and dative plural have one affix each, with two different orthographic variants depending on the last consonant of the stem. Genitive plural has four affixes with different orthographic variants, and the choice between them depends not only on the last consonant of the stem, but also on the inflectional class and subclass and some other factors. This factor was never found to play a role in L1 processing studies – native speakers use these rules very efficiently.8 It would be very interesting to find out whether other properties of noun forms (including case frequency or the order of acquisition) may influence online L2 processing patterns, depending on the experimental design (the task, materials, etc.). But, since the current study is the first processing study comparing different case forms in a sentential context for L2 Russian, further experiments are necessary to answer these questions.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics Statement
Ethical review and approval were not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
NS came up with the general idea of the study and supervised it at all stages. ER conducted the experiment with the upper-intermediate learners of Russian. NC conducted the experiment with two beginner groups. NC and NS wrote the paper. All authors contributed to the article and approved the submitted version.
Funding
The study was partially supported by the Russian Ministry of Science and Higher Education (the research project 075-15-2020-793).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We are especially grateful to Prof. Kira Gor and to Varvara Magomedova for their invaluable advice and to Prof. Joan Castellvi and Prof. Andrey Zaynuldiniv for their help with data collection.
Footnotes
1. ^For all inanimate nouns in plural, accusative forms coincide with nominative, while instrumental forms are one letter longer than all other forms, so dative is the optimal choice.
3. ^Collecting online and offline data separately would be more challenging for two reasons. Firstly, it is difficult to find two perfectly comparable groups of L2 learners. Secondly, our pilot experiment with more filler sentences and comprehension questions turned out to be difficult even for upper-intermediate participants, so recruiting less proficient participants would be problematic.
5. ^Slioussar and Samojlova (2015) provide the following counts based on the Russian National Corpus (www.ruscorpora.ru): 30% nominative forms, 26% genitive forms, 5% dative forms, 19% accusative forms, 9% instrumental forms, and 10% locative forms. Other frequency counts based on different corpus samples can be found in Kopotev (2008), but the order of oblique cases remains the same.
6. ^Unlike with RTs, model outputs are not presented in a separate table because there are much fewer comparisons.
7. ^Since we are looking at two factors with three levels and their interactions, running a mixed-effects regression with a different reference level, as above, was not an option here.
8. ^Native speakers also acquire these rules very early and without major problems, while for L2 learners’ morphological complexity is one of the crucial factors that influence case acquisition (Rubinstein, 1995a,b; Cherepovskaia et al., 2021).
References
Badecker, W., and Kuminiak, F. (2007). Morphology, agreement and working memory retrieval in sentence production: evidence from gender and case in Slovak. J. Mem. Lang. 56, 65–85. doi: 10.1016/j.jml.2006.08.004
Baerman, M., Brown, D. P., and Corbett, G. G. (2005). The Syntax-Morphology Interface: A Study of Syncretism. Cambridge: Cambridge University Press.
Basnight-Brown, D. M., Chen, L., Hua, S., Kostić, A., and Feldman, L. B. (2007). Monolingual and bilingual recognition of regular and irregular English verbs: sensitivity to form similarity varies with first language experience. J. Mem. Lang. 57, 65–80. doi: 10.1016/j.jml.2007.03.001
Bates, D., Maechler, M., Bolker, B., and Walker, S. (2015). lme4: Linear Mixed-Effects Models Using Eigen and S4. R package version 1.1–8. Available at: http://CRAN.R-project.org/package=lme4/ (Accessed January 10, 2021).
Blevins, J. (1995). Syncretism and paradigmatic opposition. Linguist. Philos. 18, 113–152. doi: 10.1007/BF00985214
Bobaljik, J. (2002). “Syncretism without paradigms: remarks on Williams 1981, 1994,” in Yearbook of Morphology 2001. eds. G. Booij and J. van Marle (Dordrecht: Kluwer), 53–85.
Bock, J. K., and Miller, C. A. (1991). Broken agreement. Cogn. Psychol. 23, 45–97. doi: 10.1016/0010-0285(91)90003-7
Bretz, F., Hothorn, T., and Westfall, P. (2010). Multiple Comparisons Using R. Boca Raton: CRC Press.
Cherepovskaia, N., Slioussar, N., and Denissenko, A. (2021). Acquisition of the nominal case system in Russian as a second language. Second Lang. Res. 1–26. doi: 10.1177/0267658320988058
Chernova, D., Alexeeva, S., and Slioussar, N. (2020). Osobennosti orfografičeskoj obrabotki padežnyx form russkix suščestvitel'nyx v kontekste predloženija [Proceesing case forms of Russian nouns in a sentential context]. Vestn. Tomsk. Gos. Univ. 454, 45–54. doi: 10.17223/15617793/454/6
Clahsen, H., and Felser, C. (2006a). Continuity and shallow structures in language processing: a reply to our commentators. Appl. Psycholinguist. 27, 107–126. doi: 10.1017/S0142716406060206
Clahsen, H., and Felser, C. (2006b). Grammatical processing in language learners. Appl. Psycholinguist. 27, 3–42. doi: 10.1017/S0142716406060024
Clahsen, H., and Felser, C. (2006c). How native-like is non-native language processing? Trends Cogn. Sci. 10, 564–570. doi: 10.1016/j.tics.2006.10.002
Clahsen, H., Felser, C., Neubauer, K., Sato, M., and Silva, R. (2010). Morphological structure in native and non-native language processing. Lang. Learn. 60, 21–43. doi: 10.1111/j.1467-9922.2009.00550.x
Clifton, C. Jr., Frazier, L., and Deevy, P. (1999). Feature manipulation in sentence comprehension. Riv. Linguist. 11, 11–39.
Coughlin, C. E., and Tremblay, A. (2015). Morphological decomposition in native and non-native French speakers. Biling. Lang. Congn. 18, 524–542. doi: 10.1017/S1366728914000200
Cunnings, I. (2017). Parsing and working memory in bilingual sentence processing. Biling. Lang. Congn. 20, 659–678. doi: 10.1017/S1366728916000675
Dillon, B., Mishler, A., Sloggett, S., and Phillips, C. (2013). Contrasting intrusion profiles for agreement and anaphora: experimental and modeling evidence. J. Mem. Lang. 69, 85–103. doi: 10.1016/j.jml.2013.04.003
Drummond, A. (2013). Ibex Farm. Available at: http://spellout.net/ibexfarm/ (Accessed January 10, 2021).
Eberhard, K. M., Cutting, J. C., and Bock, K. (2005). Making syntax of sense: number agreement in sentence production. Psychol. Rev. 112, 531–559. doi: 10.1037/0033-295X.112.3.531
Feldman, L. B., Kostić, A., Basnight-Brown, D. M., Filipović Ðurdević, D., and Pastizzo, M. J. (2010). Morphological facilitation for regular and irregular verb formations in native and non-native speakers: little evidence for two distinct mechanisms. Biling. Lang. Congn. 13, 119–135. doi: 10.1017/S1366728909990459
Franck, J., Lassi, G., Frauenfelder, U. H., and Rizzi, L. (2006). Agreement and movement: A syntactic analysis of attraction. Cognition 101, 173–216.
Franck, J., Vigliocco, G., and Nicol, J. (2002). Subject–verb agreement errors in French and English: the role of syntactic hierarchy. Lang. Cogn. Process. 17, 371–404. doi: 10.1080/01690960143000254
Gor, K., Chrabaszcz, A., and Cook, S. (2017). Processing of native and non-native inflected words: beyond affix stripping. J. Mem. Lang. 93, 315–332. doi: 10.1016/j.jml.2016.06.014
Gor, K., Chrabaszcz, A., and Cook, S. (2019). A case for agreement. Processing of case inflection by early and late learners. Linguist Approaches Biling. 9, 6–41. doi: 10.1075/lab.16017.gor
Gor, K., and Jackson, S. (2013). Morphological decomposition and lexical access in a native and second language: a nesting doll effect. Lang. Cogn. Process. 28, 1065–1091. doi: 10.1080/01690965.2013.776696
Hartsuiker, R. J., Schriefers, H. J., Bock, K., and Kikstra, G. M. (2003). Morphophonological influences on the construction of subject–verb agreement. Mem. Cogn. 31, 1316–1326. doi: 10.3758/BF03195814
Hopp, H. (2006). Syntactic features and reanalysis in near-native processing. Second. Lang. Res. 22, 369–397. doi: 10.1191/0267658306sr272oa
Hopp, H. (2010). Ultimate attainment in L2 inflection: performance similarities between non-native and native speakers. Lingua 120, 901–931. doi: 10.1016/j.lingua.2009.06.004
Hopp, H. (2014). Individual differences in the second language processing of object–subject ambiguities. Appl. Psycholinguist. 36, 129–173. doi: 10.1017/S0142716413000180
Hoshino, N., Dussias, P. E., and Kroll, J. F. (2010). Processing subject–verb agreement in a second language depends on proficiency. Biling. Lang. Congn. 13, 87–98. doi: 10.1017/S1366728909990034
Hyönä, G., Vainio, S., and Laine, M. (2002). A morphological effect obtained for isolated words, but not for words in sentence context. Eur. J. Cogn. Psychol. 14, 417–433. doi: 10.1080/09541440143000131
Jackson, C. (2010). “The processing of subject-object ambiguities by English and dutch L2 learners of German,” in Research in Second Language Processing and Parsing. eds. B. Van Patten and J. Jegerski (Amsterdam: John Benjamins), 207–230.
Jegerski, J. (2012). The processing of subject–object ambiguities in native and near-native Mexican Spanish. Biling. Lang. Congn. 15, 721–735. doi: 10.1017/S1366728911000654
Jegerski, J. (2016). Number attraction effects in near-native Spanish sentence comprehension. Stud. Second. Lang. Acquis. 1, 5–33. doi: 10.1017/S027226311400059X
Just, M. A., Carpenter, P. A., and Woolley, J. D. (1982). Paradigms and processes in reading comprehension. J. Exp. Psychol. Gen. 3, 228–238. doi: 10.1037//0096-3445.111.2.228
Kaan, E., Ballantyne, J. C., and Wijnen, F. (2015). Effects of reading speed on second-language sentence processing. Appl. Psycholinguist. 36, 799–830. doi: 10.1017/S0142716413000519
Kagan, O., Miller, F., and Kudyma, G. (2005). V puti [On the way]: Russian Grammar in Context. 2nd Edn. Upper Saddle River, NJ: Pearson Prentice Hall.
Kempe, V., and Mac Whinney, B. (1998). The acquisition of case marking by adult learners of Russian and German. Stud. Second. Lang. Acquis. 20, 543–587. doi: 10.1017/S0272263198004045
Kempe, V., and Mac Whinney, B. (1999). Processing of morphological and semantic cues in Russian and German. Lang. Cogn. Process. 14, 129–171. doi: 10.1080/016909699386329
Kopotev, M. V. (2008). “K postroeniju častotnoj grammatiki russkogo jazyka: Padežnaja sistema po korpusnym dannym [Towards the construction of a frequency grammar of the Russian language: The case system according to corpus data],” in Slavica Helsingiensia 34. eds. A. Mustajoki, M. V. Kopotev, L. A. Birjulin, and E. J. Protasova (Helsinki: University of Helsinki), 136–151.
Kuznetsova, A., Brockhoff, P. B., and Christensen, R. H. B. (2015). lmerTest: Tests in Linear Mixed Effects Models. R package version 2.0-25. Available at: http://CRAN.Rproject.org/package=lmerTest (Accessed January 10, 2021).
Lago, S., and Felser, C. (2018). Agreement attraction in native and non-native speakers of German. Appl. Psycholinguist. 39, 619–647. doi: 10.1017/S0142716417000601
Lago, S., Gračanin-Yuksek, M., Şafak, D. F., Demir, O., Kırkıcı, B., and Felser, C. (2019). Straight from the horse's mouth: agreement attraction effects with Turkish possessors. Linguist Approaches Biling. 9, 398–426. doi: 10.1075/lab.17019.lag
Laurinavichyute, A., and Vasishth, S. (2016). “Agreement attraction in person is symmetric,” in Poster Presented at the 29th CUNY Sentence Processing Conference; March 3-5, 2016.
Lekić, M. D., Davidson, D. E., and Gor, K. (2008). Russian Stage One: Live From Russia. 2nd Edn. Vol. 1. Dubuque, IA: Kendall/Hunt Publishing Company.
Lewis, R. L., and Vasishth, S. (2005). An activation-based model of sentence processing as skilled memory retrieval. Cogn. Sci. 29, 375–419. doi: 10.1207/s15516709cog0000_25
Lim, H. L., and Christianson, K. (2015). Second language sensitivity to agreement errors: evidence from eye movements during comprehension and translation. Appl. Psycholinguist. 36, 1283–1315. doi: 10.1017/S0142716414000290
López Prego, B., and Gabriele, A. (2014). Examining the impact of task demands on morphological variability in native and non-native Spanish. Linguist Approaches Biling. 4, 192–221. doi: 10.1075/lab.4.2.03lop
Lorimor, H., Bock, K., Zalkind, E., Sheyman, A., and Beard, R. (2008). Agreement and attraction in Russian. Lang. Cogn. Process. 23, 769–799. doi: 10.1080/01690960701774182
Lubensky, S., McLellan, L., Ervin, G. L., and Jarvis, D. (2001). Nachalo [Beginning]. Book One. New York: McGraw-Hill Companies, Inc.
Lukatela, G., Mandić, Z., Gligorijević, B., Kostić, A., Savić, M., and Turvey, M. T. (1978). Lexical decision for inflected nouns. Lang. Speech 21, 166–173. doi: 10.1177/002383097802100203
McDonald, J. (2006). Beyond the critical period: processing-based explanations for poor grammaticality judgement performance by late second language learners. J. Mem. Lang. 55, 381–401. doi: 10.1016/j.jml.2006.06.006
McDonald, J., and Roussel, C. (2010). Past tense grammaticality judgment and production in non-native and stressed native English speakers. Biling. Lang. Congn. 13, 429–448. doi: 10.1017/S1366728909990599
Müller, G. (2011). Syncretism without underspecification: the role of leading forms. Word Structure 4, 53–103. doi: 10.3366/word.2011.0004
Nicol, J., and Greth, D. (2003). Production of subject–verb agreement in Spanish as a second language. Exp. Psychol. 50, 196–203. doi: 10.1026//1617-3169.50.3.196
Nicol, J., and Wilson, R. (1999). “Agreement and case-marking in Russian: a psycholinguistic investigation of agreement errors in production,” in The Eighth Annual Workshop on Formal Approaches to Slavic Languages. eds. T. H. King and I. Sekerina (Ann Arbor, MI: Michigan Slavic Publications), 314–327.
Niemi, J., Laine, M., and Koivuselka-Sallinen, P. (1991). “Recognition of Finnish polymorphemic words: effects of morphological complexity and inflection vs. derivation,” in Papers from the Eighteenth Finnish Conference of Linguistics. ed. J. Niemi. May 23-25, 1991; (Joensuu: University of Joensuu), 114–132.
Nummikoski, M. (1996). Troika: A Communicative Approach to Russian Language, Life and Culture. New York: John Wiley & Sons, Inc.
Pearlmutter, N. J., Garnsey, S. M., and Bock, K. (1999). Agreement processes in sentence comprehension. J. Mem. Lang. 41, 427–456. doi: 10.1006/jmla.1999.2653
Portin, M., Lehtonen, M., Harrer, G., Wande, E., Niemi, J., and Laine, M. (2008). L1 effects on the processing of inflected nouns in L2. Acta Psychol. 128, 452–465. doi: 10.1016/j.actpsy.2007.07.003
Portin, M., Lehtonen, M. H., and Laine, M. (2007). Processing of inflected nouns in late bilinguals. Appl. Psycholinguist. 28, 135–156. doi: 10.1017/S014271640607007X
Prévost, P., and White, L. (2000). Missing surface inflection or impairment in second language acquisition? evidence from tense and agreement. Second. Lang. Res. 16, 103–133. doi: 10.1191/026765800677556046
Quirk, R., Greenbaum, S., Leech, G., and Svartvik, J. (1972). A Grammar of Contemporary English. London: Longman.
Ratcliff, R. (1993). Methods for dealing with reaction time outliers. Psychol. Bull. 114, 510–532. doi: 10.1037/0033-2909.114.3.510
Rubinstein, G. (1995a). On acquisition of Russian cases by American classroom learners. IRAL Int. Rev. Appl. Linguist Lang. Teach. 33, 10–34.
Rubinstein, G. (1995b). On case errors made in oral speech by American learners of Russian. Slav. East Eur. J. 39, 408–429.
Rusakova, M. V. (2013). Ėlementy antropocentričeskoj grammatiki russkogo jazyka [Elements of Anthropocentric Grammar of the Russian Language]. Moscow: Languages of the Slavic Culture.
Sabourin, L., and Haverkort, M. (2003). “Neural substrates of representation and processing of a second language,” in The Lexicon-Syntax Interface in Second Language Acquisition. eds.R. Van Hout, A. Hulk, F. Kuiken, and R. Towell (Amsterdam: Benjamins), 175–195.
Segalowitz, N. (2003). “Automaticity and second languages,” in The Handbook of Second Language Acquisition. eds. C. Doughty and M. Long (Oxford: Blackwell), 382–408.
Segalowitz, N., and Hulstijn, J. (2005). “Automaticity in bilingualism and second language learning,” in Handbook of Bilingualism: Psycholinguistics Approaches. eds. J. F. Kroll and A. M. B. de Groot(New York, NY, US: Oxford University Press), 371–388.
Slabakova, V. (2009). “What is easy and what is hard to acquire in a second language.” in Proceedings from GLASA’09: The 10th Generative Approaches to Second Language Acquisition Conference. eds. M. Bowels, T. Ionin, S. Montrul, and A. Tremblay (Somerville, MA: Cascadilla Proceedings Project), 290–294.
Slioussar, N. (2018). Forms and features: the role of syncretism in number agreement attraction. J. Mem. Lang. 101, 51–63. doi: 10.1016/j.jml.2018.03.006
Slioussar, N., and Cherepovskaia, N. (2014). “Case errors in processing: evidence from Russian,” in Formal Approaches to Slavic Linguistics: The First Hamilton Meeting 2013. eds. C. Chapman, O. Kit, and I. Kučerova (Ann Arbor, MI: Michigan Slavic Publications), 319–338.
Slioussar, N., and Cherepovskaia, N. (2021). Grammaticality Illusions in Case Agreement Processing. Moscow, MS: Higher School of Economics.
Slioussar, N., and Malko, A. (2016). Gender agreement attraction in Russian: production and comprehension evidence. Front. Psychol. 7:1651. doi: 10.3389/fpsyg.2016.01651
Slioussar, N., and Samojlova, M. (2015). “Častotnosti različnyx grammatičeskix xarakteristik i okončanij u suščestvitel’nyx russkogo jazyka [Frequencies of different grammatical features and inflectional affixes in Russian nouns].” in Proceedings of the Conference ‘Dialogue’; May 27-30, 2015. Available at: www.dialog21.ru/digests/dialog2015/materials/pdf/SlioussarNASamoilovaMV.pdf
Slioussar, N., Stetsenko, A., and Matyushkina, T. (2017). “Producing case errors in Russian,” in Formal Approaches to Slavic Linguistics: The New York Meeting 2015. eds. Y. Oseki, M. Esipova, and S. Harvers (Ann Arbor, MI: Michigan Slavic Publications), 363–379.
Solomon, E. S., and Pearlmutter, N. J. (2004). Semantic integration and syntactic planning in language production. Cogn. Psychol. 49, 1–46. doi: 10.1016/j.cogpsych.2003.10.001
Sorace, A. (2011). Pinning down the concept of ‘interface’ in bilingualism. Linguist Approaches Biling. 1, 1–33. doi: 10.1075/lab.1.1.01sor
Staub, A. (2009). On the interpretation of the number attraction effect: response time evidence. J. Mem. Lang. 60, 308–327. doi: 10.1016/j.jml.2008.11.002
Staub, A. (2010). Response time distributional evidence for distinct varieties of number attraction. Cognition 114, 447–454. doi: 10.1016/j.cognition.2009.11.003
Tanner, D., Nicol, J., and Brehm, L. (2014). The time-course of feature interference in agreement comprehension: multiple mechanisms and asymmetrical attraction. J. Mem. Lang. 76, 195–215. doi: 10.1016/j.jml.2014.07.003
Ullman, M. (2015). “The declarative/procedural model: a neurobiologically motivated theory of first and second language,” in Theories in Second Language Acquisition: An Introduction. eds. B. Van Patten and J. Williams (New York, NY: Routledge), 135–158.
Ullman, M. (2018). Implications of the declarative/procedural model for improving second language learning: the role of memory enhancement techniques. Second. Lang. Res. 34, 39–65. doi: 10.1177/0267658316675195
Ullman, M. T., Corkin, S., Coppola, M., Hickok, G., Growden, J., and Koroshetz, W. (1997). A neural dissociation within language: evidence that the mental dictionary is part of declarative memory and that grammatical rules are processed by the procedural system. J. Cogn. Neurosci. 9, 289–299. doi: 10.1162/jocn.1997.9.2.266
Vasilyeva, M. (2018). “Russian case inflection: processing costs and benefits,” in Advances in Formal Slavic Linguistics 2016. eds. D. Lenertová, R. Meyer, R. Šimík, and L. Szucsich (Berlin: Language Science Press), 427–453.
Vigliocco, G., Butterworth, B., and Garrett, M. F. (1996). Subject–verb agreement in Spanish and English: differences in the role of conceptual constraints. Cognition 61, 261–298. doi: 10.1016/S0010-0277(96)00713-5
Vigliocco, G., Butterworth, B., and Semenza, C. (1995). Constructing subject–verb agreement in speech: The role of semantic and morphological factors. J. Mem. Lang. 34, 186–215. doi: 10.1006/jmla.1995.1009
Voeikova, M. (2011). Stanovlenie imeni. Rannie etapy usvoenija det’mi imennoj morfologii russkogo jazyka [The Development of the Noun. Early Stages of Russian Nominal Morphology Acquisition by Children]. Moscow: Znak.
Voeikova, M., and Gagarina, M. (2002). “MLU, first lexicon and the acquisition of case forms by two Russian children,” in Pre-and Protomorphology: Early Phases of Morphological Development in Nouns and Verbs. eds. M. D. Voeikova and W. U. Dressler (München: Lincom Europa), 115–131.
Wagers, M. W., Lau, E. F., and Phillips, C. (2009). Agreement attraction in comprehension: representations and processes. J. Mem. Lang. 61, 206–223. doi: 10.1016/j.jml.2009.04.002
Yanovich, I., and Fedorova, O. (2006). “Subject–verb agreement errors in Russian: head noun gender effect.” in Proceedings of the ‘Dialog 2006ʼ; May 31 – June 4, 2006. Available at: www.dialog-21.ru/digests/dialog2006/materials/html/Yanovich2.htm
Keywords: second language acquisition, sentence processing, grammaticality illusion, syncretism, case, Russian
Citation: Cherepovskaia N, Reutova E and Slioussar N (2021) Becoming Native-Like for Good or Ill: Online and Offline Processing of Case Forms in L2 Russian. Front. Psychol. 12:652463. doi: 10.3389/fpsyg.2021.652463
Edited by:
Juhani Järvikivi, University of Alberta, CanadaReviewed by:
Kaidi Lõo, University of Tartu, EstoniaNatalia Romanova, George Washington University, United States
Copyright © 2021 Cherepovskaia, Reutova and Slioussar. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Natalia Slioussar, slioussar@gmail.com