
Abstract
We propose a method of learning indicative conditional information. An agent learns conditional information by Jeffrey imaging on the minimally informative proposition expressed by a Stalnaker conditional. We show that the predictions of the proposed method align with the intuitions in Douven (Mind & Language, 27(3), 239–263 2012)’s benchmark examples. Jeffrey imaging on Stalnaker conditionals can also capture the learning of uncertain conditional information, which we illustrate by generating predictions for the Judy Benjamin Problem.







Similar content being viewed by others

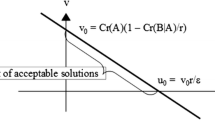
Notes
[4, p. 213].
[2, p. 247].
Cf. [14]. Note that Robert Stalnaker’s theory of conditionals aims to account for both indicative and counterfactual conditionals. We set the complicated issue of this distinction aside in this paper. However, we want to emphasise that Douven’s examples and the Judy Benjamin Problem only involve indicative conditionals.
Here as elsewhere in the paper, the strict relation w′< ww″ is defined as w′ ≤ ww″ and not w″ ≤ ww′
For Stalnaker’s presentation of his semantics see [15].
Cf. [11].
We assume here that there are only finitely many worlds. Note also that if α is possible, then there exists some wα.
We assume here that each world is distinguishable from any other world, i. e. for two arbitrary worlds, there is always a formula in \(\mathcal {L}\) such that the formula is true in one of the worlds, but false in the other. In other words, we consider no copies of worlds.
Cf. [9]. In personal communication, Benjamin Eva and Stephan Hartmann mentioned that the idea behind Jeffrey imaging is already used in artificial intelligence research to model the retrieval of information. [13, p. 3] mentions the name ‘Jeffrey imaging’ without writing down a corresponding formula. [1, p. 262] says that [13] suggested “a new variant of standard imaging called retrieval by Jeffrey’s logical imaging”. However, the formalisation of Jeffrey’s idea on p. 263 differs from mine in at least two respects. (i) An additional truth evaluation function occurs in the formalisation for determining whether a formula (i. e. ‘query’) is true at a world (i. e. ‘term’). (ii) Instead of a parameter k locally governing the probability kinematics of each possible world, Crestani simply uses a global constraint on the posterior probability distribution.
In other words, we consider “small” possible worlds models and do not allow for copies of worlds, i. e. worlds that satisfy the same formulas.
Here the question may arise why we do not simply learn conditional information by Jeffrey imaging on the material implication. A short answer will be provided in the Conclusion.
Notice that the assumption of no additional information literally excludes that there is an epistemic reason, i. e. some belief apart from [α > γ]min, to change the probability of the antecedent.
Douven [2] argues more precisely that the probability of the antecedent should only change if the antecedent is explanatorily relevant for the consequent. It is noteworthy that if the probability of the antecedent should intuitively change in one of Douven’s examples, the explanatory relations always involve beliefs in additional propositions (apart from the conditional) given by the example’s context description.
Cf. [2, p. 8].
Note that the Sundowners Example seems to be somewhat artificial. It seems plausible that upon hearing her sister’s conditional, Sarah would promptly ask “why?” in order to obtain some more contextual information, before setting her probability for sundowners and rain to 0. After all, she “thinks that they can always enjoy the view from inside”.
In [7], we extend the proposed method to the learning of causal information, which allows us to define an inference to the best explanation scheme, as Douven envisioned for the Ski Trip Example.
Cf. [17, pp. 376–379].
This paper and [7] overlap insofar the latter contains parts of the proposed method of learning conditional information as a constituent of the adapted method. In [7], only the adapted method for learning causal information is applied to Douven’s examples and the Judy Benjamin Problem; the proofs for Theorem 2 are not included.
References
Crestani, F. (1998). Logical imaging and probabilistic information retrieval. In Crestani, F., Lalmas, M., van Rijsbergen, C.J. (Eds.) Information Retrieval: Uncertainty and Logics: Advanced Models for the Representation and Retrieval of Information (pp. 247–279). Boston: Springer.
Douven, I. (2012). Learning conditional information. Mind & Language, 27(3), 239–263.
Douven, I., & Dietz, R. (2011). A puzzle about stalnaker’s hypothesis. Topoi, 30(1), 31–37.
Douven, I., & Pfeifer, N. (2014). Formal epistemology and the new paradigm psychology of reasoning. Review of Philosophy and Psychology, 5, 199–221.
Douven, I., & Romeijn, J.-W. (2011). A new resolution of the judy benjamin problem. Mind, 120(479), 637–670.
Gärdenfors, P. (1988). Knowledge in flux. Cambridge: MIT Press.
Günther, M. (2017). Learning conditional and causal information by jeffrey imaging on stalnaker conditionals. Organon F, 24(4), 456–486.
Hartmann, S., & Rad, S.R. (2017). Learning indicative conditionals. Unpublished manuscript, 1–28.
Jeffrey, R.C. (1965). The logic of decision. New York: Mc Graw-Hill.
Lewis, D.K. (1973). Causation. Journal of Philosophy, 70(17), 556–567.
Lewis, D.K. (1976). Probabilities of conditionals and conditional probabilities. The Philosophical Review, 85(3), 297–315.
Rott, H. (2000). Two dogmas of belief revision. Journal of Philosophy, 97, 503–522.
Sebastiani, F. (1998). Information retrieval, imaging and probabilistic logic. Computers and Artificial Intelligence, 17(1), 1–16.
Stalnaker, R.C. (1975). A theory of conditionals. In Sosa, E. (Ed.) Causation and Conditionals (pp. 165–179). OUP.
Stalnaker, R.C., & Thomason, R.H. (1970). A semantic analysis of conditional logic. Theoria, 36(1), 23–42.
Van Benthem, J., & Smets, S. (2015). Dynamic logics of belief change. In Van Ditmarsch, H., Halpern, J. Y., Van der Hoek, W., Kooi, B. (Eds.) Handbook of Logics for Knowledge and Belief, chapter 7 (pp. 299–368): College Publications.
van Fraassen, B.C. (1981). A problem for relative information minimizers in probability kinematics. The British Journal for the Philosophy of Science, 32(4), 375–379.
Acknowledgments
Thanks to Hannes Leitgeb, Stephan Hartmann, Igor Douven, and Hans Rott for helpful discussions. Special thanks go to an anonymous referee for very constructive comments. I am grateful that I had the opportunity to present parts of this paper and obtain feedback at the Munich Centre for Mathematical Philosophy (LMU Munich), at the Inaugural Conference of the East European Network for Philosophy of Science (New Bulgarian University), at the International Rationality Summer Institute 2016 (Justus Liebig University), at the Centre for Advanced Studies Workshop on “Learning Conditionals” (LMU Munich), at the University of Bayreuth and the University of British Columbia. This research is supported by the Graduate School of Systemic Neurosciences.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 A Possible Worlds Model of the Jeweller Example
Following the presentation in [5], we consider the Jeweller Example.
Example 5
The Jeweller Example ([5, p. 654]) A jeweller has been shot in his store and robbed of a golden watch. However, it is not clear atthis point what the relation between these two events is; perhaps someone shot the jewellerand then someone else saw an opportunity to steal the watch. Kate thinks there is somechance that Henry is the robber (R). On the other hand, she strongly doubts that he iscapable of shooting someone, and thus, that he is the shooter (S). Now the inspector, afterhearing the testimonies of several witnesses, tells Kate:
As a result, Kate becomes more confident that Henry is not the robber, whilst her probability forHenry having shot the jeweller does not change.
We model Kate’s belief state as the Stalnaker model \(\mathcal {M}_{St} = \langle W, R, \le , \le ^{\prime } V \rangle \) depicted in Fig. 8. W contains four elements covering the possible events of R,¬R,S,¬S, where R stands for “Henry is the robber”, and S for “Henry has shot the jeweller”. The example suggests that 0 < P(R) < 1 and P(S) = 𝜖 for a small 𝜖, and thus P(¬S) = 1 − 𝜖. The prescribed intuitions are that P∗(R) < P(R)and P∗(S) = P(S). We know about Kate’s degrees of belief before receiving the conditional information that 0 < P(w1) + P(w2) < 1 and P(w1) + P(w3) = 𝜖, as well as P(w2) + P(w4) = 1 − 𝜖. Note that Kate is ‘almost sure’ that ¬S, and thus we may treat ¬S as ‘almost factual’ information.

A Stalnaker model for Kate’s belief state in the Jeweller Example. The blue arrow indicates the unique w((R>S)∧¬S)-world under ≤. The red arrows indicate that each world is its most similar ¬((R > S) ∧¬S)-world under ≤′. The teal arrows represent the transfer of (1 − 𝜖) ⋅ P(w), whilst the violet arrows represent the transfer of 𝜖 ⋅ P(w)
Kate receives certain conditional information. She learns the minimally informative proposition [R > S] = {w1, w3, w4} such that P(R > S) = PR(S) = 1. By the law of total probability, P(R > ¬S) = PR(¬S) = 0. Taking her uncertain but almost factual information into account, Kate learns in total the minimally informative proposition [(R > S) ∧¬S], which is identical to {w4}. By P(R > S) = 1, P((R > S) ∧¬S) = P(¬S) = 1 − 𝜖. Note the tension expressed in P((R > S) ∧¬S) = 1 − 𝜖. It basically says that S is almost surely not the case and, under the supposition of R, we exclude the possibility of ¬S. Intuitively, the thought expressed by this statement should cast doubt as to whether R is the case.
By ¬((R > S) ∧¬S) ≡ (R > ¬S) ∨ S, we also know that P(R > ¬S) ∨ S) = 𝜖. Note that the proposition [(R > S) ∧¬S] = {w4}(interpreted as minimally informative) specifies a similarity order ≤ such that w(R>S)∧¬S = w4 for all w. In contrast, the proposition [(R > ¬S) ∨ S] is minimally informative in a strong sense, since it does not exclude any world w. Hence, the ‘maximally inclusive’ proposition [(R > ¬S) ∨ S] = {w1, w2, w3, w4} specifies a similarity order ≤′≠ ≤according to which w(R>¬S)∨S = w for each w.
We apply now Jeffrey imaging to the Jeweller Example, where k = 1 − 𝜖.
We obtain the following probability distribution after learning:
The results almost comply with the prescribed intuitions. The intuition concerning the degree of belief in R is met: P∗(R) < P(R), since \(P^{*}_{1 - \epsilon }(w_{1}) + P^{*}_{1 - \epsilon }(w_{2}) < P(w_{1}) + P(w_{2})\). The intuition concerning the degree of belief in S is ‘almost’ met: \(P^{*}_{1 - \epsilon }(S) \approx P(S)\), for P(w1) + P(w3) = 𝜖 and \(P^{*}_{1 - \epsilon }(w_{1}) + P^{*}_{1 - \epsilon }(w_{3}) = P(w_{1}) \cdot \epsilon + P(w_{3}) \cdot \epsilon \approx \epsilon \). In words, the method gives us the result that Kate is now pretty sure that Henry is neither the shooter nor the robber.
Rights and permissions
About this article

Cite this article
Günther, M. Learning Conditional Information by Jeffrey Imaging on Stalnaker Conditionals. J Philos Logic 47, 851–876 (2018). https://doi.org/10.1007/s10992-017-9452-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10992-017-9452-z