
Abstract
Scientists routinely solve the problem of supplementing one’s store of variables with new theoretical posits that can explain the previously inexplicable. The banality of success at this task obscures a remarkable fact. Generating hypotheses that contain novel variables and accurately project over a limited amount of additional data is so difficult—the space of possibilities so vast—that succeeding through guesswork is overwhelmingly unlikely despite a very large number of attempts. And yet scientists do generate hypotheses of this sort in very few tries. I argue that this poses a dilemma: either the long history of scientific success is a miracle, or there exists at least one method or algorithm for generating novel hypotheses with at least limited projectibility on the basis of what’s available to the scientist at a time, namely a set of observations, the history of past conjectures, and some prior theoretical commitments. In other words, either ordinary scientific success is miraculous or there exists a logic of discovery at the heart of actual scientific method.


Similar content being viewed by others



Notes
It is often ambiguous whether the stages are supposed to be temporal or logical. See, e.g., (Hoyningen-Huene 2006).
This is actually one of three characterizations Curd considers. He deems this the least plausible of the three.
That isn’t quite fair if one understands abduction in Peirce’s sense. Peirce took ‘guessing’, the inception of a new idea, to be a stage of abduction (Tschaepe 2014). However, he seems to have thought that guessing is not rationally analyzable. Those who have touted abduction as the logic of ‘discovery’ (e.g., (Hanson 1961)) often ignore the actual stage of guessing, or assume a trivial mechanism of generation, as in King et al. (2004).
Kelly (1987) actually refers to such a method as a “generation procedure” and reserves the singular term “the logic of discovery” to refer to the study of all such procedures. My references to a logic of discovery are equivalent to Kelly’s talk of “a generation procedure.”
My use of this term is a slightly unfaithful replication of Kelly’s (1987).
Note that Laudan considers only the confirmationist subset of consequentialist approaches to theory justification. Falsificationist theories are thus ruled out of consideration.
The insistence on a recursively enumerable suitability relation can be dropped. It turns out that “[f]or any nonempty degree of uncomputability, there are infinitely many suitability relations...properly of that degree for which there is a strongly adequate hypothesis generation machine”(Kelly 1987, p. 449).
Curiously, these models seem to be the only ones to garner significant attention amongst philosophers of science, e.g., (Gillies 1996).
Note that any path through such a tree is equivalent to some sentence in disjunctive normal form.
Using ‘kernel methods’ that essentially apply a nonlinear transformation to the feature space to get a new space that is linearly separable.
The naive Bayes classifier is also one of the oldest (Maron and Kuhns 1960).
Obviously, neither Hempel nor Laudan could have been aware of all of the methods reviewed here when they framed their objections, as many are recent inventions. But enough—such as decision trees, naive Bayes classifiers, and (for Laudan at least) the BACON lineage of heuristic search algorithms—were around by the time they penned their objections.
Two of the most prominent are the mixture of Gaussians and independent component analysis (ICA) algorithms.
Fig. 2 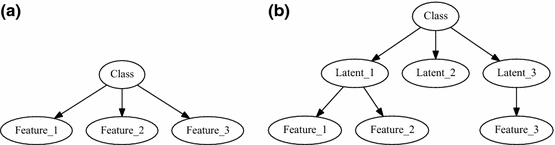
a A representation of a naive Bayes model as a directed graph. b A hierarchical naive Bayes (HNB) model with a single layer of latent variables
Let S be a set. A \(\sigma \)-algebra is a non-empty set \(\varSigma \) such that: (1) S is in \(\varSigma \), (2) if A is in \(\varSigma \) then so is the complement of A, and (3) the union of any sequence of elements of \(\varSigma \) is in \(\varSigma \). A measure is a function from \(\varSigma \) to the positive real numbers such that the null set maps to zero and such that the measure of the union of any finite or countably infinite set of disjoint members of \(\varSigma \) is equal to the sum of the measures of each set alone
In a minority of cases, the definition of a variable (not substantive knowledge of its possible values) ensures that the space of logically possible values it can assume is bounded. For example, celestial longitude can only take on values between 0 and 360 degrees. In those cases, the argument of this section does not go through; there will be some finite, nonzero probability of guessing a new value correctly. I stress, however, that most physical variables take on an unbounded range of possible values.
For technical reasons, it’s easier to consider left closed, right open intervals. The claims made in the text presume intervals of this sort.
For various sorts of anti-realist, this is a plausible assumption, since hypotheses are individuated by their empirical consequences. Thus, each prediction counts for one hypothesis. The realist, however, individuates hypotheses based on what they say concerning observable and unobservable entities. In that case, I have perhaps made a dubious assumption. But no more can be said unless we know something about how to define the set of possible hypotheses and what to treat as equal regions of hypotheses.
There is no probability measure obeying the Kolmogorov axioms of probability that is uniform over the entire real line. But one can assign a measure over the real line and ask about the relative size of subsets of the reals with respect to that measure.
I do not intend to concede this point. As Penrose (1994) points out, we can represent and reason about uncomputable functions. To say there is nothing worth calling a logic of discovery given an uncomputable function that otherwise has all of the features of such a logic requires an argument. Presumably, such an argument would turn on the claim that to count as a logic of discovery, it must be possible to consciously implement the procedure, and that this can only be done for computable functions. Whatever we do that’s uncomputable, it is not and cannot be conscious, hence the talk about happy guesses and strokes of genius.

References
Battle, A., Jonikas, M. C., Walter, P., Weissman, J. S., & Koller, D. (2010). Automated identification of pathways from quantitative genetic interaction data. Molecular Systems Biology, 6(1), 1–13. doi:10.1038/msb.2010.27.
Bengio, Y. (2009). Learning deep architectures for AI. Foundations and Trends in Machine Learning, 2(1), 1–127. doi:10.1561/2200000006.
Bishop, C. (2007). Pattern recognition and machine learning. New York: Springer.
Breiman, L., Friedman, J., Stone, C. J., & Olshen, R. A. (1984). Classification and regression trees (1st ed.). Boca Raton: Chapman and Hall/CRC.
Carmichael, R.D. (1922). The Logic of Discovery. The Monist, 32(4), 569–608. http://www.jstor.org/stable/27900927.
Caschera, F., Gazzola, G., Bedau, M. A., Bosch Moreno, C., Buchanan, A., Cawse, J., et al. (2010). Automated discovery of novel drug formulations using predictive iterated high throughput experimentation. PLoS One, 5(1), e8546. doi:10.1371/journal.pone.0008546.
Craver, C. F., & Darden, L. (2013). In search of mechanisms: Discoveries across the life sciences. Chicago: University Of Chicago Press.
Curd, M. V. (1980). The logic of discovery: An analysis of three approaches. In R. S. Cohen, M. W. Wartofsky, & T. Nickles (Eds.), Scientific discovery, logic, and rationality, Boston Studies in the Philosophy of Science D (Vol. 56, pp. 201–219). Dordrecht, Holland: Reidel Publishing Company.
Darden, L. (2002). Strategies for discovering mechanisms: Schema instantiation, modular subassembly, forward/backward chaining. Philosophy of Science, 69(S3), S354–S365. doi:10.1086/341858.
Darnell, S. J., Page, D., & Mitchell, J. C. (2007). An automated decision-tree approach to predicting protein interaction hot spots. Proteins: Structure, Function, and Bioinformatics, 68(4), 813–823. doi:10.1002/prot.21474.
Ebert-Uphoff, I., & Deng, Y. (2012). Causal discovery for climate research using graphical models. Journal of Climate, 25(17), 5648–5665. http://search.proquest.com/docview/1039516026.
Feferman, S. (1995). Penrose’s Gödelian argument. Psyche, 2, 21–32.
Feigenbaum, E. A., & Buchanan, B. G. (1993). DENDRAL and Meta-DENDRAL: roots of knowledge systems and expert system applications. Artificial Intelligence, 59(12), 233–240. doi:10.1016/0004-3702(93)90191-D, http://www.sciencedirect.com/science/article/pii/000437029390191D.
Flach, P. (2012). Machine learning: The art and science of algorithms that make sense of data. Cambridge: Cambridge University Press, http://proquest.safaribooksonline.com/9781107096394.
van Fraassen, B. C. (1990). Laws and symmetry. Oxford, NY: Oxford University Press.
Freno, A. (2009). Statistical machine learning and the logic of scientific discovery. Iris: European Journal of Philosophy & Public Debate, 1(2), 375–388. http://ezproxy.lib.vt.edu:8080/login?url=http://search.ebscohost.com/login.aspx?direct=true&db=hlh&AN=47365071&scope=site
Gillies, D. (1996). Artificial intelligence and scientific method. Oxford, NY: Oxford University Press.
Gutting, G. (1980). Science as discovery. Revue Internationale de Philosophie, 131, 26–48.
Han, L. Y., Zheng, C. J., Xie, B., Jia, J., Ma, X. H. & Zhu, F. (2007). Support vector machines approach for predicting druggable proteins: Recent progress in its exploration and investigation of its usefulness. Drug Discovery Today, 12(78), 304–313. doi:10.1016/j.drudis.2007.02.015, http://www.sciencedirect.com/science/article/pii/S1359644607000967.
Hanson, N. R. (1961). Patterns of discovery: An inquiry into the conceptual foundations of science. Cambridge: Cambridge University Press.
Hempel, C. G. (1966). Philosophy of natural science. Prentice-Hall foundations of philosophy series. Englewood Cliffs, NJ: Prentice-Hall.
Hoyningen-Huene, P. (2006). Context of discovery versus context of justification and Thomas Kuhn. In Schickore J, Friedrich S. (Eds.), Revisiting discovery and justification, no. 14 in Archimedes (pp. 119–131). Dordrecht: Springer. http://link.springer.com.ezproxy.lib.vt.edu/chapter/10.1007/1-4020-4251-5_8.
Kelly, K. T. (1987). The logic of discovery. Philosophy of Science, 54(3), 435–452. http://www.jstor.org/stable/187583
Kenny, L. C., Dunn, W. B., Ellis, D. I., Myers, J., Baker, P. N., & Kell, D. B. (2005). Novel biomarkers for pre-eclampsia detected using metabolomics and machine learning. Metabolomics, 1(3), 227–234. doi:10.1007/s11306-005-0003-1.
King, R. D., Whelan, K. E., Jones, F. M., Reiser, P. G. K., Bryant, C. H. & Muggleton, S. H. (2004). Functional genomic hypothesis generation and experimentation by a robot scientist. Nature, 427(6971), 247–252. doi:10.1038/nature02236, http://www.nature.com/nature/journal/v427/n6971/full/nature02236.html
Kleiner, S. A. (1993). The logic of discovery: A theory of the rationality of scientific research. Dordrecht, Boston: Kluwer Academic Publishers.
Langley, P., & Zytkow, J. M. (1989). Data-driven approaches to empirical discovery. Artificial Intelligence, 40, 283–312, doi:10.1016/0004-3702(89)90051-9, http://www.sciencedirect.com/science/article/pii/0004370289900519, 13.
Langley, P., Simon, H. A., Bradshaw, G., & Zytkow, J. M. (1987). Scientific discovery: Computational explorations of the creative processes. Cambridge, Mass: MIT Press.
Laudan, L. (1980). Why was the logic of discovery abandoned? In T. Nickles (Ed.), Scientific discovery, logic, and rationality, Boston Studies in the Philosophy of Science (Vol. 56, pp. 173–183). Dordrecht, Holland: D. Reidel Publishing Company.
Laudan, L. (1981). Science and hypothesis. Dordrecht, Holland: D. Reidel Publishing Company.
Maron, M. E., & Kuhns, J. L. (1960). On relevance, probabilistic Indexing and Information Retrieval. Journal of the ACM, 7(3), 216–244. doi:10.1145/321033.321035.
McLaughlin, R. (1982). Invention and Induction: Laudan, Simon and the logic of discovery. Philosophy of Science, 49, 198–211. doi:10.2307/186918, http://www.jstor.org/stable/186918, 2.
Medina, F., Aguila, S., Baratto, M. C., Martorana, A., Basosi, R., Alderete, J. B., & Vazquez-Duhalt, R. (2013). Prediction model based on decision tree analysis for laccase mediators. Enzyme and Microbial Technology, 52(1), 68–76. doi:10.1016/j.enzmictec.2012.10.009, http://www.sciencedirect.com/science/article/pii/S0141022912001779
Michalski, R., & Chilausky, R. (1980). Knowledge acquisition by encoding expert rules versus computer induction from examples: A case study involving soybean pathology. International Journal of Man-Machine Studies, 12(1), 63–87. doi:10.1016/S0020-7373(80)80054-X, http://www.sciencedirect.com/science/article/pii/S002073738080054X.
Mjolsness, E., & DeCoste, D. (2001). Machine learning for science: State of the art and future prospects. Science, 293(5537), 2051–2055. doi:10.1126/science.293.5537.2051, http://www.sciencemag.org/content/293/5537/2051.
Nickles, T. (1984). Positive science and discoverability. PSA: Proceedings of the Biennial Meeting of the Philosophy of Science Association 1984:13–27, http://www.jstor.org/stable/192324.
Nickles, T. (1985). Beyond divorce: Current status of the discovery debate. Philosophy of Science, 52(2), 177–206. http://www.jstor.org/stable/187506.
Nickles, T. (1990). Discovery logics. Philosophica, 45, 7–32.
Pearl, J. (2000). Causality: Models, reasoning, and inference. Cambridge: Cambridge University Press.
Penrose, R. (1994). Shadows of the mind: A search for the missing science of consciousness. Oxford, New York: Oxford University Press.
Popper, K. (1972). Objective knowledge. London: Oxford University Press.
Popper, K. (2002). The logic of scientific discovery. Routledge classics. New York: Routledge.
Quinlan, J. R. (1992). C4.5: Programs for machine learning (1st ed.). San Mateo, CA: Morgan Kaufmann.
Reichenbach, H. (1938). Experience and prediction: An analysis of the foundations and the structure of knowledge. Chicago: University of Chicago Press.
Russell, S., & Norvig, P. (2009). Artificial intelligence: A modern approach (3rd ed.). Upper Saddle River: Prentice Hall.
Savary, C. (1995). Discovery and its logic: Popper and the “friends of discovery”. Philosophy of the Social Sciences, 25(3), 318–344. doi:10.1177/004839319502500303, http://pos.sagepub.com/content/25/3/318.
Schickore, J. (2014). Scientific discovery. In: Zalta E. N. (Eds.), The Stanford Encyclopedia of Philosophy (Spring 2014 ed.). http://plato.stanford.edu/archives/spr2014/entries/scientific-discovery/.
Schmidt, M., & Lipson, H. (2009). Distilling free-form natural laws from experimental data. Science, 324(5923), 81–85. doi:10.1126/science.1165893, http://www.sciencemag.org/content/324/5923/81.
Schwarz, G. (1978). Estimating the dimension of a model. The Annals of Statistics, 6(2), 461–464. http://www.jstor.org/stable/2958889.
Shah, M. (2008). The logics of discovery in Popper’s evolutionary epistemology. Journal for General Philosophy of Science / Zeitschrift für allgemeine Wissenschaftstheorie, 39(2), 303–319. http://www.jstor.org/stable/40390659.
Simon, H. A., Langley, P. W., & Bradshaw, G. L. (1981). Scientific discovery as problem solving. Synthese, 47, 1–27. doi:10.2307/20115615, http://www.jstor.org/stable/20115615, 1
Spirtes, P., Glymour, C. N., & Scheines, R. (2000). Causation, prediction, and search, adaptive computation and machine learning (2nd ed.). Cambridge, MA: MIT Press.
Thagard, P. (1980). Against evolutionary epistemology. PSA: Proceedings of the Biennial Meeting of the Philosophy of Science Association, 1980:187–196. http://www.jstor.org/stable/192564.
Tschaepe, M. (2014). Guessing and abduction. Transactions of the Charles S Peirce Society: A Quarterly Journal in American Philosophy, 50(1), 115–138. https://muse-jhu-edu.ezproxy.lib.vt.edu/journals/transactions_of_the_charles_s_peirce_society/v050/50.1.tschaepe.html
Wang, Q., Garrity, G. M., Tiedje, J. M., & Cole, J. R. (2007). Naive Bayesian classifier for rapid assignment of rRNA sequences into the new bacterial taxonomy. Applied and Environmental Microbiology, 73(16), 5261–5267. doi:10.1128/AEM.00062-07, http://aem.asm.org/content/73/16/5261.
Way, M., Scargle, J., Ali, K., & Srivastava, A. (2012). Advances in machine learning and data mining for astronomy. New York: Chapman and Hall/CRC. http://proquest.safaribooksonline.com/9781439841747.
Woodward, J. F. (1992). Logic of discovery or psychology of invention? Foundations of Physics, 22(2), 187–203. doi:10.1007/BF01893611.
Wu, X., Kumar, V., Quinlan, J. R., Ghosh, J., Yang, Q., Motoda, H., et al. (2007). Top 10 algorithms in data mining. Knowledge and Information Systems, 14(1), 1–37. doi:10.1007/s10115-007-0114-2.
Yang, Z.R. (2004). Biological applications of support vector machines. Briefings in Bioinformatics, 5(4), 328–338. doi:10.1093/bib/5.4.328, http://bib.oxfordjournals.org/content/5/4/328.
Zhang, N. L., Nielsen, T. D., & Jensen, F. V. (2004). Latent variable discovery in classification models. Artificial Intelligence in Medicine, 30(3), 283–299. doi:10.1016/j.artmed.2003.11.004, http://www.sciencedirect.com/science/article/pii/S0933365703001350.
Zytkow, J. M., & Simon, H. A. (1988). Normative systems of discovery and logic of search. Synthese, 74, 65–90. doi:10.2307/20116486, http://www.jstor.org/stable/20116486, 1.
Acknowledgments
I am grateful to Richard Burian, Lydia Patton, Tristram McPherson, Kelly Trogdon, Ted Parent, Gregory Novak, Daniel Kraemer, Nathan Rockford, Nathan Adams, and two anonymous reviewers for their insightful criticisms of earlier versions of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Jantzen, B.C. Discovery without a ‘logic’ would be a miracle. Synthese 193, 3209–3238 (2016). https://doi.org/10.1007/s11229-015-0926-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11229-015-0926-7