
Abstract
As part of a recent attempt to extend the methods of formal semantics beyond language (‘Super Semantics’), it has been claimed that music has an abstract truth-conditional semantics, albeit one that has more in common with iconic semantics than with standard compositional semantics (Schlenker 2017, 2019a, b). After summarizing this approach and addressing a common objection (here due to Leonard Bernstein), we argue that music semantics should be enriched in three directions by incorporating insights of other areas of Super Semantics. First, it has been claimed by Abusch 2013 that visual narratives make use of discourse referents akin to those we find in language. We argue that a similar conclusion extends to music, and we highlight it by investigating ways in which orchestration and dance may make cross-referential dependencies more explicit. Second, we show that by bringing music semantics closer to the semantics of visual narratives, we can give an account of the semantics of mixed visual and musical sequences. Third, it has been claimed that co-speech gestures trigger characteristic conditionalized presuppositions, called ‘cosuppositions’, and that their semantic status derives from their parasitic character relative to words (Schlenker 2018a, b). We argue that the same conclusion extends to some instances of film and cartoon music: it may trigger cosuppositions that can be revealed by embedding film excerpts or gifs in sentences so as to test presupposition projection. We further argue that under special discourse conditions (pertaining to certain Questions under Discussion), pro-speech gestures and pro-speech music alike can trigger cosuppositions as well. These results suggest that new insights can be gained not just by extending the methods of semantics to new objects, but also by drawing new connections among them.
Similar content being viewed by others



Notes
Audiovisual examples have been included by way of URLs (some are borrowed from Schlenker, 2017, 2019a, 2019b). They can also be downloaded as a separate file, and are cross-referenced in the text by way of boldfaced names such as AV00, AV01, …. The text might be hard to follow without consulting these audiovisual examples.
Downloadable file: https://drive.google.com/file/d/1k4-6296WVOP32LZtBuiihzXgK4S3xHxS.
This notion of semantics corresponds to what Koelsch (2012) calls ‘extra-musical meaning’. Granroth-Wilding and Steedman (2014) endow their formal syntax for jazz chord sequences with a semantics that encodes paths in a tonal pitch space; this does not yield an ‘extra-musical meaning’ in Koelsch’s sense, or in the sense of ‘semantics’ adopted in this piece (see also Schlenker (2019c, Appendix I)).
Gabe Greenberg has used the term formal semiotics with a related meaning (e.g. Greenberg, 2021, and numerous earlier talks).
Our ‘discourse referents’ will just be variables with a standard semantics; the framework we develop does not make use of notions borrowed from dynamic semantics (unlike Abusch, 2020) or Discourse Representation Theory (unlike Maier and Bimpikou, 2019). See also Greenberg, 2014, 2019b for a different way of introducing some varieties of discourse referents in pictorial representations.
Gif just stands for Graphic Interchange Format, but the term has come to be used to refer to very brief animations.
The term “virtual source” has been used by different authors to discuss inferential effects in music. Thus for Bregman (1994), “the virtual source in music plays the same perceptual role as our perception of a real source does in natural environments”. As a result, “transformations in loudness, timbre, and other acoustic properties may allow the listener to conclude that the maker of a sound is drawing nearer, becoming weaker or more aggressive, or changing in other ways” (Bregman, 1994). We eschew the term here because it has been used in different ways by different authors, leading to potential confusions (e.g. Schlenker, 2017, 2019a, 2019b, 2019c uses the term to refer to the objects—not necessarily sound-producing ones—which are denoted by the music).
In our technical implementation, ‘situations’ are cashed out in terms of possible worlds and tuples of eventualities.
While the notion of ‘energy’ should be further explicated, we can rely at this point on an intuitive notion of folk psychology, according to which objects are taken to have different levels of energy depending on their movements and more generally on their behavior.
Bedoya (2019) tests and uncovers further inferential means within the area of musical emotions. In a nutshell, he starts from properties of the human voice that are indicative of certain emotions. For instance, a person speaking that starts to smile will produce slightly different sounds, in such a way that one can ‘hear’ the person smile (formants will be shifted upwards). Bedoya then runs algorithms that perform the same modifications on musical snippets, thus artificially producing “smiling violins”, for instance. Finally, he tests the effect of the modification on the emotions conveyed by the music: smiling violins were thus taken to express more positive emotions than standard violins. Manipulations included pitch (tuning up vs. tuning down), formants (“smiling” vs. “unsmiling” music), vibrato (frequency modulations around the base frequency) and “roughness”.
To avoid having to redefine later what perspectival points are, we do not identify them with spatio-temporal points; at this juncture, we just require that they include information about a spatial-temporal point.
To mention some examples: (i) Eitan and Granot (2006) provide experimental data on the connection between ‘inter-onset interval’ (= interval between notes) and the scenes evoked in listeners; (ii) the connection between music and movement is discussed in Clarke (2001, 2005), Eitan and Granot (2006), Godoy et al. (2010), and Larson (2002); (iii) the implications of loudness, for instance in terms of distance, are discussed in Eitan and Granot (2006), and Ilie and Thompson (2006); (iv) the interpretation of frequency in terms of object size is discussed in Cross and Woodruff (2008); (v) diverse emotional implications of music are discussed in reviews by Gabrielsson and Lindström (2010), and Juslin and Laukka (2003). These implications include for instance association between higher pitch and greater ‘tension arousal’ (Ilie and Thompson, 2006), and between distortion noises and increased arousal and negative valence (Blumstein et al., 2012). For their part Sievers et al. 2013 find similarities between the mechanisms that trigger emotions in music and in the movement of a ball that can take various shapes, a program further developed in Sievers et al. (2019). See also Koelsch (2012) for a relevant review.
The numbering is ours.
Thanks to two anonymous reviewers for raising the first two objections that follow.
See Lerdahl (2019, chapter 3), for further remarks about the relevance of Heider and Simmel’s animations to music semantics.
We further conjecture that in music performance, interpretive choices that go beyond the musical score are often guided by semantic considerations, i.e. by the kind of abstract ‘story’ the musicians wish to tell.
Migotti and Zaradzki (2019) also raise a more fundamental issue (just a potential one at this point, as their experimental data do not yet prove its validity). They argue in their study of walk-denoting excerpts that a 2-chord sequence enriched with a third, less salient note may evoke a walk even though no subevent seems to correspond to that third note. If this is indeed the case, one possibility they sketch is that certain notes play a role roughly similar to that of modifiers in language: they modify the interpretation of the notes they accompany but do not represent an event on their own. An alternative (which may or may not turn out to be a notational variant) would be to take the granularity of interpretation to be somewhat variable, possibly with cases in which a group of notes is taken to denote an event [as discussed speculatively in Schlenker (2019c, Appendix IV)].
More specifically, Hanslick (1891) writes: “while sound in speech is but a sign, that is, a means for the purpose of expressing something which is quite distinct from its medium; sound in music is the end, that is, the ultimate and absolute object in view” (Hanslick, 1891, p. 94). Later in the same piece, he writes: “Music has (…) no subject in the sense that the subject to be treated is something extraneous to the musical notes” (Hanslick, 1891, p. 162). See also Rodriguez 2021 for a detailed (and historically informed) discussion of music semantics from a philosophical perspectival.
For Huron, “the emotions evoked by expectation involve five functionally distinct physiological systems: imagination, tension, prediction, reaction, and appraisal” (p. 7), and he tries to derive musical emotions from the interaction of these systems with musical anticipations (the resulting theory is called ‘ITPRA’, which is the acronym of the five physiological systems).
Special thanks to P. Egré (p.c.) for calling our attention to the relevance of Bernstein’s discussion for music semantics. Bernstein revisited this topic in his Harvard Lectures (Bernstein, 1976), with different views: “music has intrinsic meanings of its own, which are not to be confused with specific feelings or moods, and certainly not with pictorial impressions or stories. These intrinsic musical meanings are generated by a constant stream of metaphors, all of which are forms of poetic transformations.” We focus on the (earlier) Young People’s Concerts for their rich empirical content and negative thesis rather than for the positive theory Bernstein develops in them.
AV01 5:17 makes reference to downloadable audiovisual example AV01 at time 5 minutes 17 seconds; the same notation applies elsewhere in this article.
The text has “chuckling to himself”, Bernstein’s live performance has: “laughing at Don Quixote” (there are several small differences between the live and the printed version).
In Sect. 5, we will see another case in which there is some freedom in the choice of the number of objects that are taken to be denoted (this will be cashed out in terms of discourse referents).
As noted in Schlenker (2019b) about (11)f, “the musical chaos corresponding to the sheep’s baaing wildly is not easily interpreted in the Superman story (why would the prisoner’s snoring become more chaotic when Superman grabs his friend and liberates him?)”.
Technically, the recomposition was effected by taking symmetric intervals relative to F# (= the 3rd degree in the relevant key, namely D major). To illustrate, the first note of (12) is A, 2 degrees above F#. The mirror-image note relative to F# going downwards is D, 2 degrees below F#, as in (13). The second note type appearing in (12) is B, 3 degrees above F#. Its mirror-image counterpart relative to F# is C#, 3 degrees below F#, as in (13). This is the reason the second note type appearing in (13) is C#.
Bonetto kept the same number of notes in each chord, finding the closest chord that was in the key of the melody (the variation is in D major but this melody is in F# minor).
In greater detail, the transformations were as follows:
(i) From (18)a to (18)b: Bar 1: F#> G Bar 2: F#> G ; B> Bb Bars 3-4/6-7:
 ; Gb> G ; B> Bb Bar 5: C> D; B> Bb ; Ab> G ; Eb> D.
; Gb> G ; B> Bb Bar 5: C> D; B> Bb ; Ab> G ; Eb> D.(ii) From (18)a to (18)c: same as (i), but the boxed
 in (i) becomes
in (i) becomes 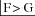 instead.
instead.This was the performance that launched Bernstein’s career. As Shawn (2014) writes, “guest conductor Bruno Walter had come down with influenza” and Bernstein had to replace him in a program that included Strauss’s Don Quixote. “He had never rehearsed these works with the orchestra, and there wouldn’t be time for a minute with them before the performance. Fortunately, he had been fascinated by the complex Strauss score and had painstakingly studied its intricacies and how they mirrored events in the Cervantes novel.”
One can also explore more sophisticated minimal pairs in which the melody is played crescendo and the dissonances diminuendo or conversely. The effect is arguably that there are two objects involved, one approaching and one moving away.
(i)
More modifications
[Dissonances <, melody>] (simplified Midi) [AV34 https://youtu.be/I3vr6p-Tr-4]
[Dissonances>, melody <] (simplified Midi) [AV35 https://youtu.be/epgwlBhchMY]
See Schlenker (2019a) for a more detailed discussion of the way in which emotions naturally come to play a prominent role in music semantics.
If underspecification is supplemented with a mechanism of enrichment (e.g. pragmatic enrichment), we will end up with an ambiguity of sorts. Our point is just that we plausibly need to generate two readings in this case.
As an anonymous reviewer points out, this means that different picture parts can serve as different tokens of the same variable type. This is the reason we must specify where the variable v1 appears in each of the pictures in (32).
Allowing for several discourse references per musical time slot would bring music semantics one step closer to the semantics of visual narratives, where several discourse referents may co-occur in one and the same picture.
Technically, we can take an assignment function g to specify a denotation for elementary variables of the form v, after which we recursively extend g to complex variables using the rule: if v + v′ is a complex variable, g(v + v′) = g(v) + g(v′). See (96) in the Appendix for a definition along these lines.
The condition that the object takes part in the eventuality is guaranteed by the boldfaced part of (37).
Mazurkas are traditional Polish folk dances. Chopin’s piano pieces by the same name are inspired by them but form a separate genre.
Finding the origin of different orchestrations is often difficult because information provided with online recordings may be insufficient or even misleading (in case different parts of a ballet music were orchestrated by different composers). The contrasts that we discussed are clear enough that they could be assessed ‘by ear’, and major differences in instrumentation were investigated (also by ear) by A. Bonetto.
For the history of the Britten score (lost and then rediscovered), see Cooper 2013.
Broadly similar choices are made in an orchestration by Gordon Jacob. The timbres are those in (i), where the orchestra is clearly contrasted with the winds, while the identity of the winds is a bit underspecified. To Bonetto’s ear, winds1 include flutes or piccolos and a bassoon, winds1? flutes or piccolos and something else; the distinction is less than obvious, so relations of coreference should be encoded with some uncertainty as in (ii) (hence 2? on [C′D′]).
(i)
Gordon Jacob’s orchestration
a. [AB]orchestra [A′B′]winds1
b. [CD]orchestra [C′D′]winds1?
c. [AB]orchestra [A′B′]wind1
(ii)
a. [AB]1 [A′B′]2
b. [CD]1 [C′D′]2?
c. [AB]1 [A′B′]2
Maurice Keller’s orchestration, in (iii), also contrasts the orchestra for AB with a group of winds for A′B′ (= winds1), but then things become less clear. The orchestra recurs for CD, but for the second AB, it appears in modified form (orchestra+) together with a countermelody by the cellos, which we disregard here (it could be treated as denoting a separate object). The winds appear in modified form for C′D′ (written as winds1+), and a version of the winds appears again for the last A′B′. This yields the same type of indexing as the Britten orchestration, but with much greater uncertainty, as shown in (iv) (where the indices followed by ? may but need not mark coreference).
(iii)
Maurice Keller’s orchestration (1908) [AV52 https://youtu.be/IMWM8NP3_s4]
a. [AB]orchestra [A′B′]winds1
b. [CD]orchestra [C′D′]winds1+
c. [AB]orchestra+ [A′B′]winds1+
(iv)
a. [AB]1 [A′B′]2
b. [CD]1 [C′D′]2?
c. [AB]1? [A′B′]2?
We disregard a further complexity (which isn’t so easy to perceive): winds1 get slightly modified between A′ and B′, and similarly for winds2 between C′ and D′.
An orchestration explicitly attributed to Arthur Fiedler is very similar but slightly harder to hear ([AV55 https://youtu.be/THg_PhplYJk]).
The same issue arises with film and cartoon music: it may complement rather than repeat the content of the visual scenes and dialogues (specialists use the term ‘mickey mousing’ when the music conveys the same information as the visuals, and this need not be laudatory).
Several sources suggest that this piece was added to Fokine’s original version of Chopiniana, in an orchestration by Maurice Keller. Thus Craine and Mackrell (2010, p. 435) imply that Maurice Keller orchestrated the additional pieces that were added to the original ballet in the version premiered on March 21, 1908 at the Mariinsky theater in St Petersburg, Russia (as we understand it, this would have included the Mazurka Op. 33 No. 2).
In fact, Lerdahl and Jackendoff’s pioneering analysis (1983) posited four structures: “Grouping structure describes the listener’s segmentation of the music into units such as motives, phrases, and sections. Metrical structure assigns a hierarchy of strong and weak beats. Time-span reduction, the primary link between rhythm and pitch, establishes the relative structural importance of events within the rhythmic units of a piece. Prolongational reduction develops a second hierarchy of events in terms of perceived patterns of tension and relaxation.” (Lerdahl, 2001)
See also Lerdahl and Jackendoff 1983 (p. 51) for the role of parallelism in determining how musical elements should be grouped.
In fact, the melodic movement isn’t even identical across the two cases: the first movement has a transition Cb-Ab-F, the second E-C-Ab: the last interval of the first movement is a minor third (Ab-F), whereas the last interval of the second is a major third (C-Ab) (thanks to A. Bonetto for discussion).
Thanks to A. Bonetto for transcribing these themes.
Further patterns of indexation could be considered. A. Bonetto (p.c.) suggests that one could take B and B′ to be coindexed, but to correspond to something more abstract than the apprentice or the genie. On this interpretation, then, we would have the representations B[v4], B′[v4], where v4 does not corefer with v1, v2, v3.
We write that this is just ‘a first approximation’ because in some cases one medium is presented as primary and the second as parasitic, in which case the second arguably triggers cosuppositions, as we suggest in Sect. 6.
Here it should be recalled that we ‘generalized to the worst case’ by taking perspectival points to be in essence Greenbergian viewpoints, which come with a spatial location (useful for musical and pictorial applications) as well as a projection plane (relevant in the pictorial domain only).
As noted in Schlenker (2018a), “the terminology is intended to suggest that a cosupposition triggered in a local context c′ is computed in tandem with (‘co’) an at-issue component in c′ (by contrast, a standard presupposition triggered in c′ is computed before (‘pre’) any at-issue component in c′)”.
In the context of co-speech gesture theory, Schlenker (2018a, Sect. 3.3.3) also explores the possibility that gestural cosuppositions put constraints on what the speaker takes for granted (= the speaker’s context), rather than on what is common ground in the conversation. This would offer a different reason why cosuppositions need not be trivial at all.
This picture (which is not by Asterix’s creator Uderzo, but by Zenitram) can be found at https://www.deviantart.com/zenitram-anth/art/Asterix-chez-les-freaks-472781613 (retrieved December 9, 2019).
Thanks to Robert Pasternak for authorizing us to cite his sound files.
As mentioned at the end of Sect. 6.1, presuppositions in general and cosuppositions in particular can produce information by forcing the addressee to accept (‘accommodate’) a context that satisfies the presupposition: the co-speech sound effect in (69) tells the addressee that she is in a context in which adjusting the brightness entails turning it down, and the co-speech music in (70) tells her that for the cavalry to do what’s needed, it would have to come quickly and triumphantly.
Just like a co-speech element accompanies a linguistic expression, a pro-speech element replaces one.
Original from https://giphy.com/gifs/paf-asterix-ulCTAq0E5ekV2, retrieved on December 10, 2019. We modified the original in order to make the three components easier to separate. Specifically, we made the point at which Asterix pauses after drinking the potion longer, and we made his departure slower.
This borrows a notation for non-manual expressions in sign language linguistics.
We also constructed one further pair involving an excerpt from Verdi’s Simon Boccanegra, which accompanies a scene in which Simon drinks from a cup which, unbeknownst to him, contains poison (original: [AV80 https://youtu.be/3mKqInZ1y-Q]): the music suggests that something momentous and disturbing is happening (see Schlenker 2019c for a more detailed semantic discussion). Our consultants did not find the gif-music pairing very successful in this case (the gifs can be seen here: [AV81a https://youtu.be/N4-P83l6A-A]; [AV81b https://youtu.be/4wV-4_q7ZEM]).
Importantly, the expectation that cosuppositional inferences should be triggered by the music only arises to the extent that the music is treated as being parasitic on the visuals and not the other way around. An example in which this is not the case is briefly mentioned in Schlenker (2021):
(i)
On Bastille Day, will your students Allons-enfants-de-la-patrie-HAND-ON-HEART?
In (i), the French words Allons enfants de la patrie are literally sung as part of the sentence, but are accompanied by a patriotic posture, with the speaker’s hand on his heart. This triggered a cosupposition to the effect that if the speaker’s students were to sing the Marseillaise on Bastille Day, they would adopt a patriotic posture such as having one’s hand on one’s heart. In this case, the musical element is primary and the visual (gestural) element is secondary.
This possibility has been emphasized in work by M. Esipova.
The same issues arise for the typology of apparently non-linguistic inferences discussed in Tieu et al.’s (2019), Guerrini and Migotti (2019), and Guerrini and Schlenker (2019): the stimuli are non-linguistic, but they need to be embedded in sentences in order to assess their semantic behavior (e.g. as presuppositions, implicatures, supplements, etc.). The question is whether it is only when they are embedded in linguistic environments that they trigger such inferential types.
The picture can be found at https://www.deviantart.com/zenitram-anth/art/Asterix-chez-les-freaks-472781613 (retrieved on December 9, 2019).
Two remarks should be added. First, we assume that the explicit question in (87) serves to address an implicit Question under Discussion: one is really interested in whether Asterix will or will not drink the magic potion. Second, our discussion glosses over the question of how to integrate our pictorial semantics with a compositional semantics for the rest of the sentence (we have not sought to integrate this part of the discussion to the system discussed in the Appendix, as Questions under Discussion introduce numerous complexities of their own).
One way to do things in a simplified case (without will) is with the Logical Form in (i). It assumes that, in this linguistic context, the picture has the type-theoretic meaning (ii), which is compatible with the truth-of conditions in (iii). Fixing the perspectival point π, this makes it possible to recover the set of possible worlds that make the sentence true by way of the derivation of truth conditions in (iv) (where we write Asterix′ for the denotation of the proper name Asterix).
(i)
Asterix λv1 ∃e P[v1](e)
(ii)
〚P[v1]〛π, g, w = λe [relative to π, w, g, e projects to P from π and g(v1) is an object that takes part in e and projects to variable v1 of P]
(iii)
P[v1] is true of eventuality e relative to π, w, g iff relative to π, w, e projects to P and g(v1) is an object that takes part in e and projects to variable v1 of P.
(iv)
〚(i)〛π, g, w = 〚Asterix λv1 ∃e P[v1](e)〛π, g, w =(〚λv1 ∃e P[v1](e)〛π, g, w) (〚Asterix〛π, g, w) = (λd〚∃e P[v1](e)〛π, g[v1→d], w)(Asterix′) = 〚∃e P[v1](e)〛π, g[v1→Asterix′], w = 1 iff for some event e,〚P[v1]〛π, g[v1→Asterix′], w(e) = 1.
iff for some event e, relative to π, w, e projects to P and g[v1→Asterix′] is an object that takes part in e and projects to variable v1 of P,
iff for some event e, relative to π, w, e projects to P and Asterix′ is an object that takes part in e and projects to variable v1 of P.
We thank an anonymous reviewer for pressing us on this issue.
A further issue is whether certain contexts could help turn cosuppositions into part of the at-issue component. This is expected on general grounds because presuppositions can be ‘locally accommodated’ (i.e. turned into the at-issue component) in certain environments, and cosuppositions triggered by co-speech gestures have been argued to be particular prone to this behavior (Schlenker, 2018a; Tieu et al. 2017, 2018; see also Esipova 2019).
The status of eventualities in our formal analysis should also be clarified. We added them to a mere possible world semantics in order to unify pictorial and music semantics. But we fell short of saying exactly what these eventualities are (besides the claim that they are parts of worlds).
Note that M1, …, Mn contain variables, but that these do not directly play a role in the preservation conditions. However they do play a role in the underlined part of (100) by requiring that their denotations take part in the appropriate denoted events.
We write ‘one possible definition’ because others could be explored. For example, we have taken the global context set C to be a set of possible worlds, but it would make sense to take it to be a set of tuples, e.g. including a perspectival point and a possible world, or even a perspectival point, a possible world and an assignment function.
Technically, a local context is a function from such parameters to truth values.
For i = 1, condition (iii) is vacuous.
 ; Gb> G ; B> Bb Bar 5: C> D; B> Bb ; Ab> G ; Eb> D.
; Gb> G ; B> Bb Bar 5: C> D; B> Bb ; Ab> G ; Eb> D. in (i) becomes
in (i) becomes 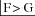 instead.
instead.References
Abusch, D. (2013). Applying discourse semantics and pragmatics to co-reference in picture sequences. Proceedings of Sinn und Bedeutung, 17, 9–25. https://ojs.ub.uni-konstanz.de/sub/index.php/sub/article/view/330.
Abusch, D. (2020). Possible-worlds semantics for pictures. In D. Gutzmann, L. Matthewson, C. Meier, H. Rullmann, & T. Zimmermann (Eds.), The Wiley Blackwell companion to semantics. https://doi.org/10.1002/9781118788516.sem003.
Abusch, D., & Rooth, M. (2017). The formal semantics of free perception in pictorial narratives. In A. Cremers, T. van Gessel, & F. Roelofsen (Eds.), Proceedings of the 21st Amsterdam Colloquium (pp. 85–96). https://semanticsarchive.net/Archive/jZiM2FhZ/AC2017-Proceedings.pdf.
Bedoya, D. (2019). Les émotions sont-elles exprimées de la même façon en musique que dans la voix parlée? Internship report (advisors: Jean-Julien Aucouturier and Louise Goupil), IRCAM, Paris.
Bernstein, L. (1967). Charles Ives: American Pioneer. Young People’s Concerts. Television series, February 23, 1967.
Bernstein, L. (1976). The unanswered question: Six talks at Harvard. Cambridge, MA: Harvard University Press.
Bernstein, L. (2005). Young People’s concerts. Prompton Plains, NJ: Amadeus Press.
Blumstein, D. T., Bryant, G. A., & Kaye, P. (2012). The sound of arousal in music is context-dependent. Biology Letters, 8, 744–747.
Bregman, A. S. (1994). Auditory scene analysis. Cambridge, MA: MIT Press.
Clarke, E. (2001). Meaning and the specification of motion in music. Musicae Scientiae, 5, 213–234.
Clarke, E. (2005). Ways of listening: An ecological approach to the perception of musical meaning. Oxford: Oxford University Press.
Cooper, M. (2013). Mystery of the missing music. New York Times, August 27, 2013. Retrieved December 18, 2019 from https://www.nytimes.com/2013/08/28/arts/music/benjamin-brittens-lost-score-for-les-sylphides.html.
Craine, D., & Mackrell, J. (2010). Oxford dictionary of dance. Oxford: Oxford University Press.
Cross, I., & Woodruff, G. E. (2008). Music as a communicative medium. In R. Botha & C. Knight (Eds.), The prehistory of language (pp. 113–144). Oxford: Oxford University Press.
Ebert, C., & Ebert, C. (2014). Gestures, demonstratives, and the attributive/referential distinction. Handout of a talk given at Semantics and Philosophy in Europe (SPE 7), ZAS, Berlin.
Eitan, Z., & Granot, R. Y. (2006). How music moves. Music Perception, 23(3), 221–247.
Esipova, M. (2019). Composition and projection in speech and gesture. Ph.D. thesis, New York University.
Gabrielsson, A., & Lindström, E. (2010). The role of structure in the musical expression of emotions. In P. N. Juslin & J. A. Sloboda (Eds.), Handbook of music and emotion: Theory, research, and applications (pp. 367–400). Oxford: Oxford University Press.
Godoy, R. I., & Leman, M. (Eds.) (2010). Musical gestures: Sound, movement, and meaning. London: Routledge.
Granroth-Wilding, M., & Steedman, M. (2014). A robust parser-interpreter for jazz chord sequences. Journal of New Music Research, 43(4), 355–374.
Greenberg, G. (2013). Beyond resemblance. Philosophical Review, 122(2), 215–287.
Greenberg, G. (2014). Reference and predication in pictorial representation. Handout of a talk given at the London Aesthetics Forum.
Greenberg, G. (2019a). Semantics of pictorial space. Manuscript, UCLA.
Greenberg, G. (2019b). Tagging: Semantics at the iconic/symbolic interface. In J. Schlöder, D. McHugh, & F. Roelofsen (Eds.), Proceedings of the 22nd Amsterdam Colloquium (pp. 11–22). Amsterdam: ILLC.
Greenberg, G. (2021). The iconic-symbolic spectrum. Manuscript, UCLA.
Guerrini, J., & Migotti, L. (2019) Musical gestures in the typology of linguistic inferences. Talk given at the workshop on “Linguistic investigations beyond language: gestures, body movement and primate linguistics”.
Guerrini, J., & Schlenker, P. (2019). Linguistic inferences without words: The case for pro-speech vocal gestures. Poster, GLOW 42, May 8–10, 2019.
Hanslick, E. (1891). The beautiful in music: A contribution to the revisal of music aesthetics (G. Cohen, Trans.). London: Novello and Company, Limited.
Heider, F., & Simmel, M. (1944). An experimental study of apparent behavior. American Journal of Psychology, 57, 243–259.
Heim, I. (1983). On the projection problem for presuppositions. In M. Barlow, D. Flickinger, & M. Westcoat (Eds.), Proceedings of the Second West Coast Conference on Formal Linguistics (pp. 114–126). Stanford, CA: Stanford Linguistics Association.
Huron, D. (2016). Voice leading: The science behind a musical art. Cambridge, MA: MIT Press.
Ilie, G., & Thompson, W. F. (2006). A comparison of acoustic cues in music and speech for three dimensions of affect. Music Perception, 23, 319–329.
Juslin, P., & Laukka, P. (2003). Communication of emotions in vocal expression and music performance: Different channels, same code? Psychological Bulletin, 129(5), 770–814.
Keats, J. (2018). Science of music: Listen up!. Discovery Magazine, special issue on Everything worth knowing. http://discovermagazine.com/2018/jul-aug/science-of-music.
Koelsch, S. (2012). Brain and music. Oxford: Wiley.
Larson, S. (2012). Musical forces: Motion, metaphor, and meaning in music. Bloomington, IN: Indiana University Press.
Lascarides, A., & Stone, M. (2009). A formal semantic analysis of gesture. Journal of Semantics, 26(4), 393–449.
Leffel, T. (2014). The Semantics of Modification: Adjectives, Nouns, and Order. PhD thesis, New York University.
Lerdahl, F. (2001). Tonal pitch space. Oxford: Oxford University Press.
Lerdahl, F. (2019). Composition and cognition: Reflections on contemporary music and the musical mind. Oakland, CA: University of California Press.
Lerdahl, F., & Jackendoff, R. (1983). A generative theory of tonal music. Cambridge, MA: MIT Press.
Maier, E., & Bimpikou, S. (2019). Shifting perspectives in pictorial narratives. Proceedings of Sinn und Bedeutung, 23(2), 91–106. https://doi.org/10.18148/sub/2019.v23i2.600.
Mehr, S. A., et al. (2019). Universality and diversity in human song. Science, 366(eaax0868), 1–17.
Meyer, L. B. (1956). Emotion and meaning in music. Chicago, IL: University of Chicago Press.
Migotti, L. (2019). Towards a theory of music semantics. M.A. thesis, Cogmaster, Paris.
Migotti, L., & Zaradzki, L. (2019). Walk-denoting music: Refining music semantics. In J. Schlöder, D. McHugh, & F. Roelofsen (Eds.), Proceedings of the 22nd Amsterdam Colloquium (pp. 593–602). Amsterdam: ILLC.
Parsons, T. (1990). Events in the semantics of English. New York: MIT Press.
Pasternak, R. (2019). The projection of co-speech sound effects. Manuscript, ZAS Berlin. https://ling.auf.net/lingbuzz/004520.
Pasternak, R., & Tieu, L. (2020). Co-linguistic content projection: From gestures to sound effects and emoji. Manuscript, ZAS Berlin and U. of Western Sydney.
Patel-Grosz, P., Grosz, P. G., Kelkar, T., & Jensenius, A. R. (2018). Coreference and disjoint reference in the semantics of narrative dance. Proceedings of Sinn und Bedeutung, 22(2), 199–216. https://ojs.ub.uni-konstanz.de/sub/index.php/sub/article/view/78.
Pesetsky, D., & Katz, J. (2009). The identity thesis for music and language. Manuscript, MIT.
Roberts, C. (2012). Information structure in discourse: Towards an integrated formal theory of pragmatics. Semantics and Pragmatics, 5, 6:1–69. https://doi.org/10.3765/sp.5.6.
Rodriguez, H. (2021). Sémantique et pragmatique de la musique. Une approche cognitive basée sur le travail de Philippe Schlenker et sur les œuvres de Franz Liszt. Doctoral dissertation, Université Libre de Bruxelles.
Rohrmeier, M. (2011). Towards a generative syntax of tonal harmony. Journal of Mathematics and Music, 5(1), 35–53.
Schlenker, P. (2009). Local contexts. Semantics and Pragmatics, 2, 3:1–78. https://doi.org/10.3765/sp.2.3.
Schlenker, P. (2010). Presuppositions and local contexts. Mind, 119(474), 377–391.
Schlenker, P. (2011). Presupposition projection: Two theories of local contexts–Parts I and II. Language and Linguistics Compass, 5, 848–857.
Schlenker, P. (2012). Maximize presupposition and Gricean reasoning. Natural Language Semantics, 20(4), 391–429.
Schlenker, P. (2017). Outline of music semantics. Music Perception: An Interdisciplinary Journal, 35(1), 3–37. https://doi.org/10.1525/mp.2017.35.1.
Schlenker, P. (2018a). Gesture projection and cosuppositions. Linguistics and Philosophy, 41(3), 295–365.
Schlenker, P. (2018b). Iconic pragmatics. Natural Language and Linguistic Theory, 36(3), 877–936.
Schlenker, P. (2018c). Sign language semantics: Problems and prospects [replies to peer commentaries]. Theoretical Linguistics, 44(3–4), 295–353.
Schlenker, P. (2019a). Prolegomena to music semantics. Review of Philosophy and Psychology, 10(1), 35–111. https://doi.org/10.1007/s13164-018-0384-5.
Schlenker, P. (2019b). What is Super Semantics? Philosophical Perspectives, 32(1), 365–453. https://doi.org/10.1111/phpe.12122.
Schlenker, P. (2019c). Gestural semantics: Replicating the typology of linguistic inferences with pro- and post-speech gestures. Natural Language and Linguistic Theory, 37(2), 735–784.
Schlenker, P. (2021). Iconic presuppositions. Natural Language and Linguistic Theory, 39, 215–289.
Shawn, A. (2014). Leonard Bernstein: An American musician. New Haven, CT: Yale University Press.
Sievers, B., Polansky, L., Casey, M., & Wheatley, T. (2013). Music and movement share a dynamic structure that supports universal expressions of emotion. Proceedings of the National Academy of Sciences, 110, 70–75. https://doi.org/10.1073/pnas.1209023110.
Sievers, B., Lee, C., Haslett, W., & Wheatley, T. (2019). A multi-sensory code for emotional arousal. Proceedings of the Royal Society B, 286, 20190513. https://doi.org/10.1098/rspb.2019.0513.
Stalnaker, R. (2002). Common ground. Linguistics and Philosophy, 25(5–6), 701–721.
Steedman, M. (2002). Helmholtz' and Longuet-Higgins’ theories of consonance and harmony. Unpublished Tutorial Paper.
Tieu, L., Pasternak, R., Schlenker, P., & Chemla, E. (2017). Co-speech gesture projection: Evidence from truth-value judgment and picture selection tasks. Glossa, 2(1), 109. https://doi.org/10.5334/gjgl.334.
Tieu, L., Pasternak, R., Schlenker, P., & Chemla, E. (2018). Co-speech gesture projection: Evidence from inferential judgments. Glossa, 3(1), 109. https://doi.org/10.5334/gjgl.580.
Tieu, L., Schlenker, P., & Chemla, E. (2019). Linguistic inferences without words. Proceedings of the National Academy of Sciences, 116(20), 9796–9801.
von Fintel, K. (2008). What is presupposition accommodation, again? Philosophical Perspectives, 22(1), 137–170.
Zaradzki, L. (2021). Les évènements en sémantique linguistique et musicale. Doctoral dissertation, University of Paris-Diderot.
Acknowledgements
I am very grateful to Paul Egré for initial conversations on Bernstein’s views on musical meaning (and on his Superman example), and to Emmanuel Chemla and Pritty Patel-Grosz for extremely helpful written comments on the manuscript. For very helpful feedback, I am also grateful to audiences at GLOW 2019 (May 11, 2019) and NYU’s CLaME group (October 15, 2019). I received very helpful suggestions from Amir Anvari, Paul Boghossian, Emmanuel Chemla, Jeremy Kuhn, Léo Migotti, Robert Pasternak, Pritty Patel-Grosz, Lyn Tieu, and of course Arthur Bonetto. I am also grateful to Zenitram for giving me authorization to use his picture of Asterix. Léo Migotti provided crucial help with audiovisual examples – many thanks to him. Lucie Ravaux offered important help with the references and proofs and Susanne Trissler made invaluable corrections to the proofs after typesetting. Lastly, this paper was greatly improved following extraordinarily constructive comments and criticisms from two anonymous reviewers for Linguistics & Philosophy, and from Managing Editor Regine Eckardt.
Funding
This research received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (Grant agreement No 788077, Orisem, PI: Schlenker). Research was conducted at DEC, Ecole Normale Supérieure-PSL Research University. DEC is supported by grant FrontCog ANR-17-EURE-0017.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Music consultant: Arthur Bonetto.
Arthur Bonetto served as a regular and very insightful music consultant for these investigations; virtually all music examples were discussed with him, and he played a key role in the construction of all minimal pairs, especially when a piece had to be rewritten with special harmonic constraints. However he bears no responsibility for the theoretical claims – and possible errors – contained in this piece.
Appendices
Appendix: Rule and derivations
We display below the main rules used in this article, and illustrate them with sample derivations. After stating the semantics of complex variables and defining perspectival points (à la Greenberg), we introduce music semantics, pictorial semantics, and their interaction in mixed sequences, first without musical cosuppositions, and then with them.
(96) | Simple and complex variables |
a. Syntax | |
(i) for any integers i, vi is an elementary variable; | |
(ii) if v and v′ are variables, v+v′ is a complex variable. | |
b. Semantics | |
Let g be an assignment of values to elementary variables. In the meta-language, d+d′ stand for the mereological sum of (possibly plural) objects d and d′. We take g to be defined for elementary variables, and we extend it recursively to complex variables by the following rule: | |
if v+v′ is a complex variable, g(v+v′) = g(v) + g(v′). |
(97) | Perspectival points |
A perspectival point π is a pair of the form π = <π′, p>, where π′ is spatio-temporal point and p is a projection plane. Both π′ and p matter in pictorial applications, whereas only π′ matters in musical applications. |
-
Music semantics with variables
(98) | Musical sequences |
We take musical sequences to be sequences (ordered in time) of musical events, analyzed as tuples of acoustic parameters. In what follows, we simplify things maximally by taking a musical event to be a pair of a harmonic property (a chord written as I, IV, V, etc.) and a level of loudness (in decibels), hence for instance: <I, 70db>; <V, 75db>. |
(100) | Truth-of relative to a perspectival point, a world and an assignment function |
Let π be a perspectival point, w a world, and g an assignment function. Then: | |
A musical sequence <M1[v1], …, Mn[vn]> is true of eventualities <e1, …, en> relative to π and g in w iff relative to π, w, for each k such that 1 ≤ k ≤ n, g(vk) takes part in ek and | |
(1) temporally, e1 <… <en; | |
(2) the Loudness and Harmonic stability conditions are satisfied by <<g(v1), e1>, …, <g(vn), en>> with respect to <M1, …, Mn>. |
(101) | Preservation conditions |
Relative to a perspectival point π and a world w, if for each i ≤ n the object di takes part in eventuality ei, a musical sequence <M1, …, Mn> is true of <<d1, e1>, …, <dn, en>> only if <<d1, e1>, …, <dn, en>> satisfies the following preservation conditions with respect to <M1, …, Mn>:Footnote 73 | |
a. Loudness condition | |
For all i, k ≤ n, if Mi is less loud than Mk, then in w either: | |
(i) di has less apparent energy from the perspective of π in ei than dk does in ek; or | |
(ii) di is further from π in ei than dk is in ek. | |
b. Harmonic stability condition | |
For all i, k ≤ n, if Mi is less harmonically stable than Mk, then from the perspective of π in w di is in a less stable position in ei than dk is in ek. |
From (100), we can derive a definition of truth in a world relative to a perspectival point (which plays the role of a context) by existentially quantifying over assignment functions and tuples of eventualities, as in (102).
(102) | Truth relative to a perspectival point and a world |
Let π be a perspectival point and w a world. Then: | |
A musical sequence <M1[v1], …, Mn[vn]> is true relative to π in w iff for some assignment function g and for some eventualities e1, …, en, <M1[v1], …, Mn[vn]> is true of <e1, …, en> relative to π and g in w. |
In (103), we display an example involving a single variable, discussed (without variables) in Schlenker (2017, 2019a, 2019b, 2019c).
(103) | An example involving a single variable (after Schlenker, 2017, 2019a, 2019b, 2019c) |
a. Musical sequence: M = <<<I, 70db>, v1>, <<V, 75db>, v1>, <<I, 80db>, v1>> | |
b. Events: we consider the following event sequences, with left-to-right order representing ordering in time, and numerical values assigned to the levels of energy, of proximity and of stability in a world w relative to a perspectival point π |
a. Sun-rise | <sun, minimal-luminosity> | <sun, rising-luminosity> | <sun, maximal-luminosity> |
Energy | 1 | 2 | 3 |
Proximity | 1 | 1 | 1 |
Stability | 3 | 1 | 3 |
b. Sun-set | <sun, maximal-luminosity> | <sun, diminishing-luminosity> | <sun, minimal-luminosity> |
Energy | 3 | 2 | 1 |
Proximity | 1 | 1 | 1 |
Stability | 3 | 1 | 3 |
c. Boat-approaching | <boat, maximal-distance> | <boat, diminishing-distance> | <boat, minimal-distance> |
Energy | 1 | 1 | 1 |
Proximity | 1 | 2 | 3 |
Stability | 3 | 1 | 3 |
d. Boat-departing | <boat, minimal-distance> | <boat, rising-distance> | <boat, maximal-distance> |
Energy | 1 | 1 | 1 |
Proximity | 3 | 2 | 1 |
Stability | 3 | 1 | 3 |
e. Car-crash | <car, movement_1> | <car, movement_2> | <car, crash> |
Energy | 1 | 2 | 3 |
Proximity | 1 | 1 | 1 |
Stability | 3 | 3 | 1 |
(104) | Claim: Relative to π in w, |
a. if g(v1) = sun, M is true of Sun-rise but not of Sun-set | |
b. if g(v1) = boat, M is true of Boat-approaching but not of Boat-departing | |
c. if g(v1) = car, M is false of Car-crash | |
Argument: | |
Ad a.: The Harmonic stability condition is satisfied by both sequences because each has maximally stable events at the beginning and at the end, and a less stable event in the middle, which properly interprets the I-V-I sequence. The Loudness condition is satisfied in Sun-rise since the rising level of energy properly interprets the rising loudness. It is not satisfied in the Sun-set condition: the second chord of M is louder than the first, but this ordering is neither preserved in the ‘energy’ not in the ‘proximity’ interpretation in (103)a. | |
Ad b.: Here too, the Harmonic stability condition is satisfied by both sequences because each has maximally stable events at the beginning and at the end, and a less stable event in the middle, which properly interprets the I-V-I sequence. The Loudness condition is satisfied in Boat-approaching since the increasing proximity properly interprets the rising loudness. It is not satisfied in the Boat-departing condition: the second chord of M is louder than the first, but this ordering is neither preserved in the ‘energy’ not in the ‘proximity’ interpretation in (103)b. | |
Ad c.: The Harmonic stability condition is not satisfied by this sequence because the last chord of M is more stable than the second chord, whereas the last event of Car-crash is less stable than the second event. |
Note: we do not derive truth (as opposed to truth-of) conditions because they would be somewhat unilluminating: they are very weak and would just state the existence of a sequence of three eventualities with increasing energy or proximity relative to the perspectival point, and with greater stability at the beginning and at the end than in the middle.
-
Pictorial semantics with variables (after Abusch, in the implementation of Schlenker, 2019b)
We turn to a definition of pictorial semantics with variables, taking as primitive the notion of an eventuality projecting onto a picture from a perspectival point in a world (see Greenberg, 2013, 2019a for a definition of projection onto a picture from a perspectival point in a world, without reference to eventualities).
(105) | Truth-of relative to a perspectival point, a world and an assignment function for individual pictures |
Let π be a perspectival point, w a world, and g an assignment function, and let P[v1,…, vk] be a picture containing variables v1, …, vk. Then: | |
P[v1,…, vk] is true of eventuality e relative to π, w, g iff relative to π, w, e projects to P and g(v1), …, g(vk) are objects that take part in e and respectively project to variables v1,…, vn of P. |
(106) | Truth-of relative to a perspectival point, a world and an assignment function for pictorial sequences |
Let π be a perspectival point, w a world, and g an assignment function. Then: | |
A pictorial sequence of the form <P1, …, Pn> (where P1, …, Pn may contain variables) is true of eventualities <e1, …, en> relative to π, w, g iff relative to π, w and g, | |
(1) temporally, e1 <…<en, and | |
(2) P1 is true of e1 and … and Pn is true of en. |
From (106), we can derive a definition of truth in a world relative to a perspectival point by existentially quantifying over assignment functions and tuples of eventualities, as in (107).
(107) | Truth relative to a perspectival point and a world |
Let π be a perspectival point and w a world. Then: | |
A pictorial sequence of the form <P1, …, Pn> (where P1, …, Pn may contain variables) is true relative to π, w iff for some assignment function g and for some eventualities e1, …, en, <P1, …, Pn> is true of <e1, …, en> relative to π, w, g. |
We turn to an example with four pictures taken from Disney’s Fantasia (of course the original has many more pictures, but we simplify maximally for the sake of perspicuity). Here the variables v1 and v3 enforce coreference between the sorcerer in pictures P1 and P3 and the genie in pictures P3 and P4.
(108) | An example: four pictures from Disney’s Sorcerer’s Apprentice (Fantasia 1940) |
|

(109) | Truth-of for (108) |
Let π be a perspectival point, w a world, and g an assignment function. Then for all 4-tuples of eventualities <e1, e2, e3, e4>, <P1[v1], P2[v2], P3[v1, v3], P4[v3]> is true of <e1, e2, e3, e4> relative to π, w, g iff relative to π, w, g, | |
(1) temporally, e1 <e2 <e3 <e4, and | |
(2) P1[v1] is true of e1, P2[v2] is true of e2, P3[v1, v3] is true of e3, and P4[v3] is true of e4, | |
iff relative to π, w, | |
(1) temporally, e1 <e2 <e3 <e4, and | |
(2) e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, | |
and e2 projects to P2, and g(v2) takes part in e2 and projects to variable v2 of P2, | |
and e3 projects to P3, and g(v1) and g(v3) take part in e3 and respectively project to variables v1 and v3 of P3, | |
and e4 projects to P4, and g(v3) takes part in e4 and projects to variable v3 of P4. |
The boldfaced parts enforce the desired coreference between the sorcerer in P1 and in P3, and the genie in P3 and in P4. In order to obtain truth (rather than truth-of) conditions in a world w relative to a perspectival point π, we existentially quantify the assignment function g and the tuple of events <e1, e2, e3, e4>:
(110) | Truth for (108) | |
Let π be a perspectival point and w a world. Then: | ||
<P1[v1], P2[v2], P3[v1, v3], P4[v3]> is true relative to π, w iff for some assignment function g, for some eventualities e1, e2, e3, e4, relative to π, w, | ||
(1) temporally, e1 <e2 <e3 <e4, and | ||
(2) | e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, | |
and | e2 projects to P2, and g(v2) takes part in e2 and projects to variable v2 of P2, | |
and | e3 projects to P3, and g(v1) and g(v3) take part in e3 and respectively project to variables v1 and v3 of P3, | |
and | e4 projects to P4, and g(v3) takes part in e4 and projects to variable v3 of P4, | |
iff for some objects d1, d2 and d3, for some events e1, e2, e3, e4, relative to π, w | ||
(1) temporally, e1 <e2 <e3 <e4, and | ||
(2) | e1 projects to P1, and d1 takes part in e1 and projects to variable v1 of P1, | |
and | e2 projects to P2, and d2 takes part in e2 and projects to variable v2 of P2, | |
and | e3 projects to P3, and d1 and d3 take part in e3 and respectively project to variables v1 and v3 of P3, | |
and | e4 projects to P4, and d3 takes part in e4 and projects to variable v3 of P4. | |
The effect of the variables in enforcing coreference relations can once again be seen in the boldfaced parts.
-
Semantics of pictorial and musical sequences combined
We turn to the truth conditions of a pictorial sequence of length n aligned with a musical sequence of length n. In essence, such a sequence is true of a sequence of n eventualities just in case the pictorial sequence is true of the n eventualities and the musical sequence is too.
To simplify notations, we will assume that part of a musical or pictorial sequence may be null and thus trivial, in the sense of being true of all eventualities. This makes it possible to only consider the case of n musical events aligned with n pictures. When the music only co-occurs with the end of the pictorial animation, we will take the beginning of the musical sequence to be null, and thus to make a trivial semantic contribution. (The assumption that there could be ‘null pictures’ will also simplify our discussion of the local context of a picture in a pictorial sequence.)
(111) | Let π be a perspectival point, w a world, and g an assignment function. Then: |
A pictorial sequence of the form <P1, …, Pn> (where P1, …, Pn may contain variables) aligned with a musical sequence <M1[v1], …, Mn[vn]> is true of eventualities <e1, …, en> relative to π, w, g iff <P1, …, Pn> is true relative to π, w, g and <M1[v1], …, Mn[vn]> of <e1, …, en> is true relative to π, w, g. |
Notation: We will write as <P1, …, Pn> + <M1[v1], …, Mn[vn]> a pictorial sequence aligned with a musical sequence.
To illustrate, we consider again the 4-picture sequence in (107), but now aligned with a sequence of four musical events endowed with variables. This is intended as a radical simplification of what happens in the much longer pictorial and musical sequence that appears at the very beginning of Disney’s Sorcerer’s Apprentice, so we have labeled the four musical events as A, B, A′ and B′ to evoke the fact that A′ is similar to A and B′ is similar to B. In keeping with our analysis, the musical sequence is enriched with variables, which disambiguate coreference relations: the notation <A[v1], B[v2], A′[v1], B′[v3]> indicates that A and A′ correspond to the same object, but that B and B′, despite their musical similarity, do not. In addition, these variables serve to establish cross-reference between the music and the pictures: as in (107)–(109), v1 denotes the sorcerer, v2 denotes the apprentice, and v3 denotes the genie.
(112) | Four pictures from Disney’s Sorcerer’s Apprentice (below), with four musical events (above) (Disney, Fantasia 1940) | [AV62 https://youtu.be/BR0Asbf2bxg] |
| ||

(113) | Truth-of for (112) | |
Let π be a perspectival point, w a world, and g an assignment function. Then: | ||
<P1[v1], P2[v2], P3[v1, v3], P4[v3]> + <A[v1], B[v2], A′[v1], B′[v3]> is true of eventualities <e1, e2, e3, e4> relative to π, w, g | ||
iff <P1[v1], P2[v2], P3[v1, v3], P4[v3]> is true of <e1, e2, e3, e4> relative to π, w, g and <A[v1], B[v2], A′[v1], B′[v3]> is true of <e1, e2, e3, e4> relative to π, w, g, | ||
iff relative to π, w, g, | ||
(pictorial component) | ||
(1) temporally, e1 <e2 <e3 <e4, and | ||
(2) P1[v1] is true of e1, P2[v2] is true of e2, P3[v1, v3] is true of e3, and P4[v3] is true of e4, | ||
and | ||
(musical component) | ||
g(v1) takes part in e1 and g(v2) takes part in e2 and g(v1) takes part in e3 and g(v3) takes part in e4, and | ||
(1) temporally, e1 <e2 <e3 <e4, and | ||
(2) the Loudness and Harmonic stability conditions are satisfied by <<g(v1), e1>, <g(v2), e2>, <g(v1), e3>, <g(v3>, e4>> with respect to <A[v1], B[v2], A′[v1], B′[v3]>, | ||
iff relative to π, w, temporally, e1 <e2 <e3 <e4, and | ||
(pictorial component) | ||
e1 projects to P1 and g(v1) takes part in e1 and projects to variable v1 of P1, | ||
and | e2 projects to P2 and g(v2) takes part in e2 and projects to variable v2 of P2, | |
and | e3 projects to P3 and g(v1) and g(v3) take part in e3 and respectively project to variables v1 and v3 of P3, | |
and | e4 projects to P4 and g(v3) takes part in e4 and projects to variable v3 of P4, (musical component) | |
g(v1) takes part in e1 and g(v2) takes part in e2 and g(v1) takes part in e3 and g(v3) takes part in e4, and the Loudness and Harmonic stability conditions are satisfied by <<g(v1), e1>, <g(v2), e2>, <g(v1), e3>, <g(v3>, e4>> with respect to <A[v1], B[v2], A′[v1], B′[v3]>. | ||
Here too, we can obtain truth conditions relative to a world w by existentially quantifying the assignment function g and the tuple of events <e1, e2, e3, e4>:
(114) | Truth for (112) | |
Let π be a perspectival point and w a world. Then: | ||
<P1[v1], P2[v2], P3[v1, v3], P4[v3]> + <A[v1], B[v2], A′[v1], B′[v3]> is true relative to π, w | ||
iff for some assignment function g, for some eventualities e1, e2, e3, e4, relative to π, w temporally, e1 <e2 <e3 <e4, and | ||
e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, | ||
and | e2 projects to P2, and g(v2) takes part in e2 and projects to variable v2 of P2, | |
and | e3 projects to P3, and g(v1) and g(v3) take part in e3 and respectively project to variables v1 and v3 of P3, | |
and | e4 projects to P4, and g(v3) takes part in e4 and projects to variable v3 of P4, and | |
g(v1) takes part in e1 and g(v2) takes part in e2 and g(v1) takes part in e3 and g(v3) takes part in e4, and the Loudness and Harmonic stability conditions are satisfied by <<g(v1), e1>, <g(v2), e2>, <g(v1), e3>, <g(v3>, e4>> with respect to <A[v1], B[v2], A′[v1], B′[v3]>, | ||
iff for some objects d1, d2, d3, for some eventualities e1, e2, e3, e4, with respect to π, w, temporally, e1 <e2 <e3 <e4, and | ||
e1 projects to P1, and d1 takes part in e1 and projects to variable v1 of P1, | ||
and | e2 projects to P2, and d2 takes part in e2 and projects to variable v2 of P2, | |
and | e3 projects to P3 from π and d1 and d3 take part in e3 and respectively project to variables v1 and v3 of P3, | |
and | e4 projects to P4 from π and d3 takes part in e4 and projects to variable v3 of P4, and | |
d1 takes part in e1 and d2 takes part in e2 and d1 takes part in e3 and d3 takes part in e4, and the Loudness and Harmonic stability conditions are satisfied by <<d1, e1>, <d2, e2>, <d1, e3>, <d3, e4>> with respect to <A[v1], B[v2], A′[v1], B′[v3]>. | ||
-
Local context computation in pictorial sequences
In order to compute cosuppositions triggered by music co-occurring with a pictorial sequence, we must compute the local context of the beginning of a pictorial sequence (possibly enriched with music). The reason is that presuppositions in general and cosuppositions in particular are conditions that must be satisfied in a local context. As is standard (Heim, 1983; Schlenker, 2009, 2010), the local context of an expression E is computed from the global context C (seen as a set of possible worlds compatible with what is taken for granted in the conversation) together with the expressions that appear before E.
We assume that we know the length n of a pictorial sequence <P1, …, Pn> (where P1, …, Pn may contain variables), and ask what is the local context of the ith picture Pi. As in Schlenker (2009, 2010), we take this local context to be (the value of) the strongest conjunct one can add to the target expression <P1, …, Pi-1, …> in such a way that, no matter how it ends (starting with a picture P′i in position i), the truth conditions will not be modified relative to the global context C. We can view a picture sequence of length n as a predicate of perspectival points, worlds, assignment functions and n-tuples of eventualities. This leads to one possible definition of the local context of a picture in a pictorial sequence:Footnote 74
(115) | A possible definition of the local context of a picture in a pictorial sequence of length n |
In a pictorial sequence <P1, …, Pi-1, Pi, …, Pn>, the local context of Pi (1 ≤ i ≤ n) relative to a context set C is the strongest c′ (true of perspectival points, worlds, assignment functions and n-tuples of eventualities)Footnote 75 such that for all P′i, …, P′n, for each perspectival point π, for each w in C, for each assignment function g, for all n-tuples of eventualities <e1, …, en>, | |
<P1, …, Pi-1, P′i, …, P′n> is true of <e1, …, en> relative to π, w, g iff <P1, …, Pi-1, P′i, …, P′n> and c′ are true of <e1, …, en> relative to π, w, g. | |
Note: For i = 1, the requirement is naturally that for all P′1, …, P′n, | |
<P′1, …, P′n> is true of <e1, …, en> relative to π, w, g iff <P′1, …, P′n> and c′ are true of <e1, …, en> relative to π, w, g. |
(116) | Claim: Relative to a context set C, the local context c′ of Pi in <P1, …, Pi-1, Pi, …, Pn> is defined by: |
for each world w, for each perspectival point π, for each assignment function g, for all n-tuples of eventualities <e1, …, en>, c′ is true of <e1, …, en> relative to π, w, g iff relative to π, w, g | |
(i) w is in C, | |
(ii) e1 <…<ei-1 <ei <… <en, | |
(iii) for all k such that 1 ≤ k ≤ i-1, Pk is true of ek. | |
Note: For i = 1, condition (iii) is vacuous and the requirement boils down to conditions (i) and (ii). |
(117) | Proof: We need to show that (i) c′ as defined in (116) satisfies the equivalence in (115), and that (ii) no stronger c″ does (both parts are needed to show that c′ is the strongest such element, as required). (i) is immediate, as the contribution of c′ as stated doesn’t add anything to the beginning (up to and including Pi-1) of the picture sequence. Part (ii) follows from the assumption that there can be null pictures. Assume that some c″ is false of some set of parameters of which c′ is true. We will show that c″ falsifies the equivalence in (115), showing that c′ is in fact the strongest element that satisfies the equivalence. Suppose, then, that for some world w, for some perspectival point π, for some assignment function g, for some n-tuple of eventualities <e1, …, en>, |
(i) w is in C, | |
(ii) e1 <…<ei-1 <ei <… <en, | |
(iii) for all k such that 1 ≤ k ≤ i-1, Pk is true of ek relative to π, w, g,Footnote 76 | |
but c″ is false of <e1, …, en> relative to π, w, g. Take Pi, …, Pn to all be null, which we will write as Øi, … Øn. Now <P1, …, Pi-1, Øi, … Øn> is true of <e1, …, ei-1, ei, …, en> relative to π, w, g, but c″ is false of <e1, …, ei-1, ei, …, en> relative to π, w, g. This falsifies the equivalence in (115), as desired. |
-
Musical cosuppositions
Cosuppositional requirements for musical sequences aligned with pictorial sequences could be computed by requiring that, relative to the global context (i.e. to the context set), the content of the pictorial sequence entail the content of the music. But this would fail to take into account an important asymmetry: if a musical event co-occurs with the beginning of a 2-picture sequence, as in (118), the cosuppositional requirement is arguably that if the first event happens, it should satisfy the content of the music, not that if the entire sequence of events unfolds, the first event will satisfy the content of the music. Concretely: from (118), with a light-hearted whistling co-occurring with P1, we infer that if Asterix punches a Roman soldier, this event will be light-hearted, rather than: if Asterix punches a Roman soldier and then leaves the room, the first event will be light-hearted. The latter requirement makes little sense, since as we watch and hear the mixed sequence, we do not yet know what the end of the pictorial sequence will be, and thus we draw inferences online, on the basis of the beginning of the sequence alone.
(118) | A gif with two pictures <P1, P2>, and a light-hearted musical event on the first one |
|

These considerations show that we need to appeal to local contexts (rather than just to global contexts) as we compute cosuppositional requirements. The initial idea is that relative to a local context, the semantic contribution of a picture Pi to a pictorial sequence should entail the semantic contribution of a musical event Mi to the corresponding (aligned) musical sequence. But in the present framework it makes little sense to talk of the content of a single musical event (because preservation conditions pertain to entire musical sequences, not to individual musical events). So we will state instead that, if a sequence of eventualities <e1, …, ei, …> satisfies the local context of Pi, then if Pi is true of ei, the music should be true of some extension of the sequence <e1, …, ei>.
(119) | A possible definition of a cosuppositional requirement for mixed sequences |
Consider a pictorial sequence <P1, …, Pn> (where P1, …, Pn may contain variables) aligned with a musical sequence <M1[v1], …, Mn[vn]>, and let C be a context set. | |
Then for each i such that 1 ≤ i ≤ n, the local context ci of Pi should guarantee that: | |
for all worlds w, perspectival points π, assignment functions g, and n-tuples of eventualities <e1, …, ei, ei+1, …, en>, if ci is true of <e1, …, en> relative to π, w, g, then: | |
if Pi is true of ei relative to π, w, g, then for some e′i+1, …, e′n, <M1[v1], …, Mn[vn]> is true of <e1, …, ei, e′i+1, …, e′n> relative to π, w, g. |
We are now in a position to illustrate the cosuppositional requirement on the example of (118). We will simplify the discussion by making the assumptions in (120).
(120) | Assumptions |
a. <Ø, W[v1]> is true of <e1, e2> from perspectival point π in world w relative to assignment function g iff in w g(v1) takes part in e2 and in w g(v1)’s action in e2 is light-hearted. | |
b. <W[v1], Ø> is true of <e1, e2> from perspectival point π in world w relative to assignment function g iff in w g(v1) takes part in e1 and in w g(v1)’s action in e1 is light-hearted. |
(121) | Cosuppositional requirement in (118) |
a. Local context | |
The local context c1 of P1 is defined by: | |
c1 is true of <e1, e2> relative to π, w, g iff relative to π, w, | |
(i) w is in C, | |
(ii) e1 <e2. | |
b. Cosupposition | |
For all worlds w, perspectival points π, assignment functions g, and pairs of eventualities <e1, e2>, if c1 is true of <e1, e2> relative to π, w g, then: | |
if P1 is true of e1 relative to π, w, g, then for some e′2, <W[v1], Ø> is true of <e1, e′2> relative to π, w, g, | |
iff for all worlds w in C, perspectival points π, assignment functions g, and pairs of eventualities <e1, e2>, if relative to π, w, e1 <e2, and e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, then for some e′2, <W[v1], Ø> is true of <e1, e′2> relative to π, w, g | |
iff for all worlds w in C, perspectival points π, assignment functions g, and pairs of eventualities <e1, e2>, | |
if relative to π, w, e1 <e2 and e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, then g(v1)’s action in e1 is light-hearted, | |
iff for all worlds w in C, perspectival points π, objects d1 and pairs of eventualities <e1, e2>, | |
if relative to π, w, e1 <e2, and e1 projects to P1, d1 takes part in e1 and projects to variable v1 of P1, then d1’s action in e1 is light-hearted. | |
Informally: if Asterix hits a Roman soldier as shown, his action is light-hearted. |
We turn to the case in which the light-hearted musical event co-occurs with the second picture, as in (122).
(122) | A gif with two pictures <P1, P2>, and a light-hearted musical event on the second one |
|

(123) | Cosuppositional requirement in (122) |
a. Local context | |
The local context c2 of P2 is defined by: | |
c2 is true of <e1, e2> relative to π, w, g iff relative to π, w, g, | |
(i) w is in C, | |
(ii) e1 <e2, | |
(iii) P1 is true of e1, i.e. e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1. | |
b. Cosupposition | |
For all worlds w, perspectival points π, assignment functions g, and pairs of eventualities <e1, e2>, | |
if c2 is true of <e1, e2> relative to π, w, g, then: | |
if P2 is true of e2 relative to π, w, g, then <Ø, W[v1]> is true of <e1, e2> relative to π, w, g, | |
iff for all worlds w in C, perspectival points π, assignment functions g, and pairs of eventualities <e1, e2> such that relative to π, w, e1 <e2, and e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, | |
if relative to π, w, e2 projects to P2, and g(v1) takes part in e2 and projects to variable v1 of P2, | |
then <Ø, W[v1]> is true of <e1, e2> relative to π, w, g, | |
iff for all worlds w in C, perspectival points π, assignment functions g, and pairs of eventualities <e1, e2> such that relative to π, w, e1 <e2, and e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, | |
if relative to π, w, e2 projects to P2, and g(v1) takes part in e2 and projects to variable v1 of P2, | |
then g(v1)’s action in e2 is light-hearted, | |
iff for all worlds w in C, perspectival points π, objects d1, and pairs of eventualities <e1, e2> such that relative to π, w, e1 <e2, and e1 projects to P1, and d1 takes part in e1 and projects to variable v1 of P1, | |
if relative to π, w, e2 projects to P2, and d1 takes part in e2 and projects to variable v1 of P2, | |
then d1’s action in e2 is light-hearted. | |
Informally: if Asterix hits a Roman soldier as shown and then leaves the room as shown, his latter action is light-hearted. |
Within the musical framework developed in this piece (i.e. without stipulating, as in (120), the semantic content of a musical sequence), we can consider a case in which the same picture pair co-occurs with two chords, first a consonant one written as Cons, then a dissonant one written as Diss. Keeping the loudness constant, we may for instance think of the succession <I, 70db>; <cluster, 70db> (where a cluster is a chord comprising at least three adjacent notes separated by a half-tone, hence a highly dissonant chord). As stated, the preservation conditions in (38) impose no requirement arising from loudness (because the two chords have the same loudness), but the harmonic stability of chords is interpreted: in essence, the musical sequence will be true of pairs of eventualities <e1, e2> that share a participant d who is in a less stable position in e2 than in e1 (this is not at all what the pictorial sequence on its own would suggest, so the music will make a non-trivial contribution, possibly even one that contradicts the pictorial content).
(124) | A gif with two pictures <P1, P2>, with a consonant chord co-occurring with P1 and a dissonant chord co-occurring with P2 |
| |

(125) | Let π be a perspectival point, w a world, and g an assignment function. Then: |
<Cons[v1], Diss[v1]> is true of eventualities <e1, e2> relative to π, w, g iff relative to π, w, g(v1) takes part in e1 and e2, and | |
(1) temporally, e1<e2; | |
(2) g(v1) is in a less stable position in e2 than in e1. |
We can now compute the cosuppositional requirements on P1 and P2.
(126) | Cosuppositional requirement on P1 in (124) |
(starting with a counterpart of the underlined part of the derivation in (121)) | |
For all worlds w in C, perspectival points π, assignment functions g, and pairs of eventualities <e1, e2>, | |
if relative to π, w, e1 <e2, and e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, then for some e′2, <Cons[v1], Diss[v1]> is true of <e1, e′2> relative to π, w, g, | |
iff for all worlds w in C, perspectival points π, objects d1, and pairs of eventualities <e1, e2>, | |
if relative to π, w, e1 <e2, and e1 projects to P1, and d1 takes part in e1 and projects to variable v1 of P1, then relative to π, w, for some e′2, d1 takes part in e′2 and projects to variable v1 of P2, and d1 is in a less stable position in e′2 than in e1. | |
Informally: if Asterix hits a Roman soldier as shown, then one can find a later event in which Asterix does something less stable. |
Note that the cosuppositional requirement on P1 is weak: it is just that if Asterix hits a Roman soldier as shown, there will be a later event in which Asterix does something that counts as less stable.
By contrast, the cosuppositional requirement imposed on P2 is more striking.
(127) | Cosuppositional requirement on P2 in (124) |
(starting with a counterpart of the underlined part of the derivation in (123)) | |
For all worlds w in C, perspectival points π, assignment functions g, and pairs of eventualities <e1, e2> such that relative to π, w, e1 <e2, and e1 projects to P1, and g(v1) takes part in e1 and projects to variable v1 of P1, | |
if relative to π, w, e2 projects to P2, and g(v1) takes part in e2 and projects to variable v1 of P2, | |
then relative to π, w, g, <Cons[v1], Diss[v1]> is true of <e1, e2>, | |
iff for all worlds w in C, perspectival points π, objects d1, and pairs of eventualities <e1, e2> such that relative to π, w, e1 <e2, and e1 projects to P1, and d1 takes part in e1 and projects to variable v1 of P1, and e2 projects to P2, and d1 takes part in e2 and projects to variable v1 of P2, with respect to π, w, d1 is in a less stable position in e2 than in e1. | |
Informally: if Asterix hits a Roman soldier as shown and then leaves the room as shown, then Asterix is in a less stable position in the latter than in the former event. |
The cosuppositional requirement imposed on P2 will now be non-trivial and is in fact surprising: despite the violence of the scene in P1, P2 is presented as implying something more unstable—this may for instance suggest that there is something deeply unsettling about Asterix’s leaving the room; or maybe his earlier misdeed is—at last—coming to haunt his conscience.
Audiovisual examples
-
The audiovisual examples can be downloaded at the following URL:
https://drive.google.com/file/d/1k4-6296WVOP32LZtBuiihzXgK4S3xHxS
-
We provide below additional references when they are not given in the main text.
-
AV00 Heider and Simmel (1944), video cited in:
-
AV01 Young People’s Concert. What Does Music Mean? Written by Leonard Bernstein. Original CBS Television Network Broadcast Date: 18 January 1958. Retrieved from: https://www.youtube.com/watch?v=9y9fHoB4P2g
-
AV24, AV25 Saint-Saëns-Le carnaval des animaux (The Carnival of the Animals) (1886), Conductor: Andrea Licata Royal Philharmonic Orchestra.
Retrieved from: https://www.youtube.com/watch?v=5LOFhsksAYw
-
AV27 Psycho, 1960. Film directed and produced by Alfred Hitchcock, and written by Joseph Stefano. Music by Bernard Herrmann.
Retrieved from: https://www.youtube.com/watch?v=MJdYhJsQF5g
-
AV31 Strauss, Don Quixote, Variation II. New York Philharmonic Orchestra (conductor: Leonard Bernstein), Carnegie Hall, November 14, 1963.
Retrieved from: https://www.youtube.com/watch?v=7bOVpiuT2kk
-
AV43, AV44 Strauss, Don Quixote, Variation II. Berliner Philharmoniker (conductor: Herbert von Karajan; cello: Mstislav Rostropovich).
Retrieved from: https://www.youtube.com/watch?v=_6P1WHXKAlk (Gennaro Lettieri)
-
AV48 Album Artur Rubinstein Plays Chopin Licensed to YouTube by SME (on behalf of RCA Classics).
Retrieved from: https://www.youtube.com/watch?v=P7LDXdjfO5o on December 13, 2019.
-
AV49 Retrieved from https://www.youtube.com/watch?v=lIIgGWkBx7o on December 13, 2019. The site gives the information: Youra Guller (1895-1981), recorded 1956.
-
AV50 Les Sylphides. Arrangement for Orchestra by Benjamin Britten, Mono Version. Joseph Levine, American Ballet Theatre Orchestra 1 January 1954.
Retrieved from https://www.youtube.com/watch?v=DQLde6QJXvM on December 13, 2019.
-
AV51 Les Sylphides: Mazurka, Op. 33 No. 2, arranged by Gordon Jacob. Covent Garden Orchestra, Hugo Ringold. From: Chopin, Glazunov: Les Sylphides (Arranged by Gordon Jacob, Mono Version).
Retrieved from: https://www.youtube.com/watch?v=rGi_mW_elkA
-
AV52 Chopin, Mazurka in D major Op. 33 No. 2, orchestration Keller 1908. Performed by the Bolshoi Theatre Orchestra conducted by Algis Žiūraitis. Originally on HMV LP ASD 2925.
Retrieved from: https://www.youtube.com/watch?v=6XXHgNfnxoI
-
AV 54 Heinz Fricke Album Delibes, L.: Coppelia Ballet Suite / Chopin, F.: Les Sylphides (orchestration R. Douglas). Berlin Radio Symphony, Fricke.
Retrieved from https://www.youtube.com/watch?v=jSQbDXEGNUA on December 13, 2019.
-
AV57 Movement on Chopin’s Mazurka Op. 33 n°2, Performance from 1984 at the American Ballet Theatre, on an orchestration close to Britten’s version.
Retreived from: https://www.youtube.com/watch?v=LBJNc3h7Hp8&t=10m46s
-
AV62 Disney’s The Sorcerer’s Apprentice, version from 1940. The Philadelphia Orchestra. Leopold Stokowski.
-
AV68 Stanley Kubrick, 2001: A Space Odyssey. Warner Bros. Pictures
-
AV69 Tieu, Lyn; Schlenker, Philippe; Chemla, Emmanuel: 2019, Linguistic Inferences Without Words. Proceedings of the National Academy of Sciences 116 (20) 9796-9801.
-
AV73, AV74, AV75 Bill Mowbray, Uke and Whistle. From: Kitsch In Sync.
-
AV76, AV77 iMovie audio library, Vintage news short.
-
AV78, AV79 iMovie audio library, Suspense accents 07.
-
AV80 Verdi, Simon Boccanegra, Teatro La Fenice. 2014-2015 (conductor: Myung-Whun Chung), RAI.
Retrieved from: https://www.youtube.com/watch?v=H3ChzGDI-AQ
Rights and permissions
About this article

Cite this article
Schlenker, P. Musical meaning within Super Semantics. Linguist and Philos 45, 795–872 (2022). https://doi.org/10.1007/s10988-021-09329-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10988-021-09329-8