 Tian Linger Xu
Tian Linger Xu Kaya de Barbaro
Kaya de Barbaro Drew H. Abney
Drew H. Abney Ralf F. A. Cox
Ralf F. A. Cox- 1Department of Psychological and Brain Sciences, Indiana University, Bloomington, IN, United States
- 2Department of Psychology, The University of Texas at Austin, Austin, TX, United States
- 3Department of Psychology, Center for Cognition, Action & Perception, University of Cincinnati, Cincinnati, OH, United States
- 4Department of Psychology, University of Groningen, Groningen, Netherlands
The temporal structure of behavior contains a rich source of information about its dynamic organization, origins, and development. Today, advances in sensing and data storage allow researchers to collect multiple dimensions of behavioral data at a fine temporal scale both in and out of the laboratory, leading to the curation of massive multimodal corpora of behavior. However, along with these new opportunities come new challenges. Theories are often underspecified as to the exact nature of these unfolding interactions, and psychologists have limited ready-to-use methods and training for quantifying structures and patterns in behavioral time series. In this paper, we will introduce four techniques to interpret and analyze high-density multi-modal behavior data, namely, to: (1) visualize the raw time series, (2) describe the overall distributional structure of temporal events (Burstiness calculation), (3) characterize the non-linear dynamics over multiple timescales with Chromatic and Anisotropic Cross-Recurrence Quantification Analysis (CRQA), (4) and quantify the directional relations among a set of interdependent multimodal behavioral variables with Granger Causality. Each technique is introduced in a module with conceptual background, sample data drawn from empirical studies and ready-to-use Matlab scripts. The code modules showcase each technique’s application with detailed documentation to allow more advanced users to adapt them to their own datasets. Additionally, to make our modules more accessible to beginner programmers, we provide a “Programming Basics” module that introduces common functions for working with behavioral timeseries data in Matlab. Together, the materials provide a practical introduction to a range of analyses that psychologists can use to discover temporal structure in high-density behavioral data.
Introduction
Our title was inspired by a highly influential paper by Jeffrey L. Elman highlighting the importance of characterizing the temporal structure of behavior for understanding human cognition (Elman, 1990). We believe this is even more true for studying human development. All forms of behavior are organized as cascades of real-time events (Spivey and Dale, 2006; Adolph et al., 2018). The micro-dynamics of infants’ behaviors and their interactions with the world shape their longitudinal trajectories across domains, from motor and language development to socio-emotional development and psychopathology (Thelen, 2000; Adolph and Berger, 2006; Masten and Cicchetti, 2010; Landa et al., 2013; Blair et al., 2015; West and Iverson, 2017). By studying behavior as it unfolds over time, we are able to reveal rich source of information about its dynamic organization, origins, and development (Bakeman and Quera, 2011).
In the past two decades, technological advances in sensing and mobile computing have provided researchers with new ways to collect behavioral data at a fine temporal scale both in and out of the laboratory (de Barbaro, 2019). This has led to the curation of massive multimodal corpora of behavior (Yang and Hsu, 2010; Franchak and Adolph, 2014; Smith et al., 2015; Matthis et al., 2018). Leveraging these massive new datasets to characterize the complex processes of human behavior presents outstanding opportunities, as well as challenges for psychologists in all fields.
Analysis of these rich corpora of behavioral data faces three main challenges. The first challenge is that our world is profoundly multimodal (Smith and Gasser, 2005; Kolodny and Edelman, 2015). Behaviors are organized with multiple time-locked sensory-motor systems which influence each other simultaneously (Garrod and Pickering, 2009; Louwerse et al., 2012; Fusaroli and Tylén, 2016). In daily social interactions, people communicate via gaze, speech, facial expression, gesture and even body movements (Vinciarelli et al., 2009; Knapp et al., 2013; de Barbaro et al., 2016b). At every moment during an interaction, interlocutors respond to the multimodal behavioral signals from one another, make adjustments, and influence one another in real time. This poses a major methodological challenge to researchers interested in the complex structure of activity within and between individuals. Specifically, how should the directional influence from one behavioral variable to another within a system be quantified when multiple variables are interdependent on each other?
Second, behaviors occur at and unfold across many distinct interconnected timescales (Ballard et al., 1997; Wijnants et al., 2012a; Abney et al., 2014; Fusaroli et al., 2015; Darst et al., 2016; Den Hartigh et al., 2016). Facial expressions, eye gaze shifts and bursts of laughter occur at short timescales, often lasting less than one second (Kendon, 1970; Hayhoe and Ballard, 2005; de Barbaro et al., 2011; Knapp et al., 2013). At longer timescales, these micro behaviors are organized into more extended episodes of interaction. For instance, conversations occur at timescales of minutes or hours, contributing to language development (Cox and van Dijk, 2013), whereas friendships can last years or decades (Demir, 2015). Behaviors at different temporal scales have their own emergent properties with hierarchical relations. For example, reading a bedtime story is composed of a sequence of activities including choosing a book, reading the book, and finishing the story with a good night kiss, coordinated through a complex set of embodied vocal and attentional exchanges (Sénéchal et al., 1995; Rossmanith et al., 2014; Flack et al., 2018); walking emerges from tens of thousands of steps and hundreds of failed attempts (Adolph et al., 2011; Adolph and Tamis-Lemonda, 2014); a secure (or insecure relationship) is formed by numerous interactions, play activities and conversations spanning of days, months or even years (Granic and Patterson, 2006). In order to adequately describe and model the multi-scaled nature of human behavior, we need hierarchical methods that can identify or integrate shifts in activity across these temporal scales, for example, to characterize how interaction patterns change during joint activity over the first year (de Barbaro et al., 2013; Rossmanith et al., 2014), or how micro-dynamics of facial activity become organized in laughter vs. crying (Messinger et al., 2012).
The last challenge is that changes in behavioral time series are often non-linear (Carello and Moreno, 2005; Dale and Kello, 2018). We know that behaviors change over time, yet we often ignore the fact that the rate of those changes may also vary from time to time. Conventional statistical methods work under the assumption that variations in the collected behavioral data are stationary across time. However, this assumption does not hold in a variety of complex environments and thus the results are lost in the averaging process. For example, Tamis-LeMonda et al. (2017) recorded the speech generated by the parents in a 45-min session of child-parent naturalistic play session and calculated the word-type over word-token ratio as a measure for speech complexity. The word type token ratio was computed both over the course of the entire play session and within each minute from the start to end. The results showed large temporal fluctuation both in raw speech quantity and word type token ratio over the course of the play session. Parental speech is not uniform; rather, the structure and complexity of the speech is dependent on real-time play content. Aggregative methods, which assume that changes in behaviors and interactions are stationary, are thus likely to miss the true complexity of dynamic activity. As more and more studies aim to discover important questions in more naturalistic experimental settings, we need methods that can reveal non-linear changes in human behaviors across temporal scales.
Overall, it can be said that modern behavioral science faces a “curse of dimensionality” (Bellman, 1961): multimodal, high-density temporal datasets that are collected in relatively unconstrained settings lead to an analysis overload. These vast amounts of data have yet to be truly leveraged to their full advantage (Aslin, 2012; Yu et al., 2012). Critically, there are few if any domain-specific analytical tools that can characterize high-density multimodal dynamics of human activities using such emerging datasets. Indeed, the complexities of these systems mean that no single tool will work to quantify the complex behaviors and uncover intriguing patterns (Gnisci et al., 2008). In this paper, we provide readers a practical introduction to an ensemble of four analytic techniques to characterize the temporal structure of high-density behavioral data. Each technique is introduced in a module associated with sample data and code available on Github, https://github.com/findstructureintime/Time-Series-Analysis (Xu et al., 2020), as well as conceptual material in the manuscript text, including an explanation of the technique and its application to the showcase example data provided in the code module.
The techniques covered in the modules can be used to characterize distinct aspects of the temporal structure of behavioral data. The first module provides a step-by-step “programming basics” tutorial that introduces users to common behavioral timeseries data as well as scripts necessary to import and manipulate these data. The goal is to provide novice users the necessary scaffolding to begin to work with behavioral timeseries data and make sense of the subsequent modules. It also provides scripts for transforming data to and from common data formats used across all modules to facilitate modifying module material to work with user data. The second module focuses on the visualization of raw behavioral data. Visualizations allow researchers to observe the rich dynamics of complex multimodal data across multiple timescales, making structure in activity apparent where it may not be theoretically prespecified. Visualizations can thus suggest the most appropriate variables or analyses as part of a “human-in-the-loop” analysis (Card et al., 1999; Shneiderman, 2002). The third module introduces a way to describe the distributional structure of temporal events: Burstiness calculation. This is a method to quantify the temporal regularity of occurrence of events (Goh and Barabási, 2008). The fourth module explains Chromatic and Anisotropic Cross-Recurrence Quantification Analysis which can be used to characterize coupled non-linear dynamics over multiple timescales. These techniques can reveal different types of recurrent behavioral patterns and can quantify asymmetries in the coupling strength between two temporal variables. The last module introduces Granger Causality as a novel way to quantify the directional relations among multiple behavioral time series. Multiple channels of behaviors are often interdependent with each other. This technique provides a way to investigate the unique influence from one behavioral time series to another while taking all the variables in the system into consideration.
In sum, the techniques introduced in this paper cover a wide range of analysis needs for psychologists dealing with time series data: from visualization to computational analysis; from quantifying distributional regularities to discovering underlying non-linear structures and synchronization patterns; from describing the patterns within one behavioral time series to computing the quantitative directional relations from multimodal behavioral time series. Our goal is that both beginner and experienced programmers will be able to selectively benefit from the provided materials. Novice programmers will benefit most from the modules if they carefully work through the material in Modules 1 and 2 before attempting to run or modify the later modules. More experienced programmers can more selectively focus on the modules of greatest interest to them, modifying scripts to meet their own analysis goals.
All associated scripts can be run and edited using Matlab 2018a and later versions available on Windows, macOS, and Linux operating systems. While Matlab requires a paid subscription, many institutions offer free access to this software. Readers who are not familiar with Matlab are advised to reference the Mathworks website where a complete list of free campus licenses is available. Alternatively, readers can use the open source GNU Octave (version 5.2.0 or later, which runs on GNU/Linux, macOS, BSD, and Windows) to run and modify the scripts.
Module 1: Time Series Programming Basics
To make our modules accessible to novice programmers, the first module provides a tutorial introducing novice programmers to main temporal data types commonly collected in behavioral science research and basic syntax useful for working with multimodal temporal behavioral data. The module also walks users through importing, manipulating and making simple plots of timeseries data. The goal is to provide users with little to no programming background with relevant programming experience to begin working with their own temporal datasets. While programming expertise is a continuous learning practice that is never truly “complete,” these scripts can serve as a jumping off point by which inexperienced readers can build the skills and confidence necessary to understand and modify the scripts in the subsequent modules to accommodate their own data and research questions.
Additionally, this module provides scripts to transform outputs of annotation software commonly used in developmental science research, such as Elan, The Observer, or Mangold Interact (Noldus, 1991; Wittenburg et al., 2006; Mangold, 2017) into data formats compatible with all subsequent modules. These scripts thus further enable novice programmers to apply subsequent modules to their own data.
Methods
The most common types of temporal data collected in developmental science research are event data and timeseries data. Event data are those in which each event of interest is indicated by an onset timestamp, an offset timestamp and a third value that represents the behavioral code, i.e., looking at or manipulating a certain target object. Event data are commonly used when indicating discrete behaviors, including for example, sequences of infant gaze or dyadic interaction states. Event data could also include irregularly spaced data such as a list of ecological momentary assessments, paired with the time they are completed. Within the field of developmental science, event data are often generated by human annotation (i.e., labeling) of audio or video records. By contrast, timeseries data are data points sampled at equally spaced intervals in time with a specified sampling rate, such as 10 HZ which means 10 data points are sampled at every 100 ms. Examples of common behavioral timeseries data include frame-by-frame presence or absence of mutual gaze between two interactors, positive or negative affect state recorded every second throughout a 10-min play session or observation of the presence of caregiver’s face in infant’s first person view within every 5 s interval.
Binary spike train data is a specific type of timeseries data in which a ‘1’ represents the onset of an event of interest and a ‘0’ represents instances when an onset did not occur (also known as “point process data”). This type of time series data is used to compute inter-onset intervals, i.e., the duration of time between the onset of consecutive events or to construct likelihood models of an event’s occurrence.
Note that any event sequence data can be transformed into a timeseries. Additionally, timeseries data can be transformed into event data, although for continuous timeseries this may require setting thresholds to “parse” the data into distinct events. Finally, event data can be transformed to binary spike trains by including only the onsets of the events in the binary spike train timeseries. This is critical as some analyses require one data format rather than the other. In particular, event data inputs are used in Modules 1 and 2 (Visualization), timeseries data inputs are used in Modules 1, 2 (Visualization) and 4 (Recurrence Quantification Analysis), and binary spike train inputs are used in Modules 3 (Burstiness analysis) and 5 (Granger Causality).
Sample Data and Scripts
This module includes seven scripts as well as step-by-step tutorial instructions in the readme.md.
Data
To introduce readers to timeseries and event data type, this module includes samples of simple data from a study of the development of joint activity, which examined frame-by-frame annotations of all mother and infant gaze and touching behaviors to a set of three available objects (de Barbaro et al., 2016b). Additionally, it includes several sample files exported from the annotation software Mangold (Mangold, 2017) that will be used to practice data import and data format transformation. The files contain multiple dimensions of data, including mother and infant affect events. Users will also create visualizations with this sample dataset in Module 2.
Scripts
The first script (programmingBasics.m) provides basics of data file import and data manipulation, including accessing and appending values into data arrays as well as calculating basic features of behavioral temporal data. Two additional scripts provide basics for plotting and modifying simple event and timeseries data (timeseriesBasics.m and eventDataBasics.m). These scripts allow users to view behavioral data with simple plots and provide syntax for common modifications of color and line specification and finishing touches for axes and titles. They also introduce users to techniques for summarizing and combining data streams, as well as “for loops” for cycling through arrays. All three scripts are designed to be run one line at a time, with scripted material designed to showcase various types of manipulations and their outputs, as detailed in the readme.md file and the inline documentation in scripts. Additionally, the first two scripts contain practice problems with solutions to challenge the user to begin independently modifying scripts.
The fourth script guides the users through the process of importing and transforming event-coded data from common annotation software. Outputs from annotation software typically contain both numerical and text data which are difficult to import using common file read functions. The annotationImport.m script provides code to transform outputs of annotation software into a clean event-data format that can be easily manipulated and accessed in Matlab and will be used in Module 2. The fifth and sixth scripts, convertEvents2Timeseries.m and convertTimeSeries2Events.m, offer codes to convert imported event data sequences into timeseries format and timeseries data into event format temporal data. Finally, the script convertEvents2Binaryspikes.m can be used to convert event data exported by the annotationImport.m function into binary spike train data. These scripts thus allow researchers to more easily transform their own input data for use in subsequent modules, as well as other potential applications.
Module 2: Getting to Know Your Data: Visualization of High-Density Multi-Modal Interactions
This module introduces more complex techniques for visualizing behavioral data streams. With advances in video and sensing technology, it is increasingly possible for researchers use high-density multidimensional data to gain insight into the real-time processes of behavior (de Barbaro, 2019). For example, researchers interested in understanding of early emotion regulation could annotate—or potentially automatically detect markers of—frame-by-frame changes in mother and child affect, gaze, and patterns of touching to examine real-time strategies mothers utilize to regulate children’s distress and their impacts on subsequent soothing (see, e.g., Ye et al., 2012; Kim and Clements, 2015; de Barbaro et al., n.d.). These annotations could be further synchronized with heart rate or electrical brain signals (de Barbaro et al., 2017; Wass et al., 2019) to examine concurrent physiological regulation, or to assess whether individual differences in physiology might moderate the impacts of mothers’ regulation efforts.
Data visualization can highlight the structure of such complex behavioral processes within and between participants, providing researchers key insights throughout the analytical process (Gnisci et al., 2008). In early stages of analysis, visualizations of raw or minimally processed data can provide insights into underlying patterns and regularities. Critically, the novelty of high-density multimodal datasets means social scientists have limited vocabulary and insight into these data at such high levels of granularity. In this case, summarizing data using prespecified measures can be misleading, and has the potential to overlook the most relevant or interesting features of the data. By providing access to raw data for inspection, visualizations can highlight temporal or multi-modal structure that may not be specified by existing theory (Yu et al., 2012).
In later stages of analysis, data visualization can ensure the validity and quality of operationalizations of phenomena of interest, as well as help to interpret observed results. For example, one useful approach for working with high-density datasets is to identify repeated “events” occurring within the data stream (de Barbaro et al., 2013; Granic and Hollenstein, 2016). Such events can help to parse the unfolding interaction into manageable and relevant instances of behavior. If events are derived from raw data, marking their position within the timeline of raw data can help to ensure valid and meaningful definition of event boundaries. Additionally, iterative visualization of raw data with increasingly processed data can indicate the density and temporal ordering of events relative to other data streams, helping to guide the selection of relevant analytic techniques.
Methods
Creating intuitive and meaningful visualizations involves a number of methodological considerations. Collected temporal data may include multiple channels, each representing a different dimension or modality of behavior, each with potentially distinct properties. For example, researchers may want to combine multiple channels of temporal data representing behaviors that are binary, such as the presence or absence of joint gaze, with data that have many different mutually exclusive categories, such as qualitatively distinct emotions or dyadic states, or continuous data, such as physiological signals, or affect levels ranked from more negative to more positive. Color, positioning, and line style can be used to represent these different types of activity to most intuitively highlight the structure of multimodal behavior. For example, qualitatively distinct activities may be better represented with different colors whereas continuous affect may be best represented via a timeseries. Alternatively, the structure of continuous affect data may be best revealed by parsing continuous affect data into “positive,” “negative,” and “neutral” categories. Ultimately, these decisions are made through a mixture of theory, intuition, and simple trial and error.
Overall, visualization of high-density multimodal data often requires flexibility not present in off-the-shelf visualization tools included with data collection or annotation software. Scripting visualizations affords infinite control over these decisions, ultimately allowing customizable exploration of data structure. The current module thus showcases three sets of scripts used to visualize complex multimodal data collected by developmental scientists. The datasets span multi-participant event data, physiological data synchronized with event data, and multiple synchronized channels of physiological activity from a wearable sensor. Finally, the scripts in this module allow batch processing of multiple study participants, facilitating within- and between-participant comparisons. We recommend beginning with visualizations of 6–10 study participants to access the structure and variability of your data, increasing this number if saturation is not apparent.
Sample Data and Scripts
This module builds upon the basic data manipulation and plotting techniques provided in Module 1 to provide readers with experience visualizing more complex multimodal and multi-participant behavioral data. The visualization module includes sample data from three different datasets, three main scripts including a demo script demo_visualizations, and a readme.md file that provides instructions for running each script. The demo script can be used to create a number of appealing plots of high-density multimodal behavioral data.
Data
To provide users experience plotting a variety of different types of data streams, three sample datasets are provided: (1) frame-by-frame mother-and-infant affect data in a sample of mothers with a history of depression (Lusby et al., 2014; Goodman et al., 2017), (2) infant heart rate data collected over the course of a laboratory session that includes attention and learning tasks presented on a monitor (de Barbaro et al., 2016a, 2017) and (3) pilot data of the author of the module wearing a wrist-mounted physiological sensor that collects heart rate, electrodermal activity and motion on a day that she gave a department seminar. To use these scripts on their own data, users will need to have data formatted as timeseries and/or events using the scripts annotationImport.m and convertEvents2Timeseries.m in Module 1.
Scripts
The three scripts in this module provide the user with practical visualization techniques for multimodal datasets. The script multiParticipantEventPlotting.m plots three dimensions of mother and infant affect into a single plot, distinguishing positive, neutral, and negative affect via intuitive color and vertical positioning. The plotTimeseriesWithEvents.m script combines synchronized timeseries (infant heart rate) and event-data (tasks) into a single plot to provide insight into potential relations between infants’ activities and physiological changes. Finally, the script plotSensorData.m script plots three different types of wearable physiological data in three plots on a single figure, to indicate the temporal relations between these measures. This script processes Unix timestamps, a specialized time format commonly used by sensor platforms.
Results
To provide examples of the types of insights that visualizations can provide, we will walk through the figures generated by the scripts multiParticipantEventPlotting.m (Figure 1) and plotTimeseriesWithEvents.m (Figure 2).
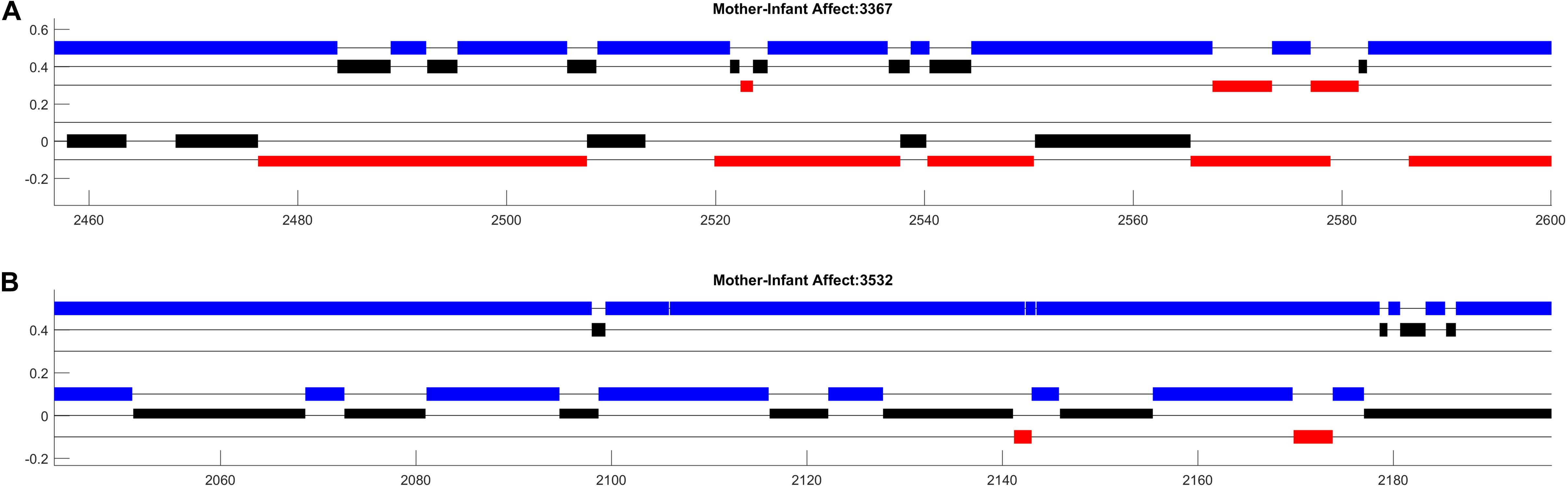
Figure 1. Affect data from two mother–infant dyads participating in a face-to-face free play session at 3 months of age. The x-axis shows time (in seconds) and the y-axis distinguishes different dimensions of affect. Maternal affect is represented in three rows at the top (A), infant affect is represented in three lower rows (B). For both mothers and infants, the highest of the three rows (in blue) represent positive affect, the middle row (in black) represents neutral affect, and the bottom row (in red) represents negative affect.
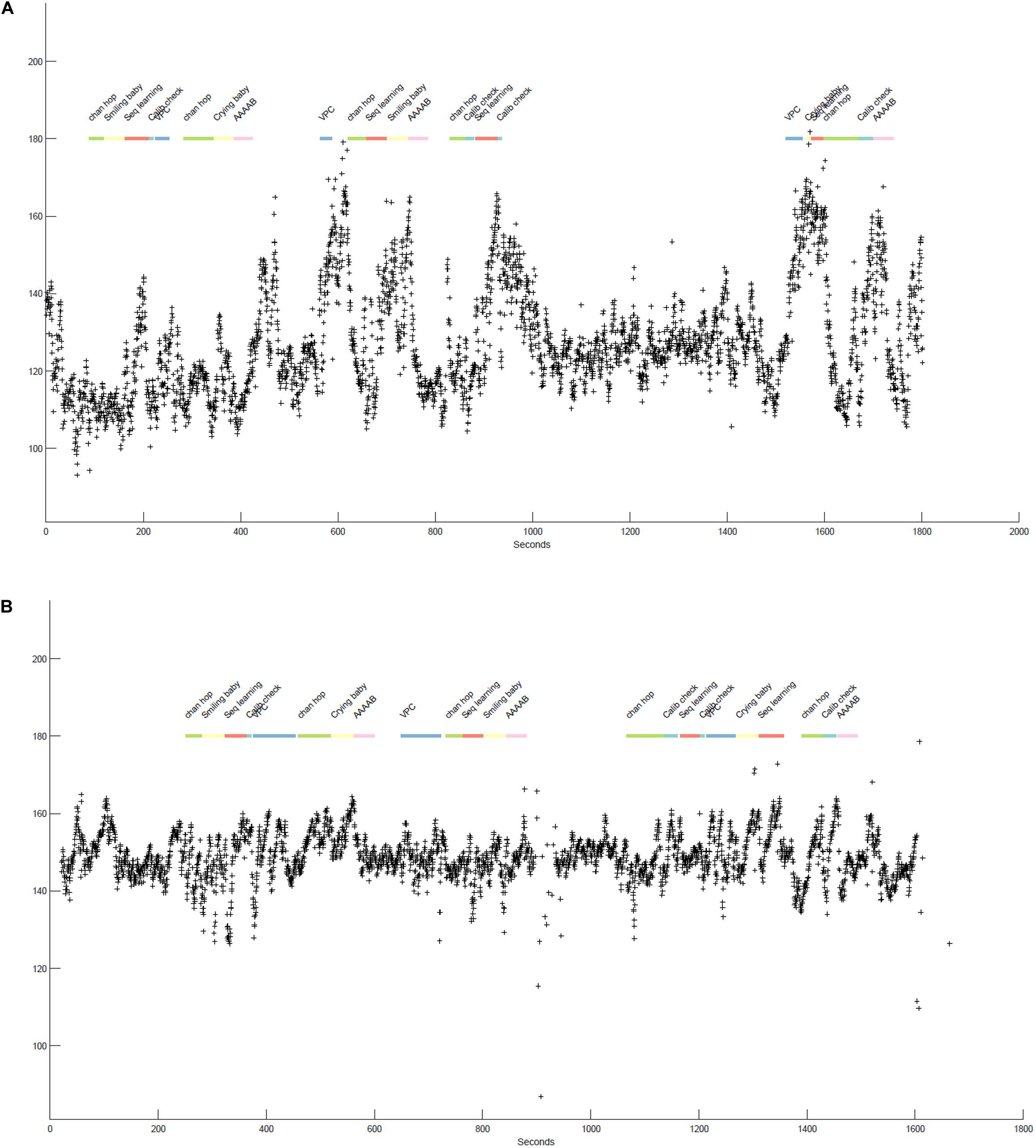
Figure 2. (A,B) illustrate the beat-by-beat heart rate data (indicated by + symbols) of two infants participating in various tasks over the course of a laboratory session. The x-axis shows time (in seconds) and the y-axis specifies the heart rate values in equivalent beats-per-minute. The colorful line at the top represent the specific tasks infants participated in, differentiated by color and labels. The boundaries of each segment indicate the start and stop times of each task.
Figure 1 displays approximately 150 s worth of dynamic affect data from two mother–infant dyads participating in a face-to-face free play session at 3 months of age. While the color and positioning parameters of this image could be arbitrarily changed, setting these parameters in an intuitive way can greatly facilitate the comprehension of your plots (Tufte, 2001). In this example, higher position on the y-axis corresponds to more positive affect, the color red indicates distress, and colors are consistent across mother and infant affect states. Additionally, the simple black lines (“kebab lines”) help to orient the observer to where data could be present. Finally, setting the width and height of the bars such that that each dimension of mother and infant affect is “touching” highlights potential contingency between mother and infant affect.
Organized in this way, the plots highlight salient aspects of interaction that can be examined further in systematic analyses. First, in both dyads we observe that both mothers and infants’ cycle between different affect states across the session. Additionally, there appear to be many instances of contingent affect shifts between mothers and their infants. Note, for example, that each shift in affect displayed by the mother in dyad 3532 (Figure 1B) appears to be contingent on a shift in infants’ affect. Perhaps most strikingly, we observe strong differences in the expression of negative affect between the two infants, such that one infant displays less than 10 s of negative affect while the other displays nearly 10 times that. Visualizations of additional participants (not shown) indicated high levels of infant negative affect expression in 10–20% of mother–infant interactions. This led us to consider that there was large variation in the challenge faced by mothers in responding contingently to their infants which may moderate the relations between contingent affect responding and infants’ affect development longitudinally. It also led us to wonder whether patterns of maternal activity were contributing to these variations in infant affect, given that caregiver sensitivity is often associated with infant negative affect expression. We are exploring these questions in ongoing research (de Barbaro et al., 2020).
Figure 2 displays approximately 25–30 min of two 12-month-old infants’ heart rate data as they participate in different tasks during a laboratory session. Together, the plots highlight individual differences in infant heart-rate reactivity as well as the presence of task-associated changes in heart rate. Differences in heart rate reactivity appear stable within each infant across tasks, i.e., Figure 2A consistently shows strong responses to tasks with increases in heart rate ranging from 20to 80, while Figure 2B shows much more moderate task-associated increases in heart rate, with heart rate typically increasing by 20–30 beats from task onset.
Neither infant shows noticeable session-level effects, that is, heart rate increases are generally followed by a return to some sort of “baseline.” However, where there is a gap between tasks (e.g., between 1,000 and 1,600 s for Figure 2A), both infants heart rate is meaningfully lower and more stable, again suggesting that the tasks themselves are arousing or potentially stressful for the infants. Finally, the stretch of low heart rate in both infants at the start of the task, encompassing the “chan hop” and “smiling baby” tasks, suggested that this segment of the session might function as a valid baseline. We followed up on the generated insights in multiple manuscripts. For example, we examined individual differences in heart rate reactivity to the visual paired comparison (VPC; habituation) task and their association with performance on this task (de Barbaro et al., 2016a). We also examined how the changes in heart rate across the session were associated with changes in attention as assessed by eye-tracker gaze duration (not plotted here; see de Barbaro et al., 2017).
Discussion
As Bakeman and Quera (2011) note, sequential analyses are not “off the shelf.” No single analytic tool can characterize dense, multi-channel behavior dynamics of social interaction. Instead, investigators should anticipate an iterative process to converge on the analytic tools that will capture the temporal structure of their data (de Barbaro et al., 2013). Visualizations of high-density behavioral data can prove critical in this process. In particular, data visualized in an intuitive way can highlight salient aspects of the temporal structure of activity and thereby guide the selection of relevant analytic techniques.
Module 3: Tapping Into the Temporal Structure of Developmental Data Using Burstiness Analysis
In this section, we will introduce methodological advancements for how developmental scientists can apply simple distributional analyses to time series data to estimate the temporal structure of event-level datasets. The burstiness analysis can be useful for psychologists interested in studying the temporal patterns of behavior. For example, the ability to quantify and/or categorize temporal patterns of behavior using a simple metric, can lead to generating and testing hypotheses about how a particular behavior unfolds over time. This analysis, first introduced in statistical physics (Goh and Barabási, 2008), characterizes spike trains of human behavior in the dimension of burstiness of the spike train of interest. Burstiness is a distributional measure that provides an estimate of a system’s activity patterns spanning from periodic (−1 < B < 0), to random (B ∼ 0), to theoretically maximal burstiness (0 < B < 1) (see Figure 3).
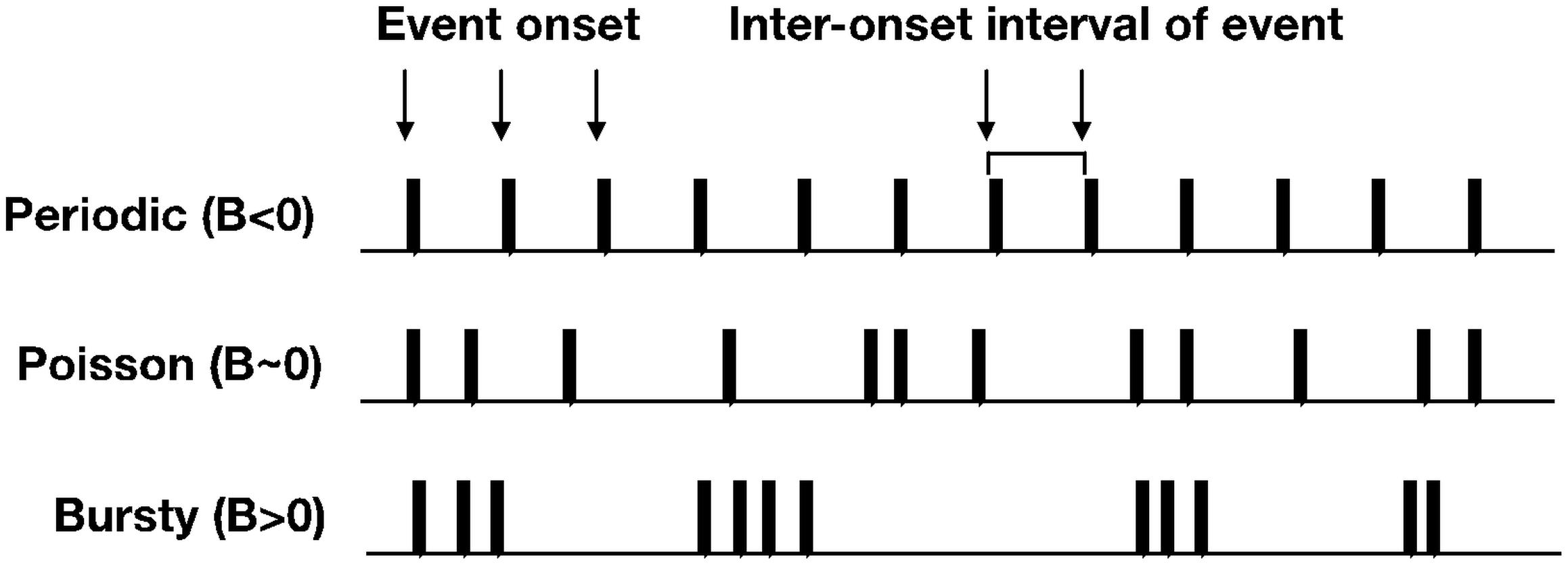
Figure 3. Toy examples of spike trains that approximate periodic, Poisson, and bursty temporal structure.
Methods
As noted above, the analysis requires the user to have a binary spike train of 0 s and 1s in which a ‘1’ represents the onset of an event of interest and a ‘0’ represents instances when an onset did not occur. Inter-onset intervals are computed from the binary spike train and then the inter-onset interval distribution is submitted to an estimation of burstiness. A simple equation provides an estimation of burstiness with the assumption of an infinite time series,
where στ is the standard deviation of the inter-onset interval distribution and μτ is the mean of the inter-onset interval distribution. A recent addition to the burstiness analysis includes an updated equation that takes into account the amount of inter-onset intervals in a distribution and therefore is more relevant for empirical work using finite time series (Kim and Jo, 2016). Estimates from both equations converge when the inter-onset interval distributions include τlength > 100 intervals.
Sample Data and Scripts
The burstiness module contains two samples of data, two scripts including a demo file that quantifies and visualizes burstiness across different data streams, and a readme.md file that provides step-by-step instructions for running the scripts.
Data
Example data come from a randomly selected subject in a developmental study where ego-centric views were collected at a sample rate of 1/5 Hz in infant’s natural environments (see Jayaraman et al., 2015, 2017; Fausey et al., 2016; Jayaraman and Smith, 2019). Human coders coded each frame for the presence of hands or faces in the field of view. Sample data include two spike train series, one for when a hand came into view and one for when a face came into view. To use this script on their own data, users will need to have data formatted as binary spike trains, which they can do using the convertEvents2Binaryspikes.m script in Module 1. Additionally, the user should be aware of the sampling rate that was used to collect and process the data as this will constrain interpretations of the magnitudes of inter-onset intervals.
Scripts
The demo script demo_bursty.m calculates the burstiness of the two example spike trains. It also generates a periodic spike train and a random spike train generated from a Poisson process and calculates the burstiness of those data streams to provide a comparison for the burstiness values of the sample data. Finally, it generates a plot (Figure 4) to provide a visual comparison of the burstiness of each spike train as well as a distribution of the inter-onset intervals of the sample data streams. Additional details are provided in the script in-line documentation.
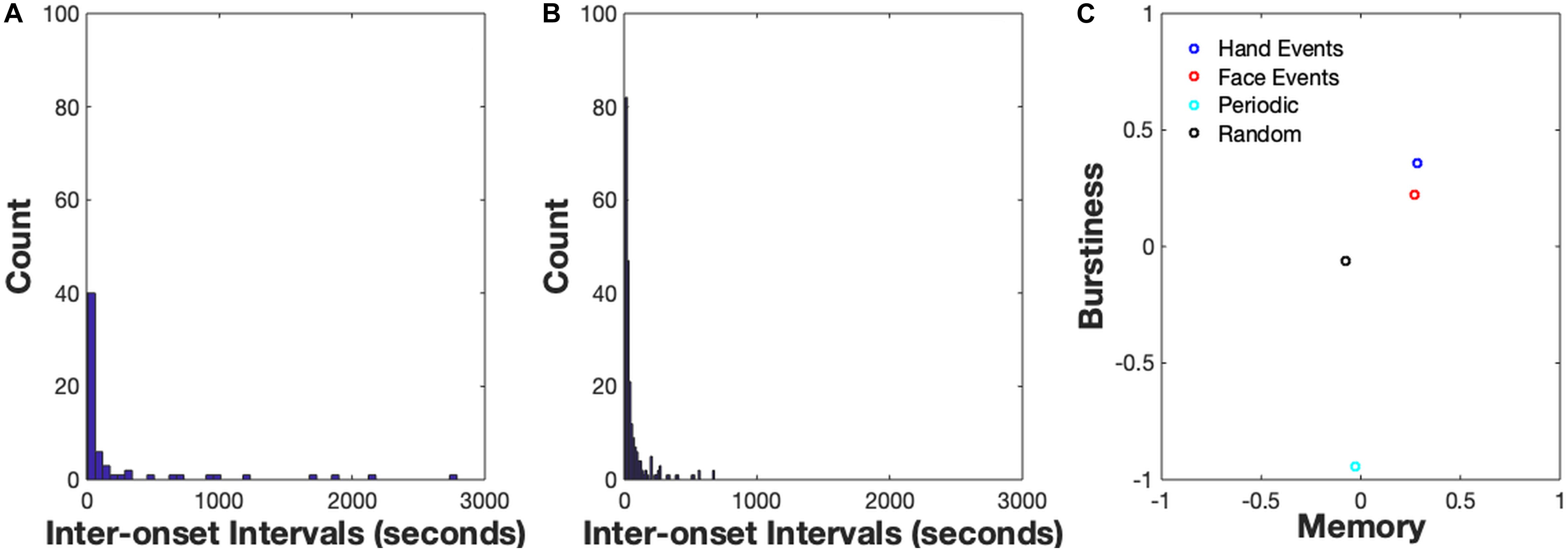
Figure 4. (A) Inter-onset Interval Distribution for hand events, (B) Inter-onset Interval Distribution for face events. An IOI distribution for a periodic signal (B < 0), the user would observe high counts of IOIs in one particular timescale, e.g., a high amount of IOIs with length = 10 s. An IOI distribution for a bursty signal (B > 0) is typically right-skewed, suggesting a high frequency of short IOIs and less-frequent (but non-zero) amount of longer IOIs. (C) Burstiness-Memory plot. On the x-axis is a measure of the memory of the event series which is commonly estimated by the lag-1 autocorrelation coefficient.
Results
The results from the demo_bursty script are shown in Figure 4. The first two images display the distribution of inter-onset-intervals of the two sample data streams. The IOI distribution for a periodic signal (B < 0) would indicate high counts of IOIs at one particular timescale, e.g., a high amount of IOIs with length = 10 s. By contrast, an IOI distribution for a bursty signal (B > 0) is typically right-skewed, suggesting a high frequency of short IOIs and less-frequent (but non-zero) amount of longer IOIs. Estimates of Burstiness, B, are indicated along the y-axis of the right-most image in the plot. The x-axis is a measure of the memory of the event series which is commonly estimated by the lag-1 autocorrelation coefficient. Due to the introductory nature of this module, we won’t discuss the concept of memory in detail here, please see Goh and Barabási (2008) for a comprehensive explanation. Note that the Burstiness values of the empirical spike trains are both positive, meaning they are both in the ‘bursty’ regime as opposed to the ‘random’ or ‘periodic’ regime: B = 0.22 for the Face spike train and B = 0.36 for the Hand spike train. The two burstiness estimates suggest that bouts of hand activity are more clustered in time and have longer periods of time when hand activity was not occurring relative to bouts of face activity. Observing that the hand events are more bursty than the face events also suggests that bouts of manual activity are likely occurring at faster timescales compared to face events coming in and out of the infant’s view. Moreover, observing that both the hand events and face events are not organized in a periodic or random temporal structure suggests a more complex collection of constraints acting on the two information sources, such as social interactions, toy play, etc. Finally, the burstiness estimate of the randomly distributed events is approximately 0 and the burstiness of events generated from the periodic distribution is slightly less than −1, as would be expected of these distributions.
Discussion
The burstiness analysis affords the researcher with the ability to provide a simple index of the temporal structure of an event of interest. One critical limitation of the application of the burstiness analysis to a wide range of behavioral event series is the relative magnitude of the B estimate across datasets. This limitation suggests that the user should use caution when directly comparing B estimates across datasets. One strategy that has been used in recent research that applied the burstiness analysis to multimodal human interaction (Abney et al., 2018), was to generate bootstrapped confidence intervals to determine categorical boundaries of periodic, random, and bursty temporal structure. For example, a Poisson process is generated by an interevent interval distribution of an exponential distribution. Therefore, a researcher can generate confidence intervals by first simulating a sample of interevent interval distributions with similar properties to the empirical dataset (e.g., average size of interevent interval distribution) but from an exponential distribution and then estimate the lower and upper bound of the confidence intervals of what the burstiness analysis would suggest would be as Poisson (B ∼ 0). Generating bootstrapped confidence intervals of the lower and upper bounds of what the burstiness analysis would classify as ‘Poisson’ can allow a researcher to then classify empirical spike trains with known burstiness values. Although this strategy allows the researcher to classify behavioral events into intuitive categories of temporal structure, the main limitation of this strategy is that classification does not afford the researcher to develop, test, and reject hypotheses about the magnitude of B estimates and cognitive mechanisms. Despite the important limitations the user should consider, the burstiness analysis provides a simple metric that can inform researchers about the temporal structure of behaviors of interest.
Module 4: Cross-Recurrence Quantification Analysis of Dyadic Interaction
The techniques introduced in this section are variations of Recurrence Quantification Analysis (RQA) (Marwan et al., 2007), which is a powerful non-linear time-series technique originating from the natural sciences, and which has gained popularity in the social sciences in the past two decades. RQA can be applied to data of a continuous and nominal measurement level, and to a single data stream as well as to a pair of data streams. The latter version of the technique is called Cross-Recurrence Quantification Analysis (CRQA) (Shockley et al., 2002). In this module we will focus on two recent advancements for nominal data streams, known as Chromatic CRQA and Anisotropic CRQA (Cox et al., 2016), which are particularly suited for the analysis of differentiation and asymmetry in dyadic interaction. This choice is given by two observations: the first is that many datasets in psychology originate from annotations of audio or video recordings, from manual or automated registration of gaze across regions of interest (ROI), or from a comparable procedure resulting in temporally ordered sequences of distinct behavioral categories (i.e., nominal event or time-series data). The second is that many research questions pertain to social interaction, in which a number of people, typically a dyad, are engaged in some form of interpersonal behavior, for instance, two children collaborating on a task (Guevara et al., 2017) or a mother–infant feeding interaction (van Dijk et al., 2018).
CRQA enables researchers to study attunement and coordination in such dyads. Dyadic interaction typically consists of recurrent patterns of several types of matching and non-matching (i.e., collective) behaviors of the interaction partners. These patterns can be of various duration and are potentially coupled across different episodes of the interaction. That is, interaction partners might influence each other’s behavior (almost) immediately, but this influence might also be delayed for some shorter or longer period of time. Also, dyadic attunement is sometimes brief and consists of only a single behavioral category, but it might also be a lengthier behavioral sequence consisting of several different categories. CRQA detects such behavioral patterns and quantifies their dynamic characteristics and temporal associations. In addition, one may wish to track the different types collective behaviors of the dyad separately, and weigh the relative contribution of each of the interaction partners to the recurrent patterns. Chromatic and Anisotropic CRQA facilitate this. It can reveal temporal structure in data streams across different timescales, which remains inaccessible to most other time-series methods. There are several good texts explaining CRQA for continuous and nominal time series emphasizing conceptual issues and applications (Webber and Zbilut, 2005; Marwan et al., 2007; Wijnants et al., 2012b). In the following sub-sections, we will introduce the technical underpinnings of Chromatic and Anisotropic CRQA, detail the key scripts in our code modules, and explain the derived measures and the features of Chromatic and Anisotropic CRQA with an example.
Methods
The central feature of CRQA is the Cross-Recurrence Plot (CRP; Figure 5), which visualizes the temporal organization of the interaction based on ‘recurrences.’ What counts as a recurrence is pre-defined by the researcher, and in its most general form it can be any matching pair of individual behaviors of the two interaction partners (e.g., shared gaze, both lifting, as well as complementary “matches” such as speak-silence, offering-accepting). For nominal data a CRP is easily constructed by tracking such behavioral matches across the entire lengths (N) of the two data streams. By holding one of the data streams along the horizontal axis and the other along the vertical axis, the occurrences of behavioral matches are plotted in the two-dimensional CRP with N rows ad N columns. Each dot in the CRP represent the instance where a behavioral state of the horizontally presented interaction partner is matched in a specific way by that of the vertically presented one. When several different types of behavioral matches (i.e., qualitatively different combinations of behavioral categories) need to be tracked simultaneously, this can be represented in the CRP with a color coding. This is represented in Figure 5, where you can see two colors, representing two types of behavioral match (the white areas are the remaining non-matching states). This version of the method is called Chromatic CRQA (see Cox et al., 2016).
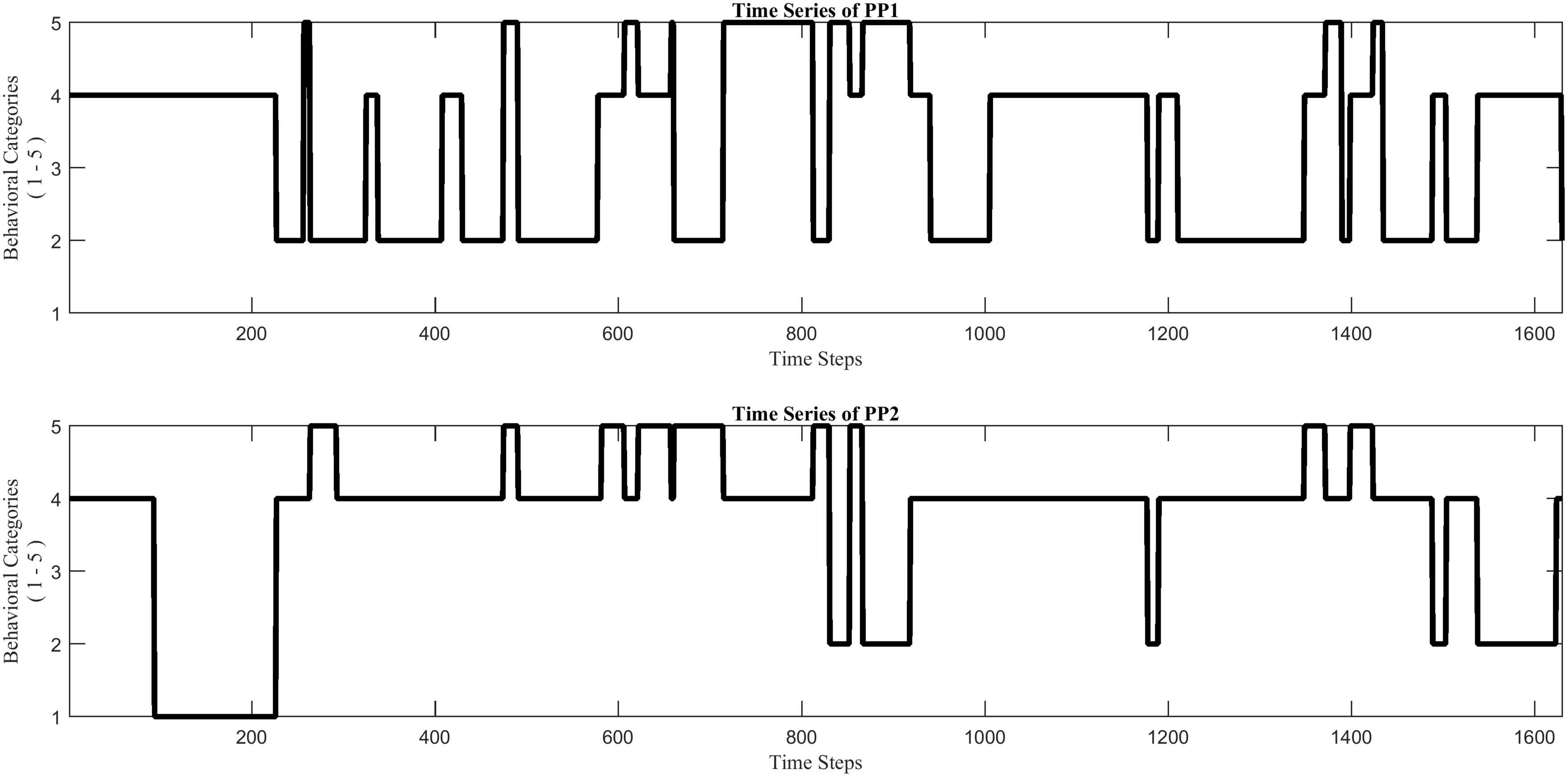
Figure 5. Two nominal time series (example_data.mat), each of which reflects the stream of collaborative behaviors of a child during a dyadic interaction, coded by using the same five specific behavioral categories (1–5) for each.
The distribution of the dots across the CRP captures the interactional dynamics, and several measures can be derived to quantify this. The simplest measure is the recurrence rate (RR), which is the proportion of behavioral matches. RR provides a crude measure of coordination between the two interaction partners across multiple timescales. Note that individual dots are no longer visible in Figure 5, because they tend to constitute smaller and larger rectangular patterns. These are quite common in a CRP of nominal data coming from dyadic interaction, and reflect both a persistence in the interaction as well as the coarse-grained nature of the measurement (Cox et al., 2016; Xu and Yu, 2016). A rectangular pattern indicates an episode of behavioral-category use of one interaction partner which was accompanied by some episode of matching behavioral-category use of the other interaction partner. The more asymmetric the pattern, the briefer the matching behavior is performed by one interaction partner compared to the other. The overall asymmetry (or rather: anisotropy) in the CRP is therefore related to asymmetries in the dynamics, and provides information about differences in the relative contribution and dominance between the interaction partners.
Given the rectangular structure and the possible anisotropy of the CRP, it makes sense to quantify the horizontal and vertical extent of the behavioral patterns separately and analyze the differences between the two orientations. This version of the method is called Anisotropic CRQA (Cox et al., 2016). The CRQA measures in the CRQA module quantify the proportion of patterns, their mean and maximum length, and their entropy, for both orientations. Specifically the measures are: (1) LAM (Laminarity), which is the proportion of matches constituting patterns in the vertical and horizontal orientation, (2) TT (Trapping Time), which is the average length of vertical and horizontal patterns, (3) Max_L, which is the length of the longest vertical and horizontal pattern, and (4) Ent_L, which is the Shannon entropy of vertical and horizontal length distribution. Note that each of these measures can be calculated for every type of behavioral match (i.e., color in the CRP) separately. Given the introductory nature of this module, the four measures we covered in this module are a subset of CRQA measures. This subset of measures are chosen since they are among the most widely used CRQA measures by studies from various disciplines (Fusaroli et al., 2014). They are especially relevant for the analysis of nominal data streams of dyadic interaction (as argued in Cox et al., 2016), which are often collected in developmental studies. For additional measures and software to calculate them, please see (Webber and Zbilut, 2005; Marwan et al., 2007; Coco and Dale, 2014; Hasselman, 2018).
Sample Data and Scripts
The CRQA module contains a readme.md file, an example dataset, and six MATLAB scripts, including a demo function demo_CRQA.m. These materials will enable users with little to no programming experience to plot the data and perform simple Chromatic and Anisotropic CRQA.
Data
The example dataset example_data.mat consists of two nominal time series, PP1 and PP2, of equal length (1,630 time steps), each containing integer values from 1 to 5. The time series come from a dyadic interaction study, in which the collaborative behaviors of two children were coded from video, at 1 Hz, by using the same five specific behavioral categories for each (for more details see Guevara et al., 2017). To use this script on their own data, users will need to have data formatted as timeseries, which they can do using the convertEvents2timeseries.m script in Module 1.
Scripts
The function demo_CRQA.m loads the example data and runs the entire set of functions of the module. The function tt.m in the folder lib is part of the crp toolbox available at http://www.recurrence-plot.tk, and computes the distributions of lengths of the vertical and horizontal line structures in the CRP. Based on these two distributions, the orientation-specific CRQA measures (LAM, TT, Max_L, and Ent_L) are calculated. The CRQA module can be performed directly on the example dataset, but with a few modifications of the scripts also on the user’s own nominal dataset.
The function PlotTS.m visualizes the two time series. This opens a figure window showing two plots, each of which displays the behavioral stream of one of the interaction partners (Figure 5). The function CatCRMatrix.m creates a cross-recurrence matrix rec of the two time series. Two types of behavioral matches are distinguished in this analysis: ‘distributed dyadic interaction’ (DDI) and ‘unequal dyadic interaction’ (UDI). In DDI both children were actively engaged with the task and contributed to the solution, whereas in UDI only one child was contributing to the solution while the other child was not (see Guevara et al., 2017 for more details). All other combinations of individual behaviors are considered to be non-matching, and were labeled ‘no dyadic interaction’ (NDI). Different values in the matrix rec correspond to different types of behavioral matches, +1 for DDI and −1 for UDI, whereas NDI receives the value 0. The function PlotCRP.m plots the Chromatic CRP, based in the matrix rec (see Figure 6). The function CRQA_out.m performs Chromatic and Anisotropic CRQA using the matrix rec. Chromatic CRQA calculates the recurrence rate (RR) for both types of behavioral matches. The function provides RR both as a proportion of the total number of points in the CRP (i.e., canonical recurrence rate), as well as a proportion of the total number of behavioral matches (i.e., relative recurrence rate). These values are written to the matrix Chromatic_CRQA in the Workspace (Table 1). Anisotropic CRQA quantifies both the vertical and horizontal patterns. As said, the quantitative analysis will ignore the different types of behavioral matches for now, treating them as equal. The orientation-specific CRQA measures are written to the matrix Anisotropic_CRQA in the Workspace (Table 2). The upper row in Anisotropic_CRQA gives the values for the vertical line structures, the lower row those for the horizontal line structures.
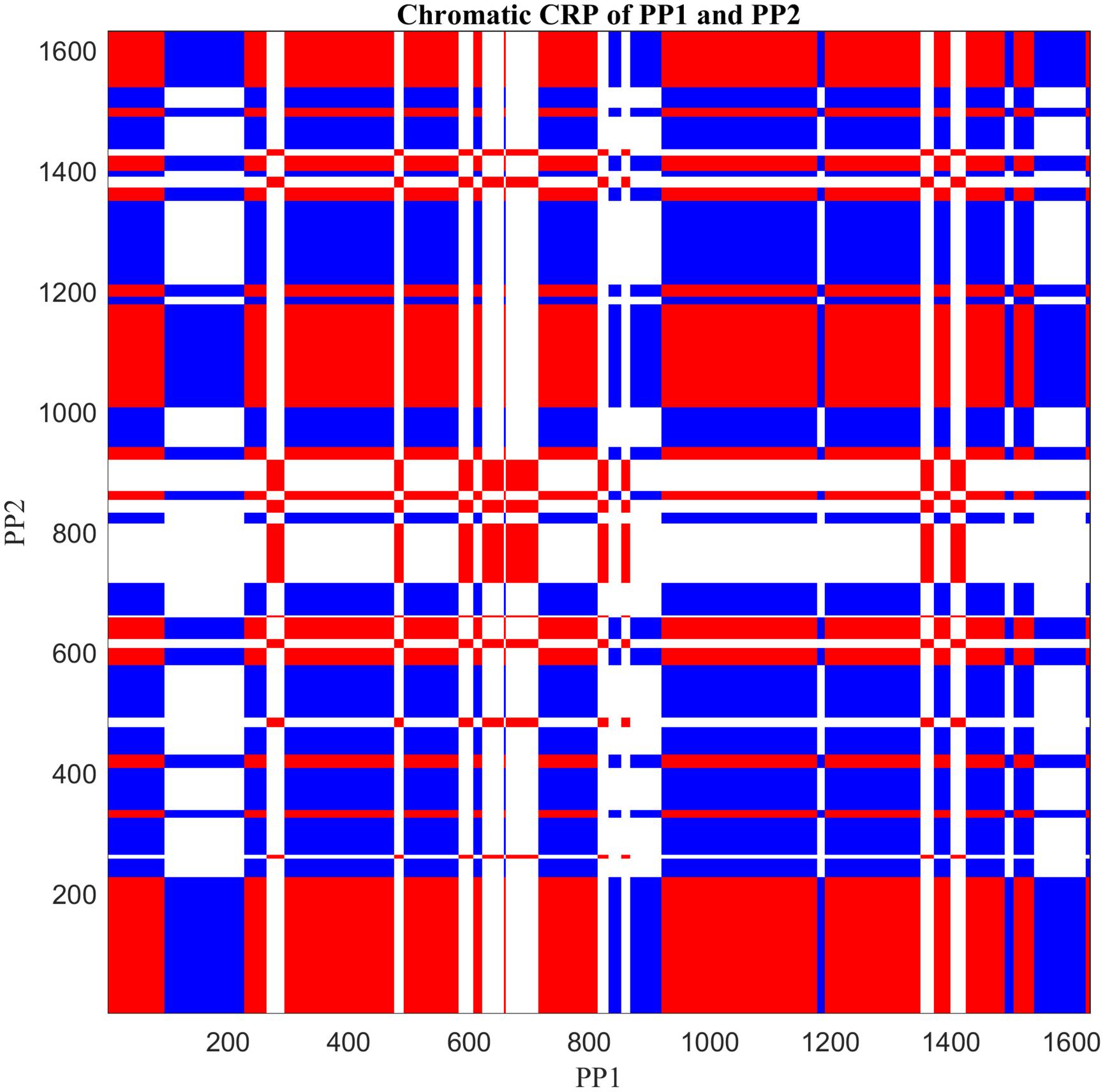
Figure 6. Cross-recurrence plot of the nominal time series shown in Figure 4, by applying Chromatic CRQA. The three colors represent three different types of collaborative states of the dyad. (For details see text).

Table 1. Canonical Recurrence Rate (RR) and relative Recurrence Rate (rRR) for both types of behavioral match after Chromatic CRQA.

Table 2. CRQA measures of the horizontal and vertical patterns after Anisotropic CRQA.
Results
Figure 6 displays a colored checkerboard pattern typical for Chromatic CRQA with nominal data. There are three colors in this CRP representing the three different types of states of the dyad, based on the numerical values in rec: red for DDI (value +1), blue for UDI (value −1), and white for NDI (value 0). All together the CRP nicely displays the rich coordinative structure of the collaborative interaction, across all possible timescales, in terms of the pre-defined behavioral matches. The values in Chromatic_CRQA show differences in the recurrence rate for DDI and UDI. Specifically, the recurrence rate for UDI is slightly higher than for DDI. This means that UDI is the dominant attractor state, implying that the unequal dyadic interactions were more prominent than the distributed dyadic interactions, in this particular interaction. The values in Anisotropic_CRQA (Table 2) quantify the patterns of the vertical and horizontal line structures displayed in the Figure. Notably, we see small differences between some of the CRQA measures for the horizontal and vertical patterns, reflecting a small anisotropy in the CRP. LAM is equal to 1 for both orientations, which means that all recurrences are part of a horizontal pattern as well as a vertical pattern (of at least length 2). In general terms this means that the collaborative behavior is quite patterned. TT is slightly higher in the vertical direction than in the horizontal direction. This is reversed for Max_L. This is also somewhat visible in Figure 5. Finally, there is no difference between Ent_L for both orientations. Overall, these results indicate an asymmetry in the dynamics of this interaction, suggesting slight differences in the behavioral dominance between the two collaborating children. These results are investigated further in Guevara et al. (2017).
Discussion
Although the asymmetry in the example data is relatively small, additional examples of the explanatory and predictive value of Chromatic and Anisotropic CRQA are available in the literature (e.g., De Jonge-Hoekstra et al., 2016; Guevara et al., 2017; López-Pérez et al., 2017; Nonaka and Goldfield, 2018; Menninga et al., 2019; Gampe et al., 2020). For reasons of simplicity the module materials do not allow users to assess the quantitative recurrence metrics for different types of behavioral matches (i.e., the different colors displayed in the CRP). Chromatic CRQA on nominal data can result in a large number of measures. That is, for each behavioral match included in the analysis there is an additional set of measures. This even becomes almost twice as large when quantifying the line structures for both orientations in the CRP, as is done in Anisotropic CRQA. However, the relative differences of the anisotropic CRQA measures can quantify relevant asymmetries in the dyadic dynamics and the differences in coupling strength between two interaction partners (see, e.g., Cox et al., 2016) and thus provides a valuable addition to toolbox of the high-density behavioral analyses.
Module 5: Discovering Directional Influence Among Multimodal Behavioral Variables With Granger Causality
In this section, we will introduce Granger Causality (GC), a method to quantify the directional influences among a set of interdependent behavioral variables. Wiener–Granger Causality is a statistical notion of causality based on computing the improved prediction from one time series to another (Granger, 1969; Bressler and Seth, 2011). Consider an infant–parent toy-play interaction as a concrete example. In this interaction, multiple behavioral cues from both the infant and the parent are influencing each other at the same time. GC could be used to examine the directional influence from one specific behavior to another in this multimodal interaction. For example, with GC we can compute whether a parent talking about a toy increases the likelihood of the child looking at that same toy in real time, above and beyond all the other behavioral variables observed in this social interaction.
Originally developed in the context of econometric theory, GC gained popularity within the field of neuroscience as a non-invasive technique for inferring relations in between different sources of neural activity (Roebroeck et al., 2005; Vakorin et al., 2007; Chang et al., 2008; David et al., 2008; Nedungadi et al., 2009). Recently, GC has also been used in behavioral research. For example, it has been used to examine the early development of vocal turn-taking between marmoset monkey infants and parents (Takahashi et al., 2016), to quantify leader and follower dynamics in joint music performance (Chang et al., 2017) and to examine the development of coordinated behaviors in infant–parent interaction (Xu et al., 2017). In the following subsections, we explain the conceptual foundation of this technique and then demonstrate how to calculate and interpret the results with an empirical example from an infant–parent interaction study.
Methods
Wiener (1956) provided the conceptual basis of Granger causality, namely, the idea that the variable X could be said to cause Y if the ability to predict Y can be improved by incorporating the information contained in X. Granger (1969) formalized this notion of causality in the domain of time series signals based on multivariate autoregressive (MVAR) models. The basic idea of MVAR is quite simple: the past can predict the future. For example, the behavior of a complex system H at time T + 1 can be modeled by its past observed behaviors or values from T − p to T. Granger causality can be described within this example as follows. Suppose that X and Y are two interdependent processes in this system H and we want to predict the future of Y. First, we predict Y’s value at time T+1, i.e., YT+1, using all the available information in the system H from time T − p to T, including its own past values (i.e., its history) and the history of X. Next, we calculate a second prediction for YT+1, this time using all the available information in the system H from time T − p to T, including its own history, but this time, excluding the past values of X. If YT+1 is better predicted in the model that includes the past values of X, this means that past values of X contain unique information that helps to predict Y above and beyond the information contained in the history of all the other variables, Y itself included. In this case, X is said to Granger-cause Y.
Currently, GC can be applied to time series with continuous values or binary spike trains (see Figure 3) introduced in Modules 1 and 2. Binary spike trains are used to indicate whether or not a given activity, such as a neuron firing or a child’s babbling is observed during a sampling period. The MVGC Matlab Toolbox developed by Barnett and Seth is widely used for computing GC among time series with continuous values. Barnett and Seth (2014) offers a comprehensive tutorial covering both the mathematical foundation of the GC’s computational process and the usage of the MVGC toolbox. For this reason, this module focuses on the computation of GC within discrete binary spike train data based on the framework and toolbox developed by Kim et al. (2011).
For discrete binary spike trains or point processes, the likelihood of an event occurring is modeled by a Generalized Linear Model (GLM): a linear combination of this temporal variable’s dependency to the history of each individual element in the ensemble. The GLM framework allows researchers to calculate the statistical significance of the GC relationship using the likelihood ratio test statistic. These goodness-of-fit statistics can be calculated by comparing the deviance between the estimated model with trigger variable X excluded and the estimated full model in the GLM framework. Additionally, a multiple hypothesis testing error measure, the false discovery rate (FDR) (Benjamini and Hochberg, 1995; Storey, 2002) can be used to assess the expected proportion of FDR when the number of hypothesis tests and thus the number of rejected null hypotheses is large.
Sample Data and Scripts
The fifth code module contains all the Matlab functions involved in the calculation of GC and its significance, two sample data files, a demo file, demo_granger_causality.m, which demonstrates all steps of GC calculation with the provided data, and a readme.md file, which provides detailed instructions on how to use the scripts.
Data
Our example dataset includes multimodal behavioral streams collected from an infant–parent toy-play experiment. Infant and parent dyads participated in a toy-play experiment when the infant was 9- and 12-months old. During each visit, the dyads were instructed to play with three single colored toys as they would if they were playing at home. Both participants wore head-mounted eye-trackers to record their eye movements (Franchak et al., 2011) and their first-person view of the play episode. An additional birds-eye camera captured their manual activities from above. The parent’s speech was also recorded. After the experiment, eye-tracking data, video recordings and speech recordings were synchronized and calibrated. Trained coders provided frame-by-frame annotations indicating all instances of parents and infants gaze and manual contact with each of the three objects (Slone et al., 2018). Three ROI were used for all the behavioral streams: the three toys. In addition, we transcribed the parent’s speech data, and identified all instances during which an object’s name was referenced and marked those naming events with ROI values as well. In summary, we collected five behavioral time series: infant gaze, infant manual activity, parent gaze, parent manual activity, and parent speech.
To convert our behavioral data streams into multivariate spike train data, all data streams were divided into three groups according to each object, i.e., the ROIs. Next, at every 333 ms interval we re-sampled the behavioral streams to see if each behavior was present during the interval. For example, if the infant looked to the red object during a given sample unit, this section was marked 1; if not, 0. After resampling, the behavioral streams were transformed into spike trains. Figure 7A shows a portion of visualized raw behavioral streams from our sample dataset. Data file gcause_sample_data1.mat contains the behavioral streams collected from the example dyad when the infant was 9 months; file gcause_sample_data2.mat contains the behavioral streams collected from the same dyad when the infant was 12 months. To use this script on their own data, users will need to have data formatted as binary spike trains, which they can do using the convertEvents2Binaryspikes.m script in Module 1.
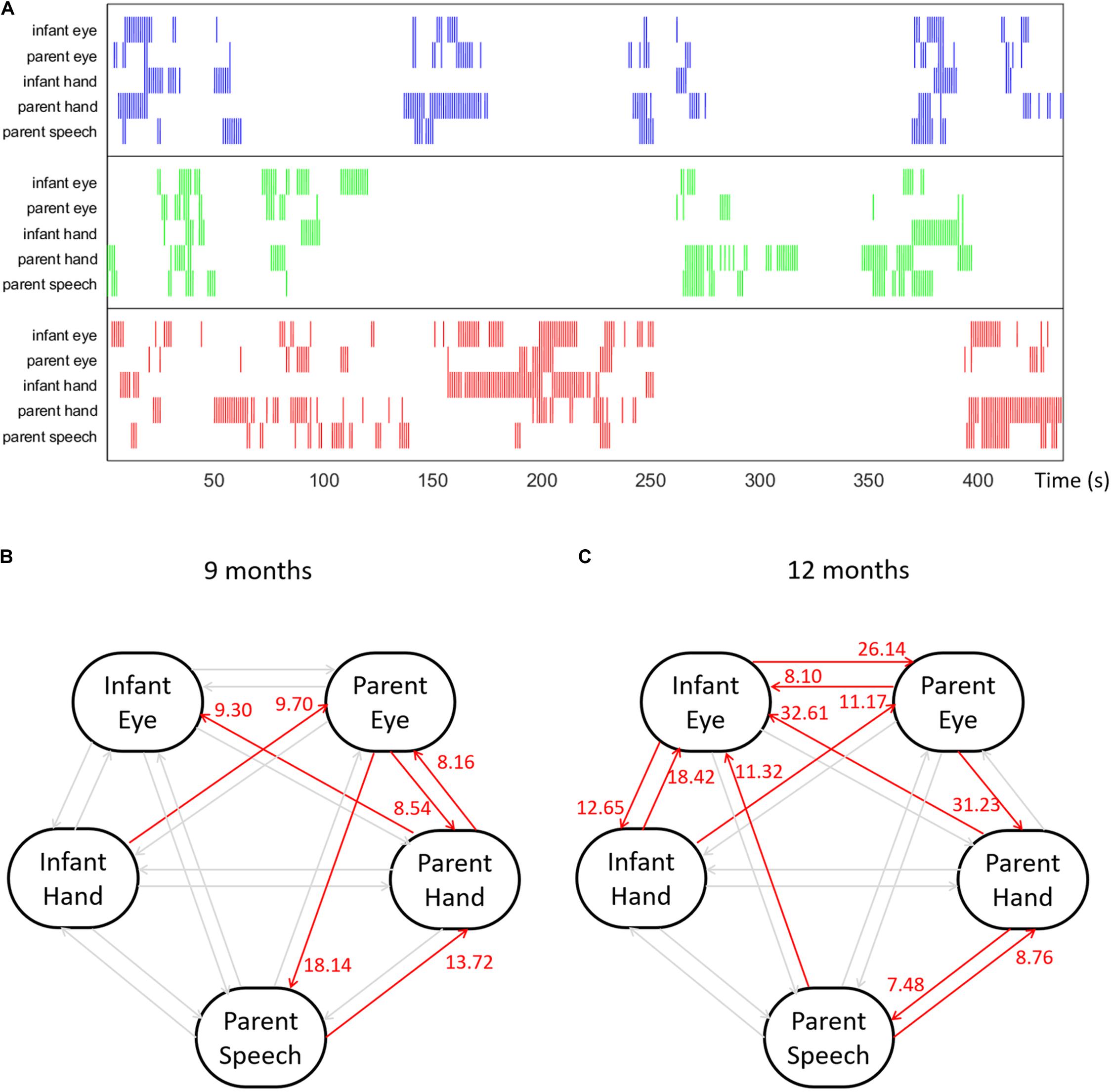
Figure 7. (A) An example multimodal temporal dataset collected from an infant–parent interaction study with five behavioral variables: infant gaze behavior, infant manual action, parent gaze behavior, parent manual action and parent speech events with object names. The colors indicate the target object of each behavior. (B,C) Granger causality results computed among five behavioral time series for an example dyad at 9 and 12 months.
Scripts
The demo script demo_granger_causality.m, loads one of the sample datasets, visualizes the behavioral time series in a plot (see Figure 7A for an example), performs GC computation and displays the results in an easily interpretable format. The key function for computing GC and conducting significance test is calculate_granger_causality() which is located in the lib/folder. This function takes two input parameters: data_matrix and glm_time_range. The first parameter, data_matrix, contains the time series data that will be used to perform GC computation. The second parameter, glm_time_range, is the length of the history window that will be used for prediction model fitting in GC computation.
In the calculation, the function calculate_granger_causality() will first generate a set of likelihood estimation models for each time series contained in data_matrix by iterating through history window durations from 1 to glm_time_range. The best estimation will be chosen from this set of candidate models using Akaike’s information criterion (AIC) (Akaike, 1974; Burnham and Anderson, 1998). Next, the function will calculate GC from between every pair of variables. For example, in order to calculate the extent to which the infant looking at the red object uniquely improves the occurrence of the parent also looking at the red object, the function constructs two models: (1) the full model: the likelihood of parent’s looking behavior is modeled based on the recent history of all five variables in our system; (2) the partial model: the function excludes infant’s looking variable from the model and calculates an estimate of the parent’s looking behavior based on the other four variables alone.
The results are returned in the output results_gcause_mat. The magnitude indicates the strength of the GC influence: higher value means stronger influence. The second return value results_gcause_fdr contains the significance test result for every directional GC influence. The significance test can result in three outputs: 1, −1, or 0. An output of 1 means that there is a significantly positive GC directional influence between the indicated pair of variables; −1 means that there is a significant negative GC influence; and a 0 value means the influence is not significant. Lastly, the function prettyprint_gcause_result() will print out the quantified directional links among each pair of variables in an easily readable format in the console.
Results
Figures 7B,C shows the Granger Causality results among five behavioral variables for one example dyad at 9 and 12 months. With five behavioral time series, we computed twenty different types of directional links between each pair of variables. Figure 7B shows a visualized graph illustrating the computed Granger causality links among five behavioral variables of the example dyad when the infant was 9-months old; Figure 7C shows the computed result of the same dyad at 12 months. In the Figure, red links indicate the significantly positive links with number near the arrow of each link representing the G-cause value. In this example, at both ages, this dyad shows a significantly positive link from the parent’s manual action to infant’s looking behavior. This means that the occurrence of parent’s holding a certain object significantly increases the likelihood of the infant looking at the same object, i.e., parent’s manual actions Granger caused infant’s looking behavior in infant–parent interactions when the infant was 9 and 12 months. Note that the influence from parent to child increases across this developmental period. We can also see that influences between infant modalities also increase between 9 and 12 months. Thus, using GC techniques, we observed developmental changes in the directional influences between parent and child multimodal (gaze hand and parent speech) activity.
Discussion
The fact that Granger Causality accommodates stochastic processes and makes only general assumptions about the collected data means it is particularly well-suited for behavioral scientists who collect multiple dimensions of behavior each mutually influencing one another. However, we note a number of limitations of this technique. First, it currently lacks the flexibility for behavioral data collected from trials with different lengths. Second, the trigger variable must occur before the effect variable in the behavioral data coding in order to be featured as a predictor in the GC computational process. Methods of data recording or coding that lack precise temporal accuracy may thus obscure “granger-causes.’ Finally, while behaviors and their mutual influences can be non-linear, the current modeling process is based on a linear assumption: all causal influences remain constant in direction throughout time (Granger, 1988; Sugihara et al., 2012; Maziarz, 2015). Addressing these limitations would enhance the application of GC to complex behavioral data.
Overall Discussion
From Lashley (1951) to Elman (1990) and Kolodny and Edelman (2015), understanding the temporal structure of human behavior has been recognized as one of the most fundamental problems in psychology. Recently, advances in technology have allowed us to collect large datasets of high-density behavioral streams in naturalistic scenarios (de Barbaro, 2019). This has enabled researchers to capture the temporal dynamics of behavior at a fine temporal scale. Additionally, it has created novel analytical challenges for modern psychologists. To tackle these challenges, we provide introductions and scripts for a range of complementary analysis techniques. For the novice programmer, we provide a guide to the basic functions required for time series analysis (Module 1). Data visualization techniques introduced in Module 2 allow users to create flexible and customizable plots of raw and processed behavioral data streams to provide insight into structure and variability of behavior within and between participants. In the third module, we introduce Burstiness calculations to describe the overall distributional structure and quantify the occurrence regularities of temporal events. In the fourth module, we explain Chromatic and Anisotropic Cross-Recurrence Quantification Analysis, which quantify non-linear dynamics across multiple timescales. These methods can track different types of recurrent behavioral patterns within dyadic interaction and can quantify asymmetries in the dominance between interaction partners. Finally, we introduce Granger causality techniques (Module 5) to quantify the directional relations among multiple interdependent behavioral variables within a system. Each module includes sample data collected by developmental psychologists, and scripts provided in Module 1 allow users to import and format their own data for use in subsequent modules. Experienced programmers can modify scripts as desired.
It would be impossible to provide a complete introduction to all techniques relevant to multimodal high-density data. Many other techniques capture temporal dependencies in sequential data, including but not limited to Markov-chain based graphical modeling (Pentland and Liu, 1999), fractal (Scafetta and Grigolini, 2002; Chen et al., 2010; Wijnants et al., 2012a) and multifractal analyses (Ihlen, 2012; Kelty-Stephen et al., 2013), dynamic field modeling (Thelen et al., 2001; Cox and Smitsman, 2019), and dynamic causal modeling (Stephen and Mirman, 2010). Such formal modeling approaches hold assumptions about the structure and mechanisms of activity. The approaches introduced here are mainly descriptive, making at most minimal assumptions about the structure of the input data and therefore naturally accommodating stochastic processes.
Technology and novel computational methods are changing the landscape of the field of psychology. Although considerable effort has been devoted to open science and data sharing (MacWhinney, 2014; Gilmore et al., 2016; Foster and Deardorff, 2017; Frank et al., 2017), researchers often neglect “method sharing.” As pointed out by Caiafa and Pestilli (2017), in this new data-intensive era, effectively every experiment is the convergence of three key dimensions: data, analytics, and computing. Platforms such as OpenNeuro (Gorgolewski et al., 2017) and brainlife (Hayashi et al., 2017; Avesani et al., 2019) have successfully achieved this vision of sharing data, analysis methods and computing resources in neuroscience. As psychologists begin to grapple with novel big-data techniques for studying behavior, similar platforms could unite researchers with different expertise to enhance scientific communication and discovery while reducing cost of conducting novel and interdisciplinary research. By sharing real data with detailed code for a variety of techniques for analyzing high-density multimodal activity, we take a first step toward the new behavioral science of tomorrow.
Data Availability Statement
Sample datasets used in this paper are provided at: https://github.com/findstructureintime/Time-Series-Analysis.
Ethics Statement
The studies involving human participants were reviewed and approved by Institutional Review Board (IRB) at Human Subjects Office Indiana University. Written informed consent to participate in this study was provided by the participants’ legal guardian/next of kin.
Author Contributions
TX, KB, DA, and RC contributed to conception of this article. TX and KB contributed equally to the main body of the manuscript as co-first authors. KB wrote the text and scripts of Modules 1 and 2. DA wrote the text and scripts of Module 3. RC wrote the text and scripts of Module 4. TX wrote the text and scripts of Module 5. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Institutes of Health grant T32HD007475 to TX and an NIMH K01 Award (1K01MH111957-01A1) to KB.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank Linda B. Smith, Chen Yu, and Michael H. Goldstein for their insights and comments on the topic of behavioral analysis in developmental science.
References
Abney, D. H., Dale, R., Louwerse, M. M., and Kello, C. T. (2018). The bursts and lulls of multimodal interaction: temporal distributions of behavior reveal differences between verbal and non-verbal communication. Cogn. Sci. 42, 1297–1316. doi: 10.1111/cogs.12612
Abney, D. H., Paxton, A., Dale, R., and Kello, C. T. (2014). Complexity matching in dyadic conversation. J. Exp. Psychol. Gen. 143, 2304–2315. doi: 10.1037/xge0000021
Adolph, K. E., and Berger, S. E. (2006). “Motor development,” in Handbook of Child Psychology: Cognition, Perception, and Language, Vol. 2, eds L. S. Liben, U. Mueller, and R. M. Lerner (New York, NY: John Wiley & Sons), 161–213. doi: 10.1002/9780470147658.chpsy0204
Adolph, K. E., Cole, W. G., Komati, M., Garciaguirre, J. S., Badaly, D., Lingeman, J. M., et al. (2012). How do you learn to walk? Thousands of steps and dozens of falls per day. Psychol. Sci. 23, 1387–1394. doi: 10.1177/0956797612446346
Adolph, K. E., Hoch, J. E., and Cole, W. G. (2018). Development (of walking): 15 suggestions. Trends Cogn. Sci. 22, 1–13.
Adolph, K. E., and Tamis-Lemonda, C. S. (2014). The costs and benefits of development: the transition from crawling to walking. Child Dev. Perspect. 8, 187–192. doi: 10.1111/cdep.12085
Akaike, H. (1974). “A new look at the statistical model identification,” in IEEE Transactions on Automatic Control (New Jersey, NJ: IEEE), 19, 716–723. doi: 10.1109/TAC.1974.1100705
Aslin, R. N. (2012). Infant eyes: a window on cognitive development. Infancy 17, 126–140. doi: 10.1111/j.1532-7078.2011.00097.x
Avesani, P., Caiafa, C., McPherson, B., Saykin, A., Hayashi, S., Herschel, R. A., et al. (2019). The open diffusion data derivatives, brain data upcycling via integrated publishing of derivatives and reproducible open cloud services. Sci. Data 6:69. doi: 10.1038/s41597-019-0073-y
Bakeman, R., and Quera, V. (2011). Sequential Analysis and Observational Methods for The Behavioral Sciences. Sequential Analysis and Observational Methods for the Behavioral Sciences. Cambridge: Cambridge University Press. doi: 10.1017/CBO9781139017343
Ballard, D. H., Hayhoe, M. M., Pook, P. K., and Rao, R. P. (1997). Deictic codes for the embodiment of cognition. Behav. Brain Sci. 20, 723–742; discussion 743–767. doi: 10.1017/S0140525X97001611
Barnett, L., and Seth, A. K. (2014). The MVGC multivariate granger causality toolbox: a new approach to granger-causal inference. J. Neurosci. Methods 223, 50–68. doi: 10.1016/j.jneumeth.2013.10.018
Benjamini, Y., and Hochberg, Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. B 57, 289–300. doi: 10.2307/2346101
Blair, B. L., Perry, N. B., O’Brien, M., Calkins, S. D., Keane, S. P., and Shanahan, L. (2015). Identifying developmental cascades among differentiated dimensions of social competence and emotion regulation. Dev. Psychol. 51, 1062–1073. doi: 10.1037/a0039472.Identifying
Bressler, S. L., and Seth, A. K. (2011). Wiener-granger causality: a well established methodology. NeuroImage 58, 323–329. doi: 10.1016/j.neuroimage.2010.02.059
Burnham, K. P., and Anderson, D. R. (1998). “Practical use of the information-theoretic approach,” in Model Selection and Inference (New York, NY: Springer), 75–117.
Caiafa, C. F., and Pestilli, F. (2017). Multidimensional encoding of brain connectomes. Sci. Rep. 7, 1–13. doi: 10.1038/s41598-017-09250-w
Card, S., Mackinlay, J., and Shneiderman, B. (1999). Readings in Information Visualization: Using Vision to Think. Burlington, MA: Morgan Kaufmann, 712. doi: 10.1002/wics.89
Carello, C., and Moreno, M. A. (2005). “Why nonlinear methods?,” in Tutorials in Contemporary Nonlinear Methods for The Behavioral Sciences, eds M. A. Riley and G. C. Van Orden (Arlington, VA: National Science Foundation), 1–25.
Chang, A., Livingstone, S. R., Bosnyak, D. J., and Trainor, L. J. (2017). Body sway reflects leadership in joint music performance. Proc. Natl. Acad. Sci. U.S.A. 114, E4134–E4141. doi: 10.1073/pnas.1617657114
Chang, C., Thomason, M. E., and Glover, G. H. (2008). Mapping and correction of vascular hemodynamic latency in the BOLD signal. NeuroImage 43, 90–102. doi: 10.1016/j.neuroimage.2008.06.030
Chen, Y., Jiang, J., Peng, W., and Lee, S. (2010). “An efficient algorithm for mining time interval-based patterns in large database,” in Proceedings of The 19th ACM International Conference on Information and Knowledge CIKM 2010, Toronto, ON, 49–58. doi: 10.1145/1871437.1871448
Coco, M. I., and Dale, R. (2014). Cross-recurrence quantification analysis of categorical and continuous time series: an R package. Front. Psychol. 5:510. doi: 10.3389/fpsyg.2014.00510
Cox, R. F. A., and Smitsman, A. W. (2019). Action-selection perseveration in young children: advances of a dynamic model. Dev. Psychobiol. 61, 43–55. doi: 10.1002/dev.21776
Cox, R. F. A., van der Steen, S., Guevara, M., de Jonge-Hoekstra, L., and van Dijk, M. (2016). “Chromatic and anisotropic cross-recurrence quantification analysis of interpersonal behavior,” in Proceedings of The 6th International Symposium on Recurrence Plots: Recurrence Plots and Their Quantifications: Expanding Horizons, eds N. M. C. Webber and C. Ioana (Grenoble: Springer), 17–19. doi: 10.1007/978-3-319-29922-8_11
Cox, R. F. A., and van Dijk, M. (2013). Microdevelopment in parent-child conversations: from global changes to flexibility. Ecol. Psychol. 25, 304–315. doi: 10.1080/10407413.2013.810095
Dale, R., and Kello, C. T. (2018). “How do humans make sense?” multiscale dynamics and emergent meaning. New Ideas Psychol. 50, 61–72. doi: 10.1016/j.newideapsych.2017.09.002
Darst, R. K., Granell, C., Arenas, A., Gómez, S., Saramäki, J., and Fortunato, S. (2016). Detection of timescales in evolving complex systems. Sci. Rep. 6:39713. doi: 10.1038/srep39713
David, O., Guillemain, I., Saillet, S., Reyt, S., Deransart, C., Segebarth, C., et al. (2008). Identifying neural drivers with functional MRI: an electrophysiological validation. PLoS Biol. 6:e315. doi: 10.1371/journal.pbio.0060315
de Barbaro, K. (2019). Automated sensing of daily activity: a new lens into development. Dev. Psychobiol. 61, 444–464. doi: 10.1002/dev.21831
de Barbaro, K., Chiba, A., and Deák, G. O. (2011). Micro-analysis of infant looking in a naturalistic social setting: Insights from biologically based models of attention. Dev. Sci. 14, 1150–1160. doi: 10.1111/j.1467-7687.2011.01066.x
de Barbaro, K., Clackson, K., and Wass, S. (2016a). Stress reactivity speeds basic encoding processes in infants. Dev. Psychobiol. 58, 546–555. doi: 10.1002/dev.21399
de Barbaro, K., Clackson, K., and Wass, S. V. (2017). Infant attention is dynamically modulated with changing arousal levels. Child Dev. 88, 629–639. doi: 10.1111/cdev.12689
de Barbaro, K., Johnson, C. M., Forster, D., and Deák, G. O. (2013). Methodological considerations for investigating the microdynamics of social interaction development. IEEE Trans. Auton. Ment. Dev. 5, 258–270. doi: 10.1109/tamd.2013.2276611
de Barbaro, K., Johnson, C. M., Forster, D., and Deák, G. O. (2016b). Sensorimotor decoupling contributes to triadic attention: a longitudinal investigation of mother-infant-object interactions. Child Dev. 87, 494–512. doi: 10.1111/cdev.12464
de Barbaro, K., Khante, P., Maier, M., and Goodman, S. (n.d.). Mama Tried: Contingent Responding to Distress Does Not Increase Rates of Real-Time Soothing in Infants High in Negative Emotionality.
de Barbaro, K., Khante, P., Maier, M., and Goodman, S. (2020). “Mama tried: contingent responding to distress does not increase rates of real-time soothing in infants high in negative emotionality,” in Paper Presentation Accepted at Society for Ambulatory Assessment, Glasgow.
De Jonge-Hoekstra, L., Van der Steen, S., Van Geert, P., and Cox, R. F. A. (2016). Asymmetric dynamic attunement of speech and gestures in the construction of children’s understanding. Front. Psychol. 7:473. doi: 10.3389/fpsyg.2016.00473
Den Hartigh, R. J. R., Van Geert, P. L. C., Van Yperen, N. W., Cox, R. F. A., and Gernigon, C. (2016). Psychological momentum during and across sports matches: evidence for interconnected time scales. J. Sport Exerc. Psychol. 38, 82–92. doi: 10.1123/jsep.2015-0162
Elman, J. (1990). Finding structure in time. Cogn. Sci. 14, 179–211. doi: 10.1207/s15516709cog1402_1
Fausey, C. M., Jayaraman, S., and Smith, L. B. (2016). From faces to hands: changing visual input in the first two years. Cognition 152, 101–107. doi: 10.1016/j.cognition.2016.03.005
Flack, Z. M., Field, A. P., and Horst, J. S. (2018). The effects of shared storybook reading on word learning: a meta-analysis. Dev. Psychol. 54, 1334–1346. doi: 10.1037/dev0000512
Foster, E. D., and Deardorff, A. (2017). Open science framework (OSF). J. Med. Libr. Assoc. 105, 203–206. doi: 10.5195/jmla.2017.88
Franchak, J. M., and Adolph, K. E. (2014). Affordances as probabilistic functions: implications for development, perception, and decisions for action. Ecol. Psychol. 26, 109–124. doi: 10.1038/nrm2621
Franchak, J. M., Kretch, K. S., Soska, K. C., and Adolph, K. E. (2011). Head-mounted eye-tracking: a new method to describe infant looking. Child Dev. 82, 1738–1750. doi: 10.1111/j.1467-8624.2011.01670.x
Frank, M. C., Braginsky, M., Yurovsky, D., and Marchman, V. A. (2017). Wordbank: an open repository for developmental vocabulary data. J. Child Lang. 44, 677–694. doi: 10.1017/S0305000916000209
Fusaroli, R., Konvalinka, I., and Wallot, S. (2014). “Analyzing social interactions: the promises and challenges of using cross recurrence quantification analysis,” in Translational Recurrences: Proceedings in Mathematics & Statistics, Vol. 103, eds N. Marwan, M. Riley, A. Giuliani, and C. Webber Jr. (Cham: Springer), 137–155. doi: 10.1007/978-3-319-09531-8
Fusaroli, R., Perlman, M., Mislove, A., Paxton, A., Matlock, T., and Dale, R. (2015). Timescales of massive human entrainment. PLoS One 10:e0122742. doi: 10.1371/journal.pone.0122742
Fusaroli, R., and Tylén, K. (2016). Investigating conversational dynamics: interactive alignment, interpersonal synergy, and collective task performance. Cogn. Sci. 40, 145–171. doi: 10.1111/cogs.12251
Gampe, A., Hartmann, L., and Daum, M. (2020). Dynamic interaction patterns of monolingual and bilingual infants with their parents. J. Child Lang. 47, 45–63. doi: 10.1017/S0305000919000631
Garrod, S., and Pickering, M. J. (2009). Joint action, interactive alignment, and dialog. Top. Cogn. Sci. 1, 292–304. doi: 10.1111/j.1756-8765.2009.01020.x
Gilmore, R. O., Adolph, K. E., and Millman, D. S. (2016). “Curating identifiable data for sharing: the databrary project,” in Proceedings of the New York Scientific Data Summit, NYSDS 2016, New York, NY, 1–6. doi: 10.1109/NYSDS.2016.7747817
Gnisci, A., Bakeman, R., and Quera, V. (2008). Blending qualitative and quantitative analyses in observing interaction: misunderstandings, applications and proposals. Int. J. Mult. Res. Approaches 2, 15–30. doi: 10.5172/mra.455.2.1.15
Goh, K. I., and Barabási, A. L. (2008). Burstiness and memory in complex systems. EPL 81:48002. doi: 10.1209/0295-5075/81/48002
Goodman, S. H., Bakeman, R., McCallum, M., Rouse, M. H., and Thompson, S. F. (2017). Extending models of sensitive parenting of infants to women at risk for perinatal depression. Parenting 17, 30–50. doi: 10.1080/15295192.2017.1262181
Gorgolewski, K., Esteban, O., Schaefer, G., Wandell, B., and Poldrack, R. (2017). “OpenNeuro—a free online platform for sharing and analysis of neuroimaging data,” in Proceedings of the 23rd Annual Meeting of Organization for Human Brain Mapping, Vancouver, BC.
Granger, C. W. J. (1969). Investigating causal relations by econometric models and cross-spectral methods. Econometrica 37, 424–438. doi: 10.2307/1912791
Granger, C. W. J. (1988). Causality, cointegration, and control. J. Econ. Dyn. Control 12, 551–559. doi: 10.1016/0165-1889(88)90055-3
Granic, I., and Hollenstein, T. (2016). “A survey of dynamic systems methods for developmental psychopathology,” in Developmental Psychopathology, ed. D. Cicchetti (Hoboken, NJ: John Wiley & Sons Inc), 1–43. doi: 10.1002/9780470939383.ch22
Granic, I., and Patterson, G. R. (2006). Toward a comprehensive model of antisocial development: a dynamic systems approach. Psychol. Rev. 113, 101–131. doi: 10.1037/0033-295X.113.1.101
Guevara, M., Cox, R. F. A., van Dijk, M., and van Geert, P. (2017). Attractor dynamics of dyadic interaction: a recurrence based analysis. Nonlinear Dynamics Psychol. Life Sci. 21, 289–317.
Hasselman, F. (2018). casnet: A Toolbox for Studying Complex Adaptive Systems and NETworks. R Package Version 0.1.3. Available online at: https://fredhasselman.com/casnet (accessed May 20, 2020).
Hayashi, S., Avesani, P., and Pestilli, F. (2017). Open Diffusion Data Derivatives. brainlife.io. doi: 10.25663/BL.P.3
Hayhoe, M. M., and Ballard, D. H. (2005). Eye movements in natural behavior. Trends Cogn. Sci. 9, 188–194. doi: 10.1016/j.tics.2005.02.009
Ihlen, E. A. F. (2012). Introduction to multifractal detrended fluctuation analysis in Matlab. Front. Physiol. 3:141. doi: 10.3389/fphys.2012.00141
Jayaraman, S., Fausey, C. M., and Smith, L. B. (2015). The faces in infant-perspective scenes change over the first year of life. PLoS One. 10:e0123780. doi: 10.1371/journal.pone.0123780
Jayaraman, S., Fausey, C. M., and Smith, L. B. (2017). Why are faces denser in the visual experiences of younger than older infants? Dev. Psychol. 53, 38–49. doi: 10.1037/dev0000230
Jayaraman, S., and Smith, L. B. (2019). Faces in early visual environments are persistent not just frequent. Vision Res. 157, 213–221. doi: 10.1016/j.visres.2018.05.005
Kelty-Stephen, D. G., Palatinus, K., Saltzman, E., and Dixon, J. A. (2013). A tutorial on multifractality, cascades, and interactivity for empirical time series in ecological science. Ecol. Psychol. 25, 1–62. doi: 10.1080/10407413.2013.753804
Kendon, A. (1970). Movement coordination in social interaction: some examples described. Acta Psychol. 32, 101–125. doi: 10.1016/0001-6918(70)90094-6
Kim, E. K., and Jo, H. H. (2016). Measuring burstiness for finite event sequences. Phys. Rev. E 94:032311. doi: 10.1103/PhysRevE.94.032311
Kim, J. C., and Clements, M. A. (2015). “Formant-based feature extraction for emotion classification from speech,” in Proceedings of the 38th International Conference on Telecommunications and Signal Processing, TSP 2015, (Prague: IEEE), 477–481. doi: 10.1109/TSP.2015.7296308
Kim, S., Putrino, D., Ghosh, S., and Brown, E. N. (2011). A granger causality measure for point process models of ensemble neural spiking activity. PLoS Comput. Biol. 7:e1001110. doi: 10.1371/journal.pcbi.1001110
Knapp, M. L., Hall, J. A., and Horgan, T. G. (2013). Nonverbal Communication in Human Interaction. Boston, MA: Cengage.
Kolodny, O., and Edelman, S. (2015). The problem of multimodal concurrent serial order in behavior. Neurosci. Biobehav. Rev. 56, 252–265. doi: 10.1016/j.neubiorev.2015.07.009
Landa, R. J., Gross, A. L., Stuart, E. A., and Faherty, A. (2013). Developmental trajectories in children with and without autism spectrum disorders: the first 3 years. Child Dev. 84, 429–442. doi: 10.1111/j.1467-8624.2012.01870.x
Lashley, K. S. (1951). “The problem of serial order in behavior,” in Cerebral Mechanisms in Behavior, ed. A. Jeffress. New York, NY: Wiley, 112–146.
López-Pérez, D., Leonardi, G., Niedzwiecka, A., Radkowska, A., Raczaszek-Leonardi, J., and Tomalski, P. (2017). Combining recurrence analysis and automatic movement extraction from video recordings to study behavioral coupling in face-to-face parent-child interactions. Front. Psychol. 8:2228. doi: 10.3389/fpsyg.2017.02228
Louwerse, M. M., Dale, R., Bard, E. G., and Jeuniaux, P. (2012). Behavior matching in multimodal communication is synchronized. Cogn. Sci. 36, 1404–1426. doi: 10.1111/j.1551-6709.2012.01269.x
Lusby, C. M., Goodman, S. H., Bell, M. A., and Newport, D. J. (2014). Electroencephalogram patterns in infants of depressed mothers. Dev. Psychobiol. 56, 459–473. doi: 10.1002/dev.21112
MacWhinney, B. (2014). The CHILDES Project: Tools for Analyzing Talk, Volume II: The database. London: Psychology Press.
Mangold (2017). INTERACT User Guide. Arnstorf, Germany: Mangold International GmbH. Arnstorf: Mangold.
Marwan, N., Carmen Romano, M., Thiel, M., and Kurths, J. (2007). Recurrence plots for the analysis of complex systems. Phys. Rep. 438, 237–329. doi: 10.1016/j.physrep.2006.11.001
Masten, A. S., and Cicchetti, D. (2010). Developmental cascades. Dev. Psychopathol. 22, 491–495. doi: 10.1017/S0954579410000222
Matthis, J. S., Yates, J. L., and Hayhoe, M. M. (2018). Gaze and the control of foot placement when walking in natural terrain. Curr. Biol. 28, 1224–1233.e5. doi: 10.1016/j.cub.2018.03.008
Menninga, A., Van Dijk, M., Cox, R. F. A., Steenbeek, H., and Van Geert, P. (2019). Co-adaptation processes of syntactic complexity in real-time kindergarten teacher-student interactions. Nonlinear Dynamics Psychol. Life Sci. 23, 229–260.
Messinger, D. S., Mattson, W. I., Mahoor, M. H., and Cohn, J. F. (2012). The eyes have it: making positive expressions more positive and negative expressions more negative. Emotion 12, 430–436. doi: 10.1037/a0026498
Nedungadi, A. G., Rangarajan, G., Jain, N., and Ding, M. (2009). Analyzing multiple spike trains with nonparametric granger causality. J. Comput. Neurosci. 27, 55–64. doi: 10.1007/s10827-008-0126-2
Noldus, L. P. J. J. (1991). The observer: a software system for collection and analysis of observational data. Behav. Res. Methods Instrum. Comput. 23, 415–429. doi: 10.3758/bf03203406
Nonaka, T., and Goldfield, E. C. (2018). Mother-infant interaction in the emergence of a tool-using skill at mealtime: a process of affordance selection. Ecol. Psychol. 30, 278–298. doi: 10.1080/10407413.2018.1438199
Pentland, A., and Liu, A. (1999). Modeling and prediction of human behavior. Neural Comput. 11, 229–242. doi: 10.1162/089976699300016890
Roebroeck, A., Formisano, E., and Goebel, R. (2005). Mapping directed influence over the brain using Granger causality and fMRI. NeuroImage 25, 230–242. doi: 10.1016/j.neuroimage.2004.11.017
Rossmanith, N., Costall, A., Reichelt, A. F., López, B., and Reddy, V. (2014). Jointly structuring triadic spaces of meaning and action: book sharing from 3 months on. Front. Psychol. 5:1390. doi: 10.3389/fpsyg.2014.01390
Scafetta, N., and Grigolini, P. (2002). Scaling detection in time series: diffusion entropy analysis. Phys. Rev. E Stat. Nonlin. Soft. Matter. Phys. 66:036130. doi: 10.1103/PhysRevE.66.036130
Sénéchal, M., Cornell, E. H., and Broda, L. S. (1995). Age-related differences in the organization of parent-infant interactions during picture-book reading. Early Childh. Res. Q. 10, 317–337. doi: 10.1016/0885-2006(95)90010-1
Shneiderman, B. (2002). Inventing discovery tools: combining information visualization with data mining. Inform. Vis. 1, 5–12. doi: 10.1057/palgrave/ivs/9500006
Shockley, K., Butwill, M., Zbilut, J. P., and Webber, C. L. Jr. (2002). Cross recurrence quantification of coupled oscillators. Phys. Lett. Sec. A Gen. Atom. Solid State Phys. 305, 59–69. doi: 10.1016/S0375-9601(02)01411-1
Slone, L. K., Abney, D. H., Borjon, J. I., Chen, C. H., Franchak, J. M., Pearcy, D., et al. (2018). Gaze in action: head-mounted eye tracking of children’s dynamic visual attention during naturalistic behavior. J. Vis. Exp. 2018, 1–9. doi: 10.3791/58496
Smith, L. B., and Gasser, M. (2005). The development of embodied cognition: six lessons from babies. Artif. Life 11, 13–29. doi: 10.1162/1064546053278973
Smith, L. B., Yu, C., Yoshida, H., and Fausey, C. M. (2015). Contributions of head-mounted cameras to studying the visual environments of infants and young children. J. Cogn. Dev. 16, 407–419. doi: 10.1080/15248372.2014.933430
Spivey, M. J., and Dale, R. (2006). Continuous dynamics in real-time cognition. Curr. Dir. Psychol. Sci. 15, 207–211. doi: 10.1111/j.1467-8721.2006.00437.x
Stephen, D. G., and Mirman, D. (2010). Interactions dominate the dynamics of visual cognition. Cognition 115, 154–165. doi: 10.1016/j.cognition.2009.12.010
Storey, J. D. (2002). A direct approach to false discovery rates. J. R. Stat. Soc. Ser. B Methodol. 64, 479–498. doi: 10.1111/1467-9868.00346
Sugihara, G., May, R., Ye, H., Hsieh, C., Deyle, E., Fogarty, M., et al. (2012). Detecting causality in complex ecosystems. Science 338, 496–500. doi: 10.1126/science.1227079
Takahashi, D. Y., Fenley, A. R., and Ghazanfar, A. A. (2016). Early development of turn-taking with parents shapes vocal acoustics in infant marmoset monkeys. Philos. Trans. R. Soc. B Biol. Sci. 371:20150370. doi: 10.1098/rstb.2015.0370
Tamis-LeMonda, C. S., Kuchirko, Y., Luo, R., Escobar, K., and Bornstein, M. H. (2017). Power in methods: language to infants in structured and naturalistic contexts. Dev. Sci. 20, 1–14. doi: 10.1111/desc.12456
Thelen, E. (2000). Grounded in the world: developmental origins of the embodied mind. Infancy 1, 3–28. doi: 10.1207/S15327078IN0101_02
Thelen, E., Schöner, G., Scheier, C., and Smith, L. B. (2001). The dynamics of embodiment: a field theory of infant perseverative reaching. Behav. Brain Sci. 24, 1–86.
Tufte, E. R. (2001). The Visual Display of Quantitative Information, Vol. 2. Cheshire; CT: Graphics press.
Vakorin, V. A., Krakovska, O. O., Borowsky, R., and Sarty, G. E. (2007). Inferring neural activity from BOLD signals through nonlinear optimization. NeuroImage 38, 248–260. doi: 10.1016/j.neuroimage.2007.06.033
van Dijk, M., van Voorthuizen, B., and Cox, R. F. A. (2018). Synchronization of mother-infant feeding behavior. Infant Behav. Dev. 52, 97–103. doi: 10.1016/j.infbeh.2018.06.001
Vinciarelli, A., Pantic, M., and Bourlard, H. (2009). Social signal processing: survey of an emerging domain. Image Vis. Comput. 27, 1743–1759. doi: 10.1016/j.imavis.2008.11.007
Wass, S. V., Whitehorn, M., Marriott Haresign, I., Phillips, E., and Leong, V. (2019). Interpersonal neural entrainment during early social interaction. Trends Cogn. Sci. 24, 329–342. doi: 10.1016/j.tics.2020.01.006
Webber, C. L. Jr., and Zbilut, J. P. (2005). “Recurrence quantification analysis of nonlinear dynamical systems,” in Tutorials in Contemporary Nonlinear Methods for the Behavioral Sciences, eds M. A. Riley and G. Van Orden (Alexandria, VA: National Science Foundation), 26–94.
West, K. L., and Iverson, J. M. (2017). Language learning is hands-on: exploring links between infants’ object manipulation and verbal input. Cogn. Dev. 43, 190–200. doi: 10.1016/j.cogdev.2017.05.004
Wiener, N. (1956). “The theory of prediction,” in Modern Mathematics for Engineers, Vol. 1, ed. E. F. Beckenbach (New York, NY: McGraw-Hill), 165–190.
Wijnants, M. L., Cox, R. F. A., Hasselman, F., Bosman, A. M. T., and Van Orden, G. (2012a). A trade-off study revealing nested timescales of constraint. Front. Physiol. 3:116. doi: 10.3389/fphys.2012.00116
Wijnants, M. L., Hasselman, F., Cox, R. F. A., Bosman, A. M. T., and van Orden, G. (2012b). An interaction-dominant perspective on reading fluency and dyslexia. Ann. Dyslexia 62, 100–119. doi: 10.1007/s11881-012-0067-3
Wittenburg, P., Brugman, H., Russel, A., Klassmann, A., and Sloetjes, H. (2006). “ELAN: a professional framework for multimodality research,” in Proceedings of the 5th International Conference on Language Resources and Evaluation, LREC 2006, Genoa, 1556–1559.
Xu, T. L., Abney, D. H., and Yu, C. (2017). “Discovering multicausality in the development of coordinated behavior granger causality for point process data,” in Proceedings of the 39th Annual Meeting of the Cognitive Science Society, Austin, TX.
Xu, T. L., de Barbaro, K., Abney, D. H., and Cox, R. (2020). Code Modules for Finding Structure in Time: Visualizing and Analyzing Behavioral Time Series (Version v1.0.0). Genève: Zenodo.
Xu, T. L., and Yu, C. (2016). “Quantifying joint activities using cross-recurrence block representation,” in Proceedings of the 38th Annual Conference of the Cognitive Science Society, Austin, TX.
Yang, C. C., and Hsu, Y. L. (2010). A review of accelerometry-based wearable motion detectors for physical activity monitoring. Sensors 10, 7772–7788. doi: 10.3390/s100807772
Ye, Z., Li, Y., Fathi, A., Han, Y., Rozga, A., Abowd, G. D., et al. (2012). “Detecting eye contact using wearable eye-tracking glasses,” in Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, 699–704. doi: 10.1145/2370216.2370368
Keywords: time series analysis, data visualization, burstiness, cross recurrence quantification analysis, Granger causality, high-density behavior data
Citation: Xu TL, de Barbaro K, Abney DH and Cox RFA (2020) Finding Structure in Time: Visualizing and Analyzing Behavioral Time Series. Front. Psychol. 11:1457. doi: 10.3389/fpsyg.2020.01457
Received: 18 December 2019; Accepted: 02 June 2020;
Published: 24 July 2020.
Edited by:
Caspar Addyman, Goldsmiths, University of London, United KingdomReviewed by:
Samuel J. Cheyette, University of California, Berkeley, United StatesGiuseppe Leonardi, University of Economics and Human Sciences in Warsaw, Poland
Copyright © 2020 Xu, de Barbaro, Abney and Cox. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tian Linger Xu, txu@iu.edu; lingertxu@gmail.com
†These authors have contributed equally to this work