
Abstract
Due to huge advancements in natural language processing (NLP) and machine learning, chatbots are gaining significance in the field of customer service. For users, it may be hard to distinguish whether they are communicating with a human or a chatbot. This brings ethical issues, as users have the right to know who or what they are interacting with (European Commission in Regulatory framework proposal on artificial intelligence. https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai, 2022). One of the solutions is to include a disclosure at the start of the interaction (e.g., “this is a chatbot”). However, companies are reluctant to use disclosures, as consumers may perceive artificial agents as less knowledgeable and empathetic than their human counterparts (Luo et al. in Market Sci 38(6):937–947, 2019). The current mixed methods study, combining qualitative interviews (n = 8) and a quantitative experiment (n = 194), delves into users’ responses to a disclosed vs. undisclosed customer service chatbot, focusing on source orientation, anthropomorphism, and social presence. The qualitative interviews reveal that it is the willingness to help the customer and the friendly tone of voice that matters to the users, regardless of the artificial status of the customer care representative. The experiment did not show significant effects of the disclosure (vs. non-disclosure). Implications for research, legislators and businesses are discussed.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Due to huge advancements in natural language processing (NLP) and machine learning, chatbots have become increasingly present on social media and messaging apps (Araujo 2018) and are especially gaining significance in the field of customer service (Ameen et al. 2021; Shumanov and Johnson 2021; Youn and Jin 2021). Chatbots are text-based user interfaces that build on NLP to mimic interactions with real people (Luo et al. 2019; Mozafari et al. 2020). The aim is typically to make users feel that they are communicating with a living person (Zemčík 2021). Their indisputable strength lies in the ability to process a large volume of customers’ inquiries through automation, provision of timely responses, availability, and stability of their performance—unlike humans, chatbots never get frustrated or tired from doing their job (Luo et al. 2019).
The problem is that it can be hard for users to assess whether they are communicating with a chatbot or a human (Mozafari et al. 2021a, b). With the rise of Large language models (LLMs) like ChatGPT, customer service chatbots are to be substantially improved. The output these LLMs produce appears convincingly natural (Van Dis et al. 2023), making it even more difficult for people to distinguish who they are dealing with during their online interactions, e.g., customer service. This creates an extra layer of transparency concerns, as users have the right to know who they talk to (European Commission 2022).
One of the solutions to avoid this unclarity is to include a disclosure at the start of the interaction, informing the user about the artificial identity of the chatbot, e.g., “Hi! I am the Zalando Chatbot, and I am here to help you!” (Zalando). Regulators are already putting pressure on businesses with regards to such chatbot disclosures. A front-runner in this respect is the California “bot bill” that forces businesses that use chatbots -that may interact with California consumers- to comply with the law and disclose the identity of the chatbot (California Legislative Information 2018). Besides the state of California, the Federal Trade Commission (FTC) also encourages businesses to be transparent about the technology they use, noting that undisclosed use of artificial intelligence (AI) chatbots misleads consumers and could thus face an FTC enforcement action (Federal Trade Commission 2020). In addition, the European Commission states in the AI Act proposal, its first-ever legal framework on AI that some AI systems have specific transparency obligations; this includes that chatbot users should be aware that they are interacting with a machine so they can take an informed decision to continue the interaction or step back (European Commission 2022). The European Parliament is expected to vote about the AI Act in June 2023 (European Parliament 2023). Lastly, disclosure of AI is addressed in the General Data Protection Regulation (GDPR) (Wulf and Seizov 2022).
However, presently, not all companies use disclosures for their customer service chatbots (De Cicco et al. 2021). This seems to be fuelled by the assumption that disclosures may have negative effects (seen from the company’s perspective) (Mozafari et al. 2021a, b). Chatbot disclosure research is still in its infancy, but the first experimental studies indeed showed that disclosures negatively impacted purchases and attitudes (De Cicco et al. 2021; Luo et al. 2019; Mozafari et al. 2021a). However, studies also showed that negative effects depend on certain aspects of the chatbot interaction and on the business field (Mozafari et al. 2021a, b). To understand in a fine-grained manner the role that disclosures play in users’ interactions with customer care chatbots, the current paper presents a mixed methods study that delves into users’ responses to a disclosed vs. undisclosed customer service chatbot.
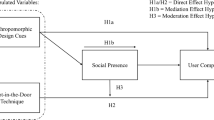
This current mixed method study consists of qualitative interviews to reveal customers’ overall experience of a chatbot interaction and a disclosure’s role in it, and an experiment to test whether the disclosure (versus no disclosure) has an effect on source orientation, anthropomorphism, and social presence. Source orientation (i.e., “who or what people think they are interacting with”, Guzman 2019) is crucial here because the essence of a disclosure is to make clearer to users that they are interacting with a chatbot, so examining whether that goal is achieved is an important first step. Anthropomorphism (i.e., “the assignment of human traits and characteristics to computers”, Nass and Moon 2000), and social presence (i.e., “the sense of being together with another”, Biocca et al. 2003) are also pertinent for this research area. The fact that (customer service) chatbots mimic human–human conversations and are therefore anticipated to lead to perceived anthropomorphism and social presence is seen as the main advantage of chatbots (in comparison to websites for instance) (e.g., Ischen et al. 2020). Companies fear that disclosures diminish these favourable effects, but anthropomorphism and social presence were not studied in previous experimental disclosure studies (except for social presence in De Cicco et al. 2021).
Overall, the holistic approach in the current study, combining interviews with an experiment, helps to grasp what disclosures actually “arouse” in users, which is a stepping stone for further experimental research looking into the effects of chatbot disclosures. Moreover, the insights from this study may inform businesses -that implement AI-powered chatbots- about the benefits and pitfalls of creating a humanlike chatbot and about the need to disclose its identity. In addition, insights on the perceptions and effects of disclosing a chatbot’s artificial nature can inform regulators and help develop policies.
2 Literature review
2.1 Disclosures
So far only a handful of experimental studies have been published on chatbot disclosures. First, they consistently found negative effects of chatbot disclosure on psychological and behavioural user responses (Mozafari et al. 2021a). For instance, a field experiment on voice bots (Luo et al. 2019) showed that disclosing identity at the start of the conversation reduced purchase rates by 79.7%, as the conversational agents were seen as less knowledgeable and emphatic. Another experiment (De Cicco et al. 2021) found that disclosures before the start of the chat were associated with lowered perceived social presence, trust, and attitudes toward the online retailer (compared to no disclosure).
However, recently, a few experimental studies revealed that disclosures did not univocally have undesirable consequences and can lead to positive reactions as well (Mozafari et al. 2020, 2021a, b). In these studies, chatbot disclosures indeed had a negative indirect effect on customer retention through reduced trust for services with high criticality. In contrast, for less critical services, the disclosures did not impact trust at all (Mozafari et al. 2021b). Moreover, in cases where the chatbot failed to handle the customer service issue, disclosing the identity elicited a positive effect on trust (Mozafari et al. 2020) and retention (Mozafari et al. 2021b). Also, an online scenario experiment indicated that disclosing a chatbot’s identity reduced trust, but that pairing the disclosure with selectively presented information on the chatbot’s expertise or weaknesses was able to mitigate this negative effect (Mozafari et al. 2021a).
That disclosures may play a positive role in customer’s experiences is also suggested by Brandtzaeg and Følstad (2018, p. 42) and touched upon in a qualitative study on users’ experiences with customer service chatbots (Van der Goot et al. 2021). Some interviewees perceived humanlike features such as a name and picture to be deceptive and said they appreciated transparency and disclosures. However, the interviews also revealed that disclosures sometimes went by unnoticed.
To better understand these mixed findings on chatbot disclosures, it seems necessary to have a close look at users’ experiences with customer service chatbots and explore how they perceive disclosures within this context. Therefore, the current mixed methods study starts with a qualitative interview study that first addresses the following research question:
RQ1: What is the role of a disclosure in users’ experiences with a customer service chatbot?
2.2 Source orientation
Source orientation has been addressed in qualitative research, for instance in work on perceptions of mobile virtual assistants such as Siri and Google Voice (Guzman 2019). The previously mentioned qualitative study (Van der Goot et al. 2021) in which interviewees interacted with two customer service chatbots -out of in total nine chatbots- showed that people were not united in their source orientation. Most interviewees mentioned the source of information being non-human, using terms like chatbot, virtual agent, algorithms, computer or server. However, some interviewees thought they had communicated with a human being. This confusion was a response to the humanlike style of communicating in chat interfaces and to anthropomorphic cues such names, pictures and gender. The notion of “source orientation” has not been included in the previously mentioned experimental studies on chatbot disclosure effects.
Following this, the qualitative interview study asks:
RQ2: Who or what do people think they are communicating with when communicating with a (disclosed versus undisclosed) chatbot, and what do they base their source orientation on?
Subsequently, for the experimental study it is logical to expect that disclosing will lead to an increased awareness of the source being a chatbot. Therefore, the following hypothesis will be tested:
H1: Disclosing a chatbot’s identity (vs. not disclosing) will lead to an increased awareness of the source of information being a non-human entity.
2.3 Anthropomorphism
The distinguishing characteristic of chatbots is that they humanize access to digital services (e.g., Nißen et al. 2022). Humanization techniques (e.g., Rhim et al. 2022) and anthropomorphic cues (e.g., Go and Sundar 2019) are intentionally added to make the interaction resemble human-to-human communication. Features such as human voice, a name, or the inclusion capable of emotions are often implemented to make the agent more human-like (Klowait 2018). Whether such techniques and cues in chatbots increase perceived anthropomorphism has been studied in several experiments (e.g., Araujo 2018; Hu et al. 2021; Ischen et al. 2020; Rhim et al. 2022; Zarouali et al. 2021). These studies typically include mindless anthropomorphism which concerns the unconscious attribution of human characteristics -such as likeable and friendly- to chatbots (Kim and Sundar 2012), and mindful anthropomorphism relating to the conscious evaluation of an agent as being humanlike versus machinelike (Powers and Kiesler 2006).
A considerable number of contemporary customer care chatbots deployed on the market include one or more of the aforementioned anthropomorphic features. Moreover, previous chatbot disclosure research did not focus on anthropomorphism. Therefore, the qualitative interview study will explore whether the disclosure changes the ways in which users anthropomorphize the interactions:
RQ3: How do users anthropomorphize interactions with a (disclosed vs. undisclosed) customer service chatbot?
For the experiment, we can expect that a disclosure leads to more awareness of the artificial nature of the source (hypothesis 1) and thus also to lower levels of anthropomorphism:
H2: Disclosing a chatbot’s identity (vs. not disclosing) will lead to lower levels of (a) mindless and (b) mindful anthropomorphism.
2.4 Social presence
Social presence implies that the user gets a feel of human warmth and sociability while interacting with a chatbot (Ischen et al. 2020). Chatbot research often measures this, assuming that more humanlike chatbots will lead to more social presence (compared to less humanlike chatbots) (e.g., Araujo 2018; Ischen et al. 2020; Rhim et al. 2022). Turning to disclosure studies, De Cicco et al. (2021) found that participants exposed to the undisclosed version of the chatbot perceived higher levels of social presence as opposed to the ones who interacted with the disclosed chatbot. In the current qualitative study, we aim to delve further into this by asking:
RQ4: How do users experience social presence when communicating with a disclosed vs. undisclosed chatbot, in other words, in what ways do they experience the chatbot as an actual social actor?
In line with De Cicco et al.’s findings, the experiment will test the following expectation:
H3: Disclosing a chatbot’s identity (vs. not disclosing) will lead to lower levels of social presence.
3 Mixed methods design
The study implemented a sequential mixed methods design, with semi-structured qualitative interviews being conducted first. The interviews aimed to get a deeper understanding of users’ responses to the disclosed vs. undisclosed chatbot. Second, single factor (disclosure vs. no disclosure) between-subject online experiment was conducted, in which the hypotheses were tested. Both studies were conducted online. The study received IRB approval.
3.1 Stimuli
Two versions of the chatbot (disclosed vs. undisclosed) were created using the Conversational Agent Research Toolkit (CART) (Araujo 2020) and hosted on university servers. The chatbot was integrated into Qualtrics where all the interactions between participants and the chatbot took place in both phases of the study. All conversations were stored in logs on a secured database, also arranged by the university.
The chatbot conversation included humanlike linguistic cues such as “oh no, apologies for that” (Verhagen et al. 2014) and an identity cue (i.e., the human name “Sara”). The name “Sara” also suggested a female gender, as users typically prefer “female” chatbots over their “male” counterparts and perceive them as more humanlike (Borau et al. 2021; Toader et al. 2020).
The disclosed version introduced itself as “Hi there. My name is Sara, a chatbot from Yummy to Eat” whereas the undisclosed introduction read: “Hi there. My name is Sara from Yummy to Eat” (Fig. 1). The word “chatbot” is in line with previous disclosure research (De Cicco et al. 2021; Luo et al. 2019; Mozafari et al. 2020, 2021a, b) and with disclosures commonly used by well-known companies such as Zalando and Easy Jet to signal that the user interacts with an artificial agent. The label “chatbot” is also used by the European Union’s bodies, Federal Trade Commission and other international agencies to refer to non-human conversational agents in their official documents and press releases.

Introduction of the Chatbot
A script about a food order made through a fictitious delivery company called Yummy to Eat was created. The chatbot asked a set of questions about the participant’s (fictitious) order, and the participants answered in free text using information provided in the scenario they read beforehand. The script for the chatbot was slightly adjusted after the qualitative interview study to simplify it and make it more intuitive. Both versions of the script can be found in the Appendix.
4 Method qualitative interview study
4.1 Participants
Eight respondents were recruited for the interviews using convenience sampling. An invitation to participate in the study was disseminated via the second author’s social media account feeds (i.e., Facebook, Instagram). Only potential interviewees who were not familiar with the study topic were selected for the interviews. The sample (n = 8) consisted of five people who identified as females and three as males, aged between 24 and 26 years, mostly highly educated—two with high school graduation, three with a Bachelor’s degree, and three with a Master’s degree. Seven out of eight interviewees were Czech, one was Spanish. Most interviewees lived in the Czech Republic, one resided in Austria and one in Switzerland (so all in Central Europe). None of the interviewees was a native English speaker.
4.2 Interviews
The interviews lasted between 40 and 60 min, and were conducted in English, through Zoom, in May 2021. The second author was the interviewer (female, in her twenties). Prior to the interview, interviewees signed the informed consent form. The interviewer used an interview guide, and the interview contained interactions with the two chatbots. No adjustments to the guide were made during the process of conducting the qualitative study. At the end of the interview, interviewees were debriefed and asked whether they had any additional questions. The interviews were video-recorded and transcribed verbatim. An incentive in the form of a €10 gift voucher was offered to the participants, but none of them accepted. Therefore, the interviewees voluntarily received no remuneration.
4.2.1 Interview guide
After introducing the interview and ground rules, a warm-up round of questions about previous experiences with customer service was asked. Subsequently, interviewees first interacted with the undisclosed chatbot, answered questions about this interaction, then interacted with the disclosed chatbot, and answered questions about this second interaction. This sequence was chosen to be able to assess the added value of the disclosure.
For each interaction, the guide consisted of five topics in this order: (1) evaluation of the interaction, (2) mindless anthropomorphism, (3) mindful anthropomorphism, (4) social presence, and (5) source orientation. The topics were abbreviated after the second interaction (compared to the first interaction), in the sense that the interviewer then asked about whether the perceptions and ratings had changed. For each topic, the guide provided an initial question and potential probes.
Evaluation of the interaction Topic 1 started with the question “Please share with me all your experiences during this chat (anything!). Could you tell me about the interaction?” The interviewer further probed into what the interviewee liked and disliked.
Mindless anthropomorphism Four items—likeable, sociable, friendly, personal, belonging to the instrument from Kim and Sundar (2012) were used (e.g., “how likeable did Sare seem to you?”). Once the interviewees gave a rating (on a 10-point scale), they were asked to elaborate on what led them to that specific rating. They were also invited to mention additional adjectives that they felt described Sara best.
Mindful anthropomorphism We used Powers and Kiesler’s (2006) measurement asking the participants to rate the chatbot on three items, i.e., humanlike/machinelike, natural/unnatural, lifelike/artificial, on a 7-point semantic differential scale was used (e.g., “how humanlike or machinelike did Sara seem to you?”) and to explain their answer.
Social presence First, a blob tree illustration with 21 different blobs expressing different states (see blobtree.com) was used as a technique to elicit participants’ experiences on the interaction they had (Greenbaum 2000). Second, the seven-item scale from Lee et al. (2006) was used. For instance, participants were asked to rate on a 10-point scale “How much did you feel as if you were interacting with an intelligent being?” Again, the interviewees were probed to elaborate on their ratings.
Source orientation Interviewees were asked an open-ended question “Who or what do you think was at the other end?” They were probed to elaborate, and then the interviewer posed two additional sub-questions, first to get a deeper understanding of what made them think that, and the second asking them to provide an explanation of how whoever was at the other side operated in providing the replies.
4.3 Analysis
The interviews were transcribed using Otter.ai transcription software. Fragments that the software was unable to process were edited manually. All transcripts were imported into ATLAS.ti. Coding procedures were derived from Charmaz (2006). First, initial coding of each interview was performed. In her coding of the interviews, the interviewer/second author paid attention to all concepts and items that were part of the four research questions (e.g., friendly as an item for mindless anthropomorphism) and she coded in a detailed way what interviewees had said about this (for instance a code would be “friendly—the words she was using were positive”). Segments of the text were assigned either one or multiple codes, depending on the richness of the information. This resulted in a list of about 450 codes. Furthermore, a high number of in vivo codes was tagged.
When initial coding of all interviews was finished, focus coding was executed to give the codes a structure. After this coding was done for all interviews, the second author made eight code groups: for each research question there was a group containing the codes for the undisclosed interaction and one for the disclosed interaction. The first and second author thoroughly inspected the codes per group and reread the related interview fragments, and used this as input to formulate the results that answer the four research questions. Memos were written during the data collection and the analysis to keep track of the process.
5 Results qualitative interview study
5.1 Overall experience and the role of the disclosure
Regarding RQ1, the interviews showed an overall positive experience with the chatbot: interviewees mentioned that Yummy to Eat was an easy-to-use service, communicating with their customers in a friendly and warm manner. All interviewees articulated their appreciation of the immediate full monetary refund that was offered to them because they had received the wrong pizza and their order was delayed. The refund played a crucial role in how the interaction was experienced by the interviewees, as some kept mentioning it throughout the interview. Despite this satisfaction with the refund, some interviewees were irritated by the fact that the chatbot in some cases did not understand the users’ input, and that they were asked to rephrase their messages.
In the second interaction, interviewees were asked to interact with the chatbot in the same way, the only difference being that this time there was a disclosure: “Hi there! My name is Sara, a chatbot from Yummy to Eat”. Not all interviewees noticed the disclosure. The interviewees who did see the disclosure appreciated it as it made univocally clear that it was a chatbot: “Now I definitely knew that it wasn’t real person” (Interviewee 4). Second, the disclosure helped users to know what to expect and how to type, and this reduced the effort they needed to put in. Interviewee 8 formulated it as follows: “Definitely the information that I’m communicating with a chatbot made it more straightforward. Like no, no need to be polite, or, I don’t know, write complicated sentences. Basically, just save my time and energy”. Third, knowing for sure that it is a chatbot also led users to be impressed more. Interviewee 3 compared the interaction with the disclosure with the previous undisclosed one and said:
“I was being impressed with the way the chatbot was communicating, just because it seemed like so smooth”. Since the refund stayed the same, interviewees’ overall positive evaluations did not change due to the disclosure.
5.2 Source orientation
RQ2 tapped into who or what people think they are communicating with when interacting with a (un)disclosed chatbot. Upon interacting with the first, undisclosed chatbot, seven out of eight interviewees were quite sure they had been interacting with a non-human entity. Half of the interviewees stated that they thought they were chatting with an artificial intelligence (AI) entity. Two respondents described Sara as hardware (i.e., computer and machine). One interviewee, who was quite confident that she was interacting with a chatbot from the very start, said that even after being asked all the interview questions, she still perceived the conversational agent to be a chatbot. All interviewees were consistent in their answers even after interacting with the disclosed version of the chatbot. One interviewee was not sure about the source; she suggested there could have been a robot supervised by a human. Interviewees’ understandings of how this worked came down to the following: “Probably, it’s programmed in a certain way, and it usually gives the same answers or reactions to any complaints” (Interviewee 6).
Interviewees used several cues to inform them that they were interacting with a non-human entity. First, the answers came very fast: “If a real person was typing it, it would take longer” (Interviewee 5). Second, there was repetition, misunderstanding, and the necessity to reformulate their input: “I felt like I was chatting with a machine because I have written some info about the order. And then I was asked again about the same thing” (Interviewee 4). Third, the grammar was too good: “Maybe also because the grammar was really good, because you know, like, humans, humans can make mistakes. They can make typos, stuff, which didn’t happen” (Interviewee 3). Overall, previous experiences with chatbots and/or customer service also play a role here. For instance, interviewee 6 had previously worked in customer service, which gave her certain background information.
5.3 Anthropomorphism
RQ3 asked about the ways in which users anthropomorphize interactions with a (un)disclosed customer service chatbot. Anthropomorphism was apparent in how interviewees talked about the chatbot. Some used the name “Sara”, the pronoun “she”, and used formulations typically used for humans, seemingly ascribing some agency to the chatbot, for instance: “She was able to help me with the issue” (Interviewee 5) and “She was just doing her job” (Interviewee 4). Interestingly, they kept referring to the chatbot as Sara even in the disclosed condition when the fact that it is a non-human entity was explicitly communicated to them.
Overall, the disclosure of the chatbot’s identity only made a subtle difference in how interviewees experienced the interaction. The results show that the human-like tone of voice and agreeable behaviour of the chatbot, in combination with the refund that was suggested, played major roles in how interviewees evaluated anthropomorphism.
5.3.1 Mindless anthropomorphism
The interviews revealed how users assigned human characteristics to the chatbot. Out of the typical scale items for mindless anthropomorphism, i.e., likeable, sociable, friendly, and personal (Kim and Sundar 2012), interviewees graded the chatbot particularly high on friendliness. All interviewees, except for one, thought of Sara as a friendly creature who interacted in a friendly manner with a friendly tone of voice. Interviewee 4, who gave Sara a score of 10, said: “Yeah, well, she was very helpful. I mean, it felt like two friends”. Like in this quote, the additional adjective “helpful” was spontaneously mentioned by multiple interviewees. Interviewee 5 gave a score of 8 here, “because she helped me really fast”. For the disclosed interaction, none of the interviewees changed these perceptions.
In response to “likeable”, half of the interviewees mentioned that Sara was polite in the interaction, as she was apologising for the error with the delivery that had occurred and was trying to take care of the situation to resolve it. Interviewee 2, who gave a score of 8, described undisclosed Sara as follows:
Like she was saying things like “oh, I’m sorry about it”, like apologizing, you know, and that always makes you feel like comforted a bit. And it seemed like she was paying attention to the case, you know, asking more questions and offering a solution.
For the disclosed interaction, some interviewees thought the chatbot was slightly less likeable, due to knowing that the interaction was scripted and thus deeming the apologies less sincere.
For “sociable”, interviewees provided more diverse reasonings for their scores. Some did not perceive Sara as sociable because she was “just doing her job” (interviewee 4) or because it was a chatbot (interviewee 6), whereas others said that she showed compassion and empathy, and was approachable: “I think maybe because she showed some compassion or empathy, like ‘I’m sorry, you’re having this issues’. So that seems like social trait” (Interviewee 5). For the disclosed interaction, all but one interviewee, who was bothered by the need to repeat information that the chatbot did not understand, kept the scores.
For “personal”, the scores were lowest. Interviewees did not think of (either disclosed or undisclosed) Sara as personal, because they thought that the conversation she had with them was not different from other chats she has with customers and perceived her rather impersonal: “Just like an interaction that she has with loads of people during the day” (Interviewee 5). The fact that some interviewees were asked to rephrase their answers to Sara was also mentioned as a reason for giving a low score.
5.3.2 Mindful anthropomorphism
The qualitative interviews also revealed how people reacted to the measures of mindful anthropomorphism, using the scale from Powers and Kiesler (2006). Interviewees saw evidence for both the humanlike (natural, lifelike) as well as the machinelike (unnatural, artificial) side, leading to variation in scores. For humanlike/machinelike, scores leaned toward machinelike when interviewees focused on repetition in the interaction when the chatbot did not understand a user’s input and asked to rephrase it: “I already told her the time I did the order. And then she asked again. So, she couldn’t grab that information from previous messages” (Interviewee 2).
For “natural/unnatural”, the situation was different. Despite the label “chatbot”, Sara was still rated as a natural being by almost all interviewees. They appreciated the language she used, the fact that the interaction went smooth, and that she asked the right questions. Interviewee 3 said: “Of course, now, it’s judging that we already know that it was a machine. I wouldn’t be able to tell for sure throughout like 90% of the conversation. So yeah, it was like a natural experience.
For “lifelike/artificial”, interviewees gave, on average, scores at the mid-point of the scale. They said that although they knew that Sara was artificial, because she was a chatbot, at the same time, she was acting lifelike and that is why they had difficulties deciding how to rate her: “Well, it was clear that I was communicating with a chatbot. So, it struck me right ahead. But I didn’t mind at all because, as I said, the conversation was very nice and really warm” (Interviewee 6).
5.3.3 Social presence
RQ4 asked how users experienced social presence when communicating with a (un)disclosed chatbot. As evidenced in the results for RQ1-3, as well as in the responses to the blob tree (see the interview guide), the interviewees perceived the chatbot as a social entity that lent a helping hand and that offered a solution. As interviewee 7 said: “then she told me she will get my money back.” Overall, for the disclosed interaction, the fact that users were helped still was centre stage. For instance, talking about the disclosed interaction, interviewee 2 expressed that the fact that she got an appropriate solution was more important than that it came from an artificial entity: “She still helped me, even though it’s a machine.”
Although not all interviewees were necessarily satisfied with how their complaints were handled from the beginning to the end, it was quite apparent from their descriptions that the fictitious scenario did its job in transporting the respondents into the hypothetical situation of having a problem with a food order and solving it together with a customer care representative. The degree to which the agent helped them was mentioned by all interviewees, highlighting the fact that the helpfulness of the chatbot was among the main drivers of the overall impression, leading to a rather positive perception of the conversational agent.
Social presence scale Responses to the scale items signalled that, although some interviewees were already sensing that it was not a human who they were talking to, they described the agent as an intelligent being that communicated with them because they saw the conversation progressing: “I think we were [communicating], because we were getting to the close end, and I still see such communication as effective. So, if the conversation has an ending, I think we can still communicate with each other” (Interviewee 6).
As the interviewees were offered the refund right away and did not have to ask for it, their level of involvement was not very high. This feeling seemed to translate into the description of how specific the answers were towards them as individuals. For some, the fact that the agent seemed to care about their problem and gave them appropriate answers was enough of a reason to be satisfied with its performance, even though it was scripted: “I feel like she was responding to me. I mean, it was clear to me that she’s algorithm, she’s a robot. But at the same time, I didn’t feel irritated by it so far, I got the right response” (Interviewee 8).
5.4 Conclusion qualitative interview study
The results can be summarized with one of the interview quotes: “She still helped me, even though it’s a machine.” Interviewees anthropomorphized the chatbot into a Sara that was friendly and helped them getting a refund. For the interviewees who noticed the disclosure, the disclosure was useful because it reduced their efforts of finding out who or what they were communicating with, and how they needed to type their input. At the same time, it did not seem to change their perceptions of helpful Sara.
6 Method experiment
The development of the experiment was guided by the hypotheses and the results of the qualitative interview study that preceded. Minor adjustments to the scales will be described. The experiment was a single factor (disclosure vs. no disclosure) between-subject design.
6.1 Procedure
Participants were recruited among Amazon Mechanical Turk (MTurk) workers (Sheehan 2018). To avoid low-quality responses and to minimize the chance of bots filling out the questionnaire, the following requirements were set in Mturk: having 98% approval rate (proportion of tasks that were completed and approved by the requester), at least 10.000 HITs (assignments) finished, and a Master qualification (answering accuracy in different types of tasks) (Amazon Mechanical Turk 2021).
Participants’ answers were recorded in Qualtrics, and the logs of the chatbot interactions were saved in a secured database. Participation was voluntary, took place in June 2021, and each participant was paid $2. After reading the informed consent and agreeing to participate, participants were randomly assigned to either the undisclosed or disclosed condition. Then they were instructed to interact with the chatbot based on the fictitious scenario and after that they answered questions about their perceptions of Sara (i.e., mindless and mindful anthropomorphism, social presence, source orientation). Finally, they were asked about their demographics and debriefed.
6.2 Sample characteristics
An a priori power analysis in G*Power for a between-groups comparison (Difference between two independent means) with expected effect size f = 0.5, α-level = 0.05, power = 0.80 suggested that a sample size of 128 was needed. A total of 210 people participated in the study. Over-recruiting was done to secure that after implementation of exclusion criteria there would still be enough participants ensuring sufficient statistical power. All participants who did not finish the interaction with the chatbot were excluded (n = 5), and so were duplicate responses (n = 11). No participants failed the attention check.
The final sample (n = 194) consisted of 58.8% males and 41.2% females mainly residing in the United States of America (78.4%), followed by India (18.6%). Similarly, 77.8% were of American and 18.6% of Indian nationality. For 86.6% of the participants, English was their mother tongue. Participants had mostly completed higher education (25.3% secondary school, 56.2% Bachelor’s degree, 16% Master’s degree), were aged between 22 and 71 (M = 41.31, SD = 9.62), 87.6% had interacted with a chatbot prior to this study and surprisingly, 43.8% had previous work experience in customer service.
6.3 Measurements
6.3.1 Mindless anthropomorphism
The same measure (Kim and Sundar 2012) that was used in the interviews was used in the experiment, but this time on a scale ranging from 1 to 7, to unify the rating scales across concepts (Menold and Tausch 2016): “Please indicate how the following adjectives describe your perception of Sara on scale from 1 (describes very poorly) to 7 (describes very well)”. Based on the results of the qualitative study, the adjective “helpful” was added to the scale. The five scale items were averaged (Cronbach’s alpha = 0.88; M = 5.71, SD = 1.06) with higher scores on the scale meaning that Sara was perceived more humanlike.
6.3.2 Mindful anthropomorphism
Powers and Kiesler’s (2006) three items (“The customer care representative I have just interacted with was: humanlike—machinelike; natural—unnatural; lifelike—artificial”) were used again and a mean score was calculated (Cronbach’s alpha = 0.92, M = 5.31, SD = 1.49). Items were recoded so that higher scores mean that Sara was perceived as more humanlike.
6.3.3 Social presence
The previously mentioned seven items of Lee et al. (2006) (e.g., “How much did you feel as if you were interacting with an intelligent being?”) were used with a scale now ranging from 1 (not at all) to 7 (absolutely). One reverse item was recoded and a mean was computed (Cronbach’s alpha = 0.88, M = 5.81, SD = 1.00). Higher scores mean that Sara was perceived more like an actual social actor.
6.3.4 Source orientation
Using the responses in the interview study, we listed the following answer options to the question “who or what do you think was at the other end of the conversation with Yummy to Eat?”: “human being”, “computer”, “artificial intelligence”, “chatbot”, “I do not know”, and “other” with an open-ended text entry. The participants were asked to pick one option. For the analysis, the variable was recoded to a new one: “human being” (20.1%), “non-human being” (74.2%) -combining computer, artificial intelligence, and chatbot- and “I do not know” (5.7%).
6.3.5 Manipulation check
Participants were asked to indicate what introductory statement had been used. The answer options were “Hi there! My name is Sara from Yummy to Eat and I am here to assist you with your order”, “Hi there! My name is Sara, a chatbot from Yummy to Eat, and I am here to assist you with your order”, “I do not remember”, and “other”.
6.3.6 Background variables and attention check
Like in the interview study, age, gender identity, highest education obtained, nationality, country of residence, and English as mother tongue were assessed as background characteristics. Furthermore, based on the results of the interviews, a question about previous working experience in customer care was included. To assess whether respondents were paying attention to the experiment, a simple question non-related to the content of the study was included. None of the participants failed the attention check.
7 Results experiment
7.1 Manipulation check
The chi-square test suggested that the manipulation of the disclosure was successful, χ2 (3) = 14.75, p = 0.002. In the undisclosed condition, 75.5% of participants correctly reported that customer service representative wrote: “Hi there! My name is Sara from Yummy to Eat […]”. However, only 24% of participants in the disclosed condition correctly indicated that the introductory text read: “Hi there! My name is Sara, a chatbot from Yummy to Eat […]” (see Table 1). Based on that, we conclude that people could not accurately remember how the chatbot introduced itself.
7.2 Randomization check
A one-way ANOVA with the conditions as an independent variable and age as the dependent variable, F(1, 192) = 0.18, p = 0.672, and chi-square tests for the conditions and the remaining background variables were conducted. Besides the check for gender, which was significant, χ2 (1) = 5.78, p = 0.016, the two conditions did not differ on other background variables (see Table 2). Therefore, gender was included as a covariate in all statistical analyses.
7.3 Source orientation
H1 expected that disclosing a chatbot’s identity (vs. not disclosing) would lead to higher scores of labelling the source of information as a non-human being. A chi-square test with gender as a covariate was conducted, χ2 (2) = 5.26, p = 0.072, and showed that although more participants in the undisclosed condition labelled the chatbot as a human being (26.6%) than in the disclosed condition (14%), the difference was not significant. In both conditions, the majority of participants—67% in the undisclosed and 74.2% in the disclosed—correctly determined that Sara was a non-human being (see Table 3). Therefore, H1 was rejected.
7.4 Anthropomorphism and social presence
It was hypothesized that disclosing a chatbot’s identity (vs. not disclosing) would lead to lower levels of mindless (H2a) and mindful (H2b) anthropomorphism, and to lower levels of social presence (H3). To test these hypotheses, a MANCOVA was conducted with disclosure (vs. no disclosure) as the independent variable, mindless and mindful anthropomorphism and social presence as the dependent variables, and gender as the covariate. There was no significant multivariate effect of the disclosure, Wilk’s Lamda = 0.98, F(3, 189) = 1.01, p = 0.391, η2 = 0.016.
In line with the multivariate test, the univariate tests were not statistically significant for mindless anthropomorphism, F(1, 191) = 0.69, p = 0.408, η2 = 0.004, mindful anthropomorphism, F(1, 191) = 0.28, p = 0.596, η2 = 0.001, and social presence, F(1,191) = 0.41, p = 0.524, η2 = 0.002 (for means, see Table 4). Therefore, H2a, H2b and H3 were rejected.
7.5 Conclusion experiment
Overall, the findings of the experiment suggest that a chatbot disclosure (versus no disclosure) does not lead to increased perceptions of the chatbot being a non-human entity, nor to decreased mindless and mindful anthropomorphism, and social presence.
8 Discussion
This paper presented a mixed methods study that delved into users’ responses to a disclosed vs. undisclosed customer service chatbot. The combination of both an interview study and an experiment made it possible to understand in a more fine-grained manner what role disclosures play in users’ interactions with customer care chatbots. Specifically, source orientation, anthropomorphism, and social presence were studied because they relate to the essential characteristics of human-chatbot communication, whereas they have not been studied yet in the new and recent field of chatbot disclosure research (expect for social presence in the experiment by De Cicco et al. 2021).
The first overall observation is that the disclosure did not impact source orientation, i.e., the disclosure did not lead to increased awareness that the interaction partner was a non-human entity. A first explanation is that -both in the interview study and in the experiment- not all participants saw the disclosure. In line with previous research (De Cicco et al. 2021; Luo et al. 2019; Mozafari et al. 2020, 2021a, b) the current disclosure essentially was the word “chatbot”, but this perhaps a more elaborate disclosure is needed to impact source orientation.
In addition, the interviews revealed how users of an undisclosed chatbot use other cues than a disclosure to infer who or what they are communicating with: the speed in which they receive an answer, the repetitions and misunderstandings, and the grammar (if it is too correct, it cannot be a human). Interestingly, for most interviewees, the disclosure served as confirmation of their suspicion that it was unlikely that the entity at the other end would be a human, and with the disclosure it became “official” that it really was not a person but a chatbot. This clarity reduced the cognitive effort they needed to invest in assessing what they were interacting with. Thus, future research should study the effects of disclosures on source orientation in relation to the impact of the above-mentioned other cues.
It is important to note that 20% of the participants (in the experiment) thought they had communicated with a human. This is a substantial amount of people, especially taking into account that this interaction took place in the context of an online survey, and that 87% of these participants had interacted with a chatbot prior to this study, and 44% had previous work experience in customer service. This points to the importance of the problem with which the current paper started: it is difficult for people to know whether they are communicating with a chatbot or a human being (Mozafari et al. 2020), and future research should keep assessing how different types of disclosures (and cues) can provide more clarity to users.
The second overall observation is that participants anthropomorphized the chatbot and perceived it as an actual social entity, even when the disclosure was present. The interviewees talked about Sara as a friendly entity that helped them getting a refund, and the participants in the experiment gave high scores for mindless anthropomorphism, mindful anthropomorphism (i.e., giving scores on the humanlike/natural/lifelike side) and social presence-regardless of whether they interacted with the disclosed or undisclosed version. Moreover, the perception of being helped, with the refund, was the central element in interviewees’ overall evaluations of the interactions, which seemed more important than that it was a machine that offered this help. This in line with previous qualitative research in which interviewees clearly expressed that receiving adequate help is most important in any customer service chatbot interaction (Van der Goot et al. 2021). In sum, although past experimental chatbot disclosure research showed negative effects on several outcome measures -that could be mitigated by some other features- (De Cicco et al. 2021; Luo et al. 2019; Mozafari et al. 2020, 2021a, b), the current study showed that perceived anthropomorphism and social presence remained high, regardless of the disclosure.
The third overall observation is that the mixed method approach proved to be useful. The experiment showed insignificant results, and the interview study helped to understand these. The interviews showed how the users’ focus on friendly Sara who helped with the refund made the disclosure and the fact that they communicated with a chatbot of minor importance.
To conclude, the relevance of our findings is further magnified in light of the increase of LLMs like ChatGTP. Transparency concerns will likely become even more pressing (Van Dis et al. 2023) and regulations such as the AI Act and the call for disclosures are important steps forward. However, our study implies that adding the disclosures that were studied here, does not effectively enhance transparency. Therefore, more research and more discussion on how transparency of chatbots can be increased is crucial.
8.1 Limitations and future research
The current findings were coloured by the fact that the chatbot helped customers to receive a refund. In line with the previous study by Mozafari et al. (2020), the findings need to be compared with a situation in which the chatbot fails to provide help. It should also be explored whether the disclosure plays a bigger role for other types of customer queries. This new line of research should also compare findings of studies working with fictitious scenarios -like the current one- with findings of field studies using data of actual companies (e.g., Luo et al. 2019).
In the current interviews, all interviewees first interacted with the undisclosed chatbot -and then with the disclosed one-, in order to detail the added value of the disclosure. The disadvantage was that interviewees’ (un)changed perceptions of the second interaction were not only due to the disclosure but also because they repeated an identical conversation with the chatbot. Therefore, future interview studies need to explore how interviewees respond to a disclosed chatbot interaction, without having them interact with an undisclosed version first.
To disclose the chatbot, we added the word chatbot in the disclosure condition. However, this manipulation could be considered a limitation of our study. Future research should look into more elaborate disclosures and disclosures that are repeated throughout the interaction. These studies should indicate whether there are disclosure formats that can have an effect on people’ s perception of chatbots as being human or a machine. It is also called for to study disclosures that use other words than “chatbot”, because the current interview study and a previous one (Van der Goot et al. 2021) showed that only some users used the term “chatbot” to describe the entity they had been interacting with.
In terms of user perceptions, the present study focused on source orientation, anthropomorphism, and social presence. Particularly anthropomorphism and social presence are often used as mediators in chatbot effect research (e.g., Hu et al. 2021; Ischen et al. 2020; Rhim et al. 2022; Zarouali et al. 2021). Future disclosure research may add to the current insights by including persuasive outcomes of chatbot interactions, such as brand attitudes, and behavioral intentions toward the brand and the chatbot. This will provide more insights into how disclosing chatbots’ artificial nature affects not only users’ entity perceptions but also whether it affects persuasion or resistance.
8.2 Practical implications
In their ambitions regarding transparent AI, regulators are pointing to the importance of having disclosures that explicitly state that the interaction partner is a chatbot (California Legislative Information 2018; European Commission 2022; Federal Trade Commission 2020). This indeed seems like a good starting point: in that case, the information is objectively there, meaning that customers can know that it is a machine that they are communicating with. However, the present study shows that it is not that straightforward: users may not see the disclosure, other cues may play a more profound role in identity perceptions than the disclosure, and the word “chatbot” may not be clear to all users. For transparency regulations this implies that simply identifying a chatbot as such may not be enough. More extensive disclosures or explanations may be needed to truly enhance transparency. It is important that legislators are aware of these complexities, and that there is a collaborative effort in designing studies that help to uncover which solutions lead to most transparency.
The main takeaway message for businesses using customer service chatbots is that the provision of satisfactory help and an amiable tone of voice matter more to users than a disclosure. In that sense, businesses should not shy away of being transparent about the technology they are using and can safely comply with the regulations.
Data availability
Data are available from the first author on request.
Notes
Participant’s lines mean what was expected that the participant would answer based on the instructions that were given and the questions that were posed by the chatbot.
References
Amazon Mechanical Turk (2021) Qualifications and worker task quality: happenings at MTurk. MTurk. https://blog.mturk.com/qualifications-and-worker-task-quality-best-practices-886f1f4e03fc. Accessed 9 Jan 2023
Ameen N, Tarhini A, Reppel A, Anand A (2021) Customer experiences in the age of artificial intelligence. Comput Hum Behav. https://doi.org/10.1016/j.chb.2020.106548
Araujo T (2018) Living up to the chatbot hype: the influence of anthropomorphic design cues and communicative agency framing on conversational agent and company perceptions. Comput Hum Behav 85:183–189. https://doi.org/10.1016/j.chb.2018.03.051
Araujo T (2020) Conversational agent research toolkit: an alternative for creating and managing chatbots for experimental research. Comput Commun Res 2(1):25–51. https://doi.org/10.5117/CCR2020.1.002.ARAU
Biocca F, Harms C, Burgoon JK (2003) Toward a more robust theory and measure of social presence: review and suggested criteria. Presence 12(5):456–480
Borau S, Otterbring T, Laporte S, Fosso Wamba S (2021) The most human bot: female gendering increases humanness perceptions of bots and acceptance of AI. Psychol Mark 38(7):1052–1068. https://doi.org/10.1002/mar.21480
Brandtzaeg PB, Følstad A (2018) Chatbots: changing user needs and motivations. Interactions 25(5):38–43. https://doi.org/10.1145/3236669
California Legislative Information (2018) SB-1001 Bots: disclosure. https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id5201720180SB1001. Accessed 9 Jan 2023
Charmaz K (2006) Constructing grounded theory: a practical guide through qualitative analysis. Sage, London
De Cicco R, Silva SC, Palumbo R (2021) Should a chatbot disclose itself? Implications for an online conversational retailer. In: Følstad A et al (eds) Conversations 2020 (LNCS), vol 12604. Springer, Cham, pp 190–204. https://doi.org/10.1007/978-3-030-68288-0_1
European Commission (2022) Regulatory framework proposal on artificial intelligence. https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai. Accessed 9 Jan 2023
European Parliament (2023) AI Act: a step closer to the first rules on Artificial Intelligence. https://www.europarl.europa.eu/news/en/press-room/20230505IPR84904/ai-act-a-step-closer-to-the-first-rules-on-artificial-intelligence. Accessed 9 Jan 2023
Federal Trade Commission (2020) Using artificial intelligence and algorithms. https://www.ftc.gov/business-guidance/blog/2020/04/using-artificial-intelligence-algorithms. Accessed 9 Jan 2023
Go E, Sundar SS (2019) Humanizing chatbots: the effects of visual, identity and conversational cues on humanness perceptions. Comput Hum Behav 97:304–316. https://doi.org/10.1016/j.chb.2019.01.020
Greenbaum T (2000) Moderating focus groups: a practical guide for group facilitation. Sage, Thousand Oaks. https://doi.org/10.4135/9781483328522.n15
Guzman AL (2019) Voices in and of the machine: source orientation toward mobile virtual assistants. Comput Hum Behav 90:343–350. https://doi.org/10.1016/j.chb.2018.08.009
Hu P, Lu Y, Gong Y (2021) Dual humanness and trust in conversational AI: a person-centered approach. Comput Hum Behav. https://doi.org/10.1016/j.chb.2021.106727
Ischen C, Araujo T, van Noort G, Voorveld H, Smit E (2020) “I am here to assist you today”: the role of entity, interactivity and experiential perceptions in chatbot persuasion. J Broadcast Electron Media 64(4):615–639. https://doi.org/10.1080/08838151.2020.1834297
Kim Y, Sundar SS (2012) Anthropomorphism of computers: is it mindful or mindless? Comput Hum Behav 28:241–250. https://doi.org/10.1016/j.chb.2011.09.006
Klowait NO (2018) The quest for appropriate models of human-likeness: anthropomorphism in media equation research. AI Soc 33(4):527–536. https://doi.org/10.1007/s00146-017-0746-z
Lee KM (2004) Presence, explicated. Commun Theory 14(1):27–50
Lee KM, Jung Y, Kim J, Kim SR (2006) Are physically embodied social agents better than disembodied social agents? The effects of physical embodiment, tactile interaction, and people’s loneliness in human–robot interaction. Int J Hum Comput Stud 64(10):962–973. https://doi.org/10.1016/j.ijhcs.2006.05.002
Luo X, Tong S, Fang Z, Qu Z (2019) Frontiers: machines vs. humans: the impact of artificial intelligence chatbot disclosure on customer purchases. Market Sci 38(6):937–947. https://doi.org/10.1287/mksc.2019.1192
Menold N, Tausch A (2016) Measurement of latent variables with different rating scales: testing reliability and measurement equivalence by varying the verbalization and number of categories. Sociol Methods Res 45(4):678–699. https://doi.org/10.1177/0049124115583913
Mozafari N, Weiger W, Hammerschmidt M (2020) The chatbot disclosure dilemma: desirable and undesirable effects of disclosing the non-human identity of chatbots. In: Proceedings of the 41st international conference on information systems
Mozafari N, Weiger W, Hammerschmidt M (2021a) Resolving the chatbot disclosure dilemma: leveraging selective self-presentation to mitigate the negative effect of chatbot disclosure. In: Proceedings of the 54th Hawaii conference on system sciences
Mozafari N, Weiger W, Hammerschmidt M (2021b) Trust me, I’m a bot: repercussions of chatbot disclosure in different service frontline setting. J Serv Manag 33(2):221–245. https://doi.org/10.1108/JOSM-10-2020-0380
Nass C, Moon Y (2000) Machines and mindlessness: social responses to computers. J Soc Issues 56(1):81–103
Nißen M, Selimi D, Janssen A, Cardona DR, Breitner MH, Kowatsch T, von Wangenheim F (2022) See you soon again, chatbot? A design taxonomy to characterize user-chatbot relationships with different time horizons. Comput Hum Behav. https://doi.org/10.1016/j.chb.2021.107043
Powers A, Kiesler S (2006) The advisor robot: tracing people’s mental model from a robot’s physical attributes. In: Proceedings of the 1st ACM SIGCHI/SIGART conference on human-robot interaction, pp 218–225. https://doi.org/10.1145/1121241.1121280
Rhim J, Kwak M, Gong Y, Gweon G (2022) Application of humanization to survey chatbots: change in chatbot perception, interaction experience, and survey data quality. Comput Hum Behav 126:107034. https://doi.org/10.1016/j.chb.2021.107034
Sheehan KB (2018) Crowdsourcing research: data collection with Amazon’s mechanical Turk. Commun Monogr 85(1):140–156. https://doi.org/10.1080/03637751.2017.1342043
Shumanov M, Johnson L (2021) Making conversations with chatbots more personalized. Comput Hum Behav. https://doi.org/10.1016/j.chb.2020.106627
Toader DC, Boca G, Toader R, Macelaru M, Toader C, Ighian D, Radulescu AT (2020) The effect of social presence and chatbot errors on trust. Sustainability 12(1):256. https://doi.org/10.3390/su12010256
Van der Goot MJ, Hafkamp L, Dankfort Z (2021) Customer service chatbots: a qualitative interview study into the communication journey of customers. In: Følstad A et al (eds) Conversations 2020 (LNCS), vol 12604. Springer, Cham, pp 190–204
Van Dis EAM, Bollen J, Zuidema W, Van Rooij R, Bockting CL (2023) ChatGPT: five priorities for research. Nature 614(7947):224–226. https://doi.org/10.1038/d41586-023-00288-7
Verhagen T, van Nes J, Feldberg F, van Dolen W (2014) Virtual customer service agents: using social presence and personalization to shape online service encounters. J Comput-Mediat Commun 19(3):529–545. https://doi.org/10.1111/jcc4.12066
Wulf AJ, Seizov O (2022) “Please understand we cannot provide further information”: evaluating content and transparency of GDPR-mandated AI disclosures. AI Soc. https://doi.org/10.1007/s00146-022-01424-z
Youn S, Jin SV (2021) In A.I. we trust?” The effects of parasocial interaction and technopian versus luddite ideological views on chatbot-based customer relationship management in the emerging “feeling economy.” Comput Hum Behav. https://doi.org/10.1016/j.chb.2021.106721
Zalando (n.d.). Alle veelgestelde vragen [All frequently asked questions]. https://www.zalando.nl/faq/. Accessed 9 Jan 2023
Zarouali B, Makhortykh M, Bastian M, Araujo T (2021) Overcoming polarization with chatbot news? Investigating the impact of news content containing opposing views on agreement and credibility. Eur J Commun 36(1):53–68. https://doi.org/10.1177/0267323120940908
Zemčík T (2021) Failure of chatbot Tay was evil, ugliness and uselessness in its nature or do we judge it through cognitive shortcuts and biases? AI and Soc 36:361–367. https://doi.org/10.1007/s00146-020-01053-4
Funding
This work was supported by a thesis grant from the Digital Communication Methods Lab at the University of Amsterdam.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There are no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix: Scenario and script for the Chatbot interactions
Scenario
Please read the scenario carefully as you will need the information for subsequent conversation:
You ordered a pizza through a new delivery service Yummy to Eat that has just been introduced in your town a few days ago. However, the delivery service not only was delayed by 30 min and as a result, your pizza arrived cold, but you also received a different pizza than you actually ordered.
You decide to chat with Yummy to Eat online customer service to fill out a complaint about the order. You will need following information to report your complaint to a customer care representative that will be assigned to you when you start the chat:
Name of the restaurant: Pizza Palace.
Date and time of the order: May 2nd, 19:15.
Order number: 2248349373.
You can begin the chat by typing “hi”. The customer care representative will ask you for your participant ID. You can find the participant ID in the following line.
Script for the experimental study
Phrases in Italic were adjusted for the experimental study; underlined phrases were added for the experimental study.
ParticipantFootnote 2: hi.
Chatbot: Hi there! My name is (undisclosed: Sara from Yummy to Eat/ disclosed: Sara, a chatbot from Yummy to Eat) and I am here to assist you with your order. Before we start, could you please provide me with your participant ID?
Participant: It is X.
Chatbot: Great, thank you! Now, how can I help you?
Participant: I would like to fill out a complaint about my order.
Chatbot: Oh no, apologies for that. What was the name of the restaurant you ordered from?
Participant: Pizza Palace.
Chatbot: Thank you. And what date did you order?
Participant: May 2nd
Chatbot: Ok. I need one additional information to double check and to look the order up in our system. When did you place the order?
Participant: May2nd, 19:15.
Chatbot: Awesome. I see. It was an order number 2248349373. Is that right?
Participant: Yes.
Chatbot: Great, thanks for the confirmation. What I can do is to offer you a full refund for your order. If you agree, please type Yes. Then I can request the refund in our system.
Participant: Yes.
Chatbot. Perfect. Then it’s settled! Thanks for chatting with me and again, apologies for the inconvenience with your order. This conversation is now closed. You can now continue with the interview. Please click on the arrow below to proceed.
Participant: Bye
Chatbot: Bye
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
van der Goot, M.J., Koubayová, N. & van Reijmersdal, E.A. Understanding users’ responses to disclosed vs. undisclosed customer service chatbots: a mixed methods study. AI & Soc (2024). https://doi.org/10.1007/s00146-023-01818-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00146-023-01818-7